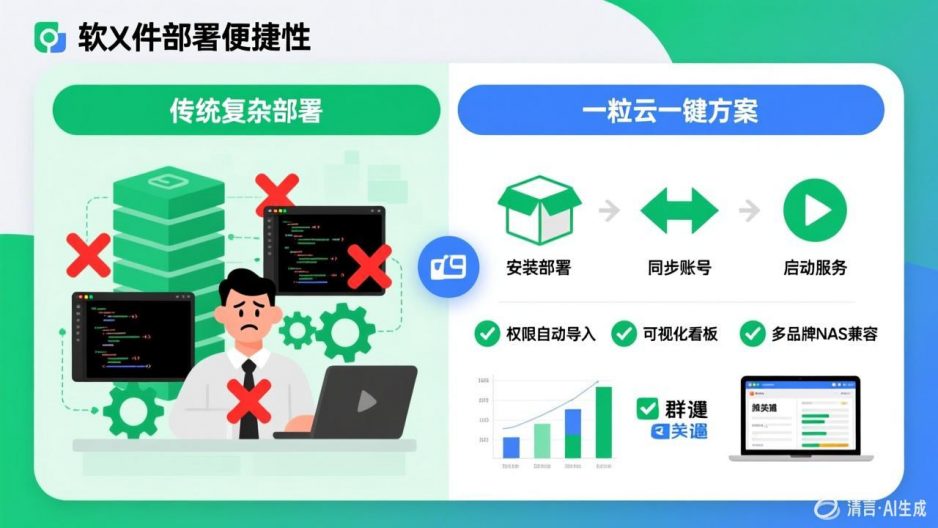
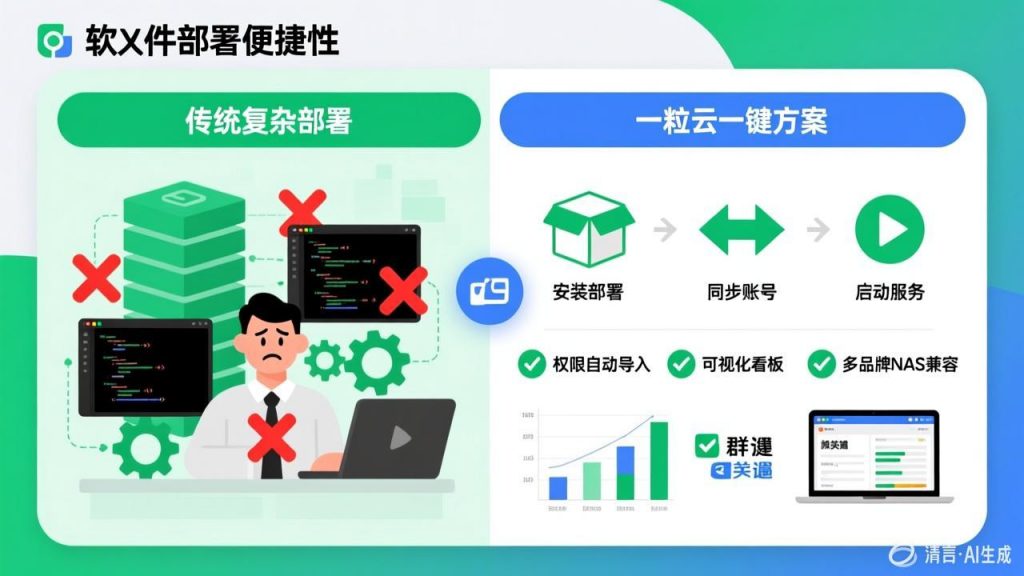
面向读者:企业主
主推方案:非结构化文件治理中台 + 智能文档云 + AI知识库
联动品牌:群晖 NAS
现有公开资料显示,一粒云成立于 2015 年,70%+ 为研发人员,全国拥有 20+ 区域分销渠道,服务 2000+ 中大型企业,并公开标注 100% 成功交付率。典型材料中还出现了 500+300TB、5000 用户 / 30T 文件 / 5 个交换节点 等落地规模。
很多老板最近几年都做了同一件事。
买 NAS。
扩硬盘。
做备份。
把公司资料慢慢搬进去。
这件事本身没错。
错的是,很多企业做到这里就停了。
结果就是一个很反直觉的现实:
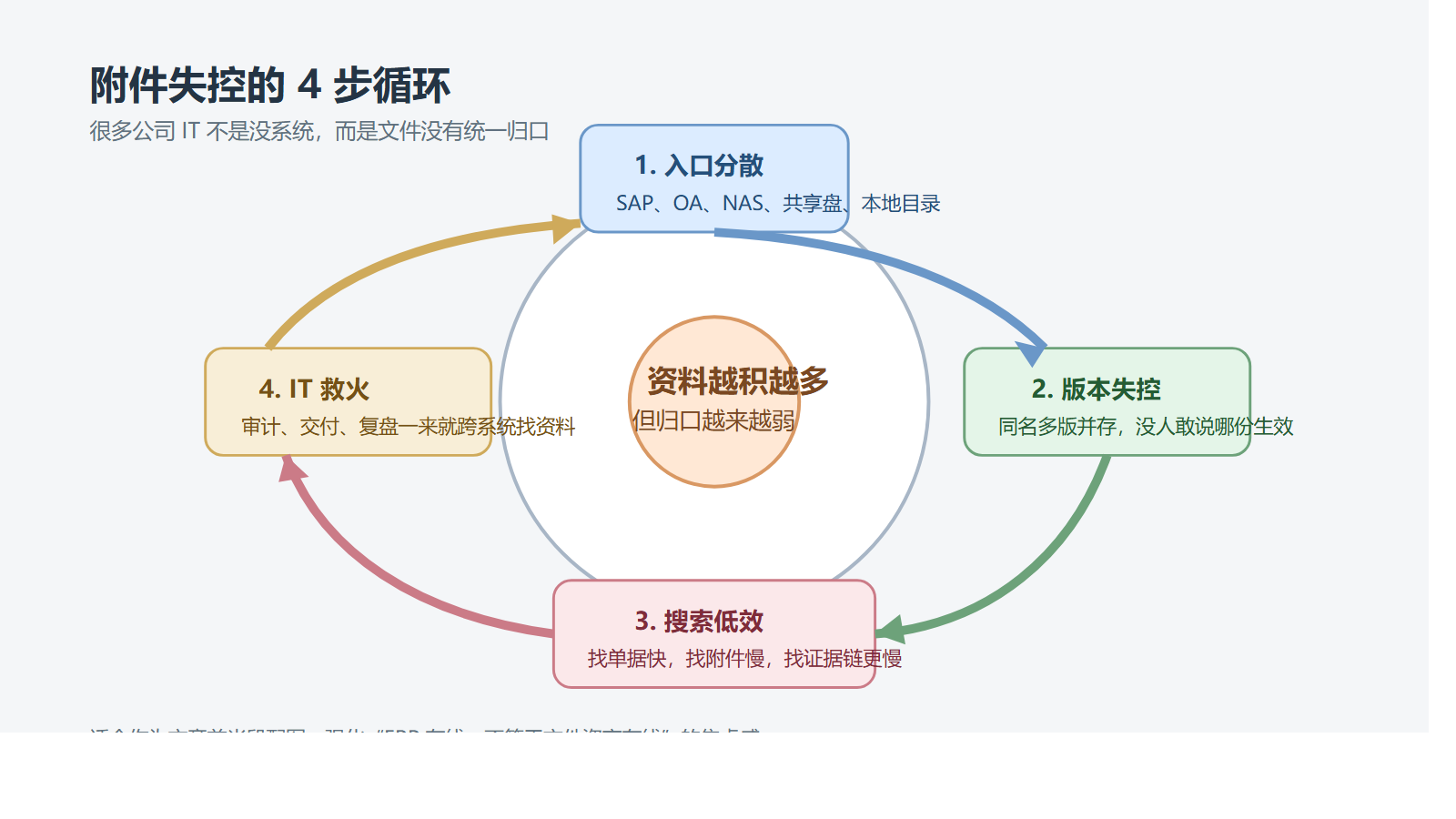
硬盘更多了,文件反而更难管了。
为什么?
因为老板补上的,只是“存储”。
企业真正缺的,却是“治理”。
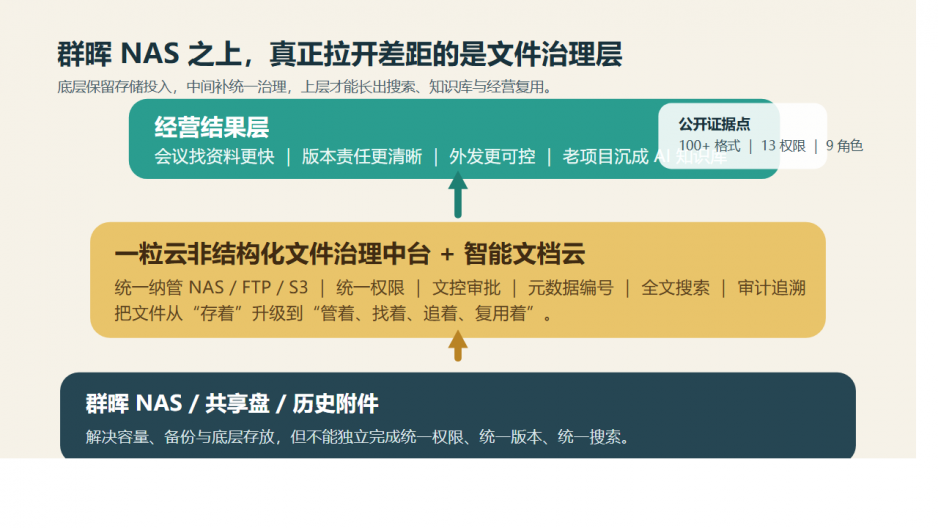
群晖 NAS 很适合做底层存储底座。
但企业一旦过了 50 人、100 人,或者开始多项目、多部门、多分子公司协同,文件问题就不再只是“有没有地方放”,而变成:
谁能看?谁改过?哪份是最新版?哪份能外发?老项目的经验为什么一直沉不下来?
如果这几个问题回答不了,NAS 就会从“效率工具”慢慢变成“更大的文件仓”。
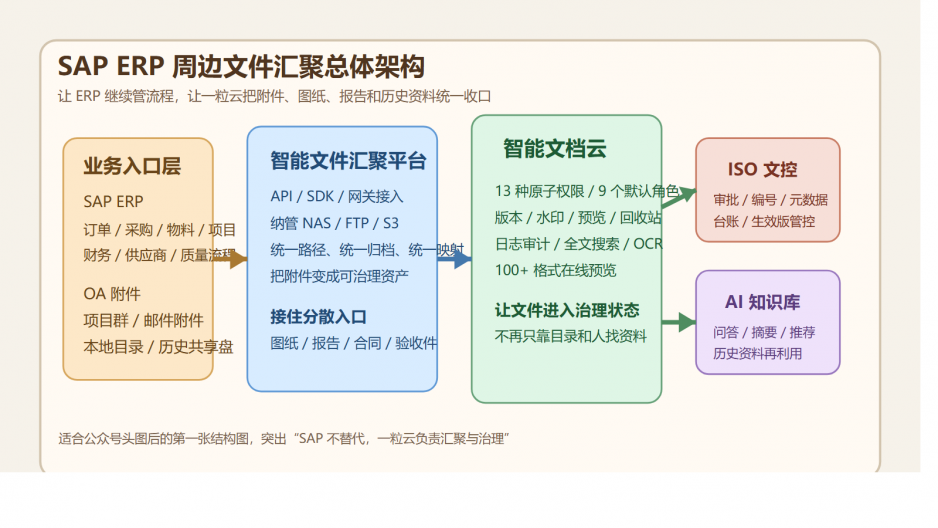
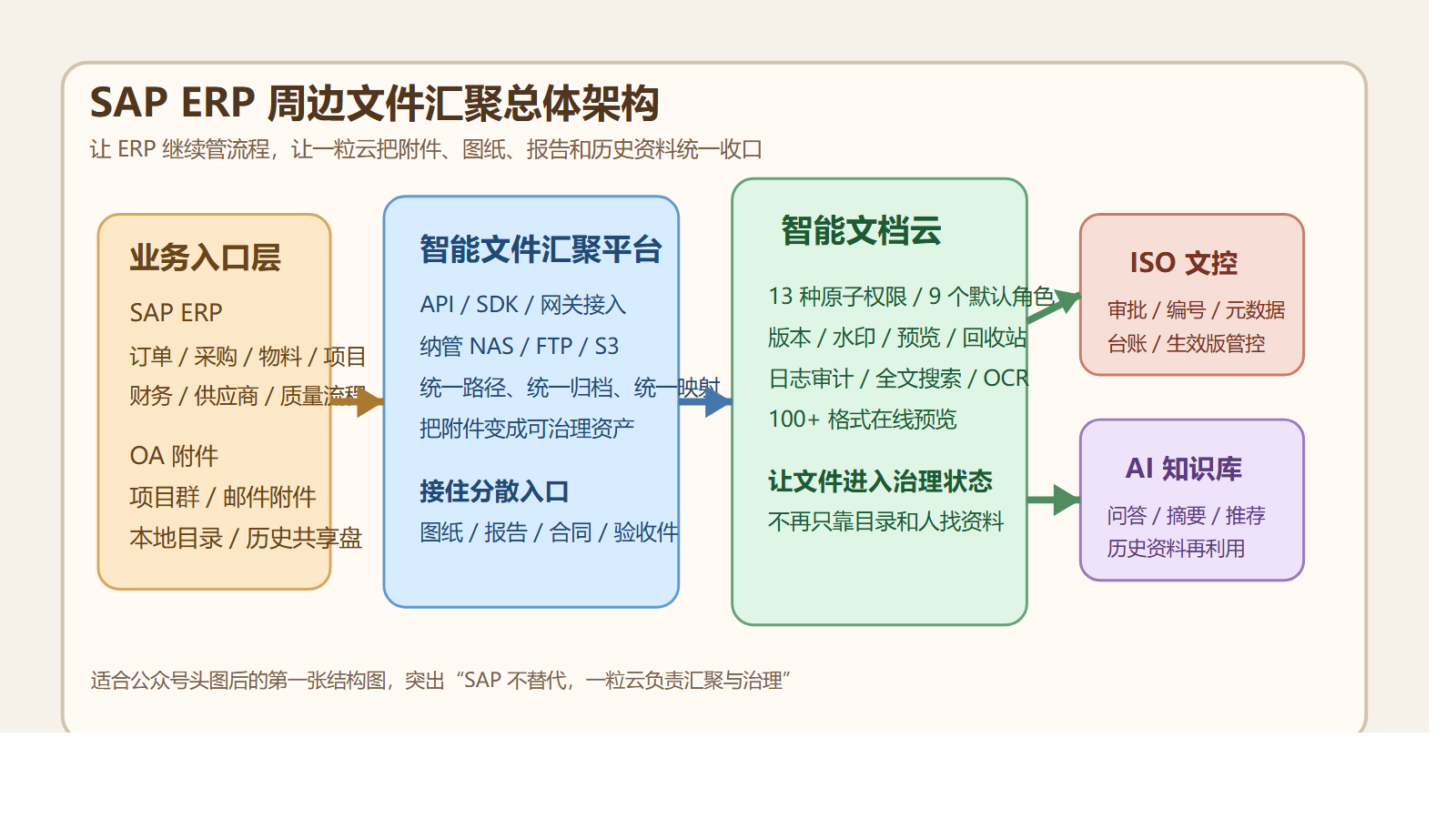
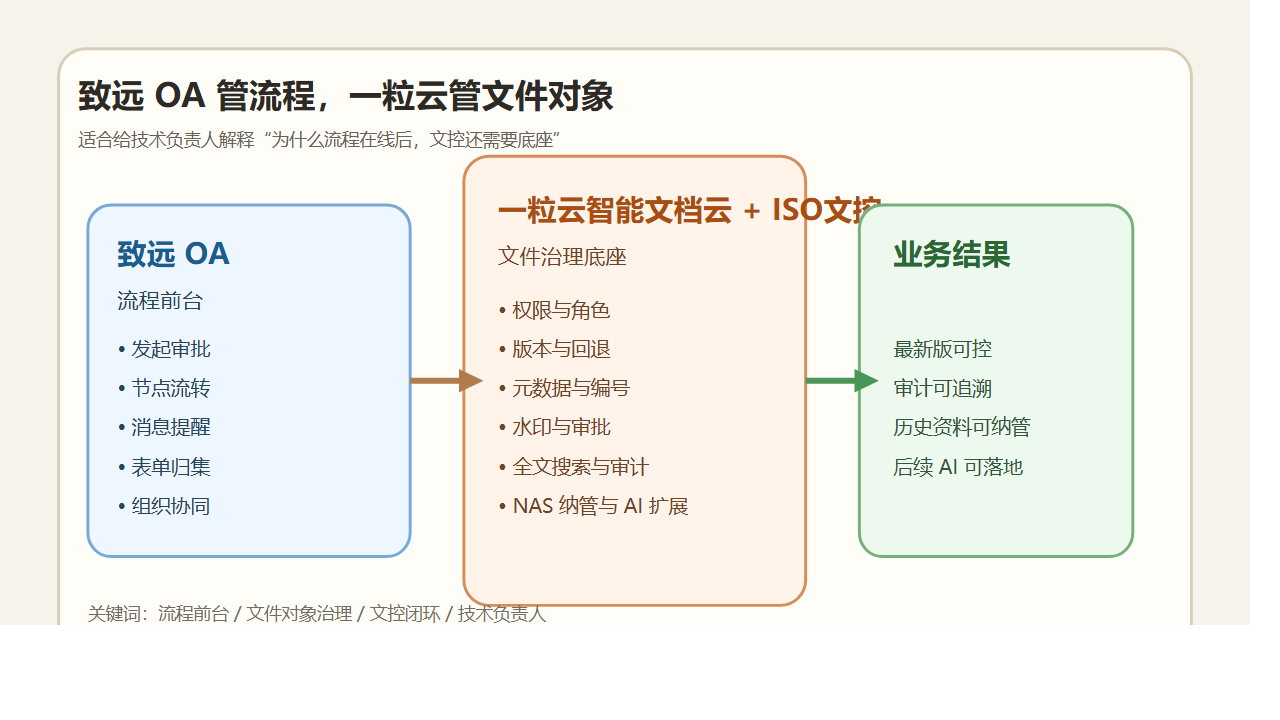
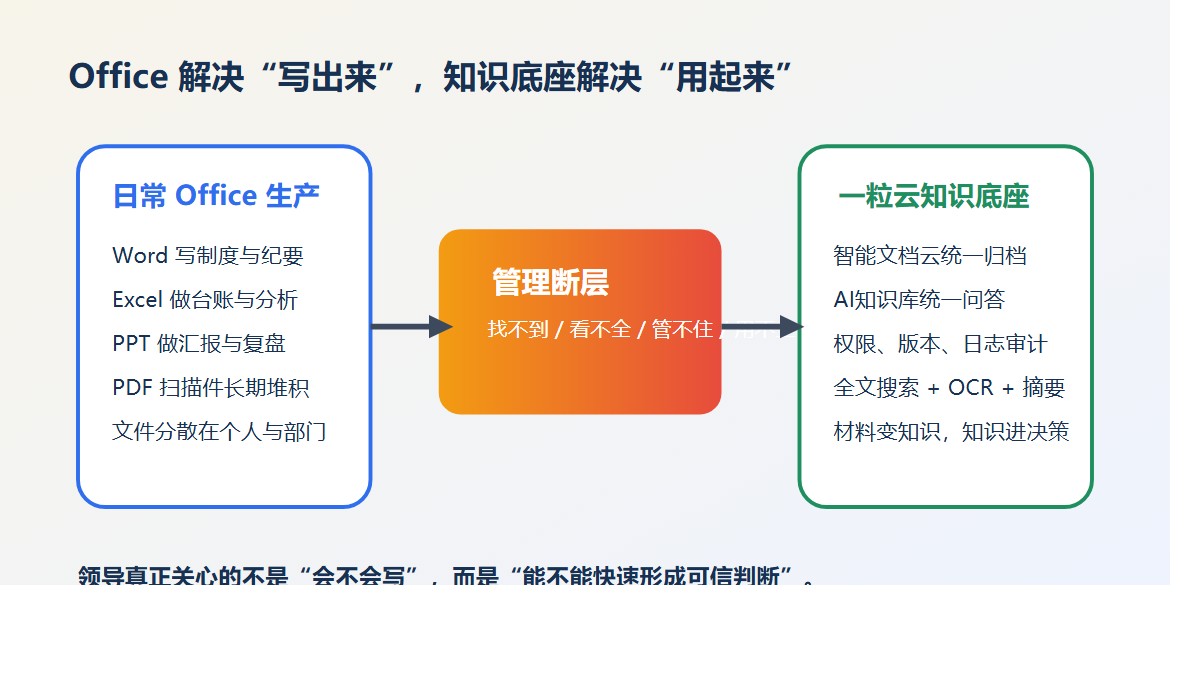
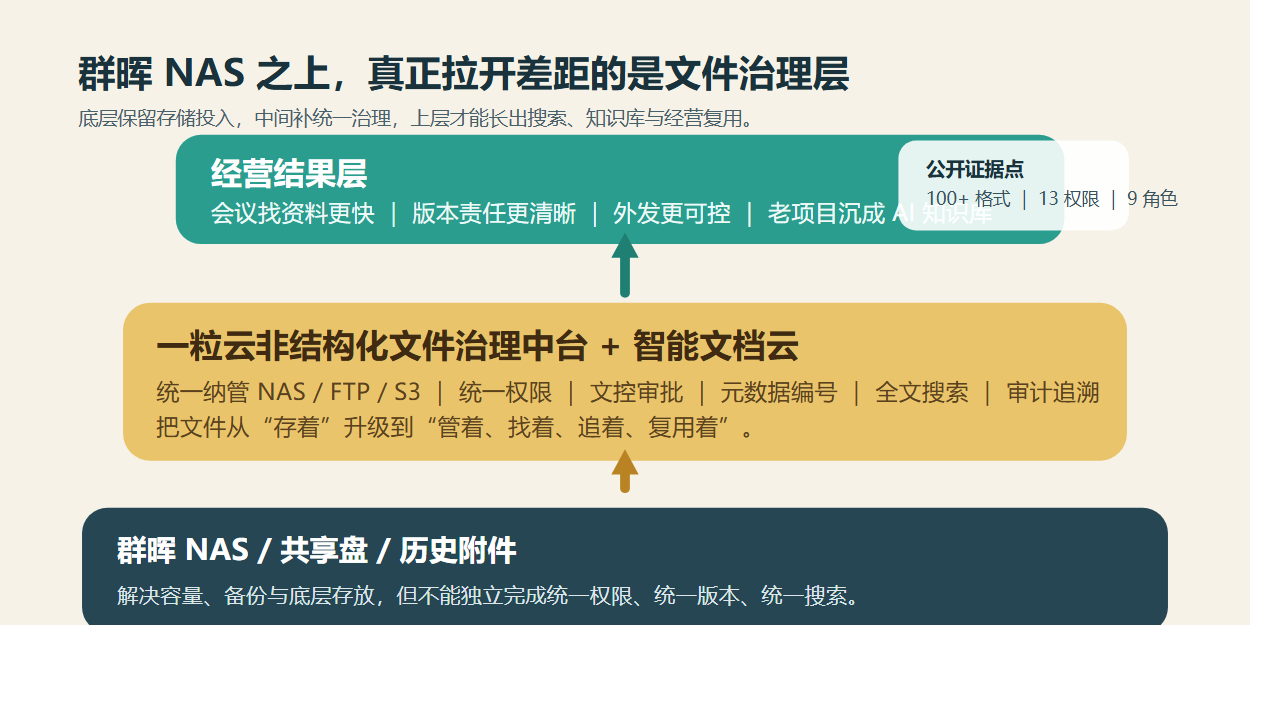
先说结论:老板最该补的,不是下一块硬盘,而是 NAS 上面那层治理中台
这就是为什么,越来越多企业在 NAS 之上,再补一层:
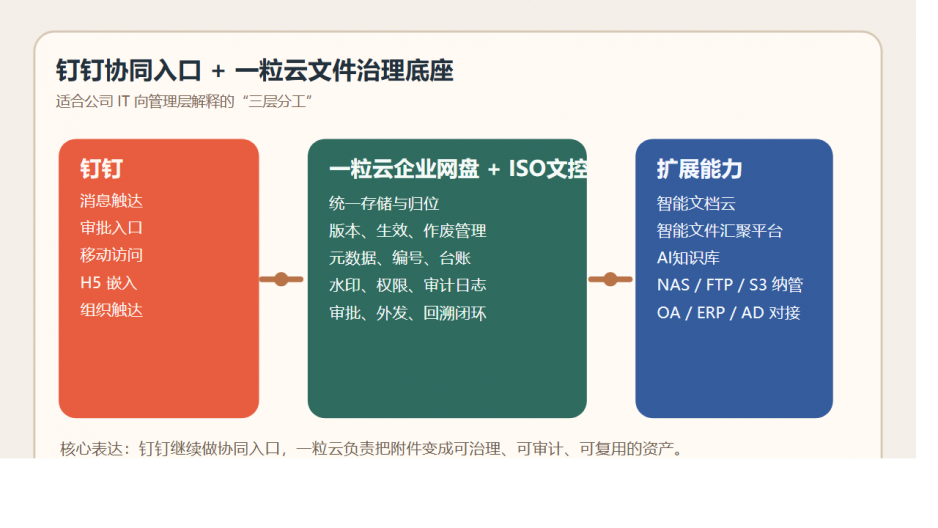
非结构化文件治理中台 + 智能文档云 + AI知识库。
它不是来替换群晖的。
而是把群晖里“已经存进去但还没管起来”的文件,真正变成企业资产。
简单说,群晖负责“存得住”。
一粒云负责“管得住、找得到、追得清、用得起来”。
这两者不是对立关系,而是上下层关系。
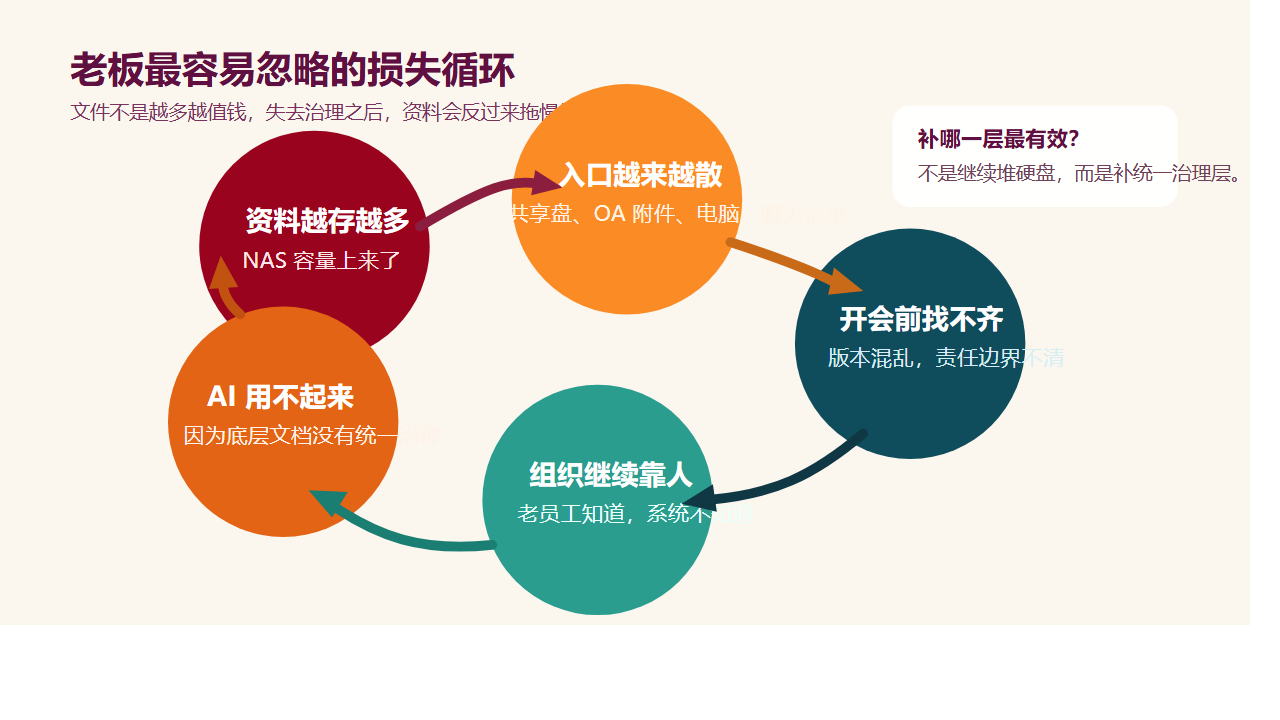
为什么很多企业买了 NAS,文件还是越存越乱?
老板通常会看到表面的进步:
- 文件集中了一些
- 备份放心了一些
- 大家至少知道有地方可放
但真正进入经营现场,问题还是会冒出来。
第一,入口越来越多,系统越来越多,真正的文件真相却越来越少
合同在共享盘。
图纸在 NAS。
制度在 OA 附件。
项目资料在员工电脑。
客户方案在微信、邮箱和聊天记录里。
每个地方都能存。
但没有一个地方能回答老板最关心的那个问题:
“现在这份资料,哪个版本才算准?”
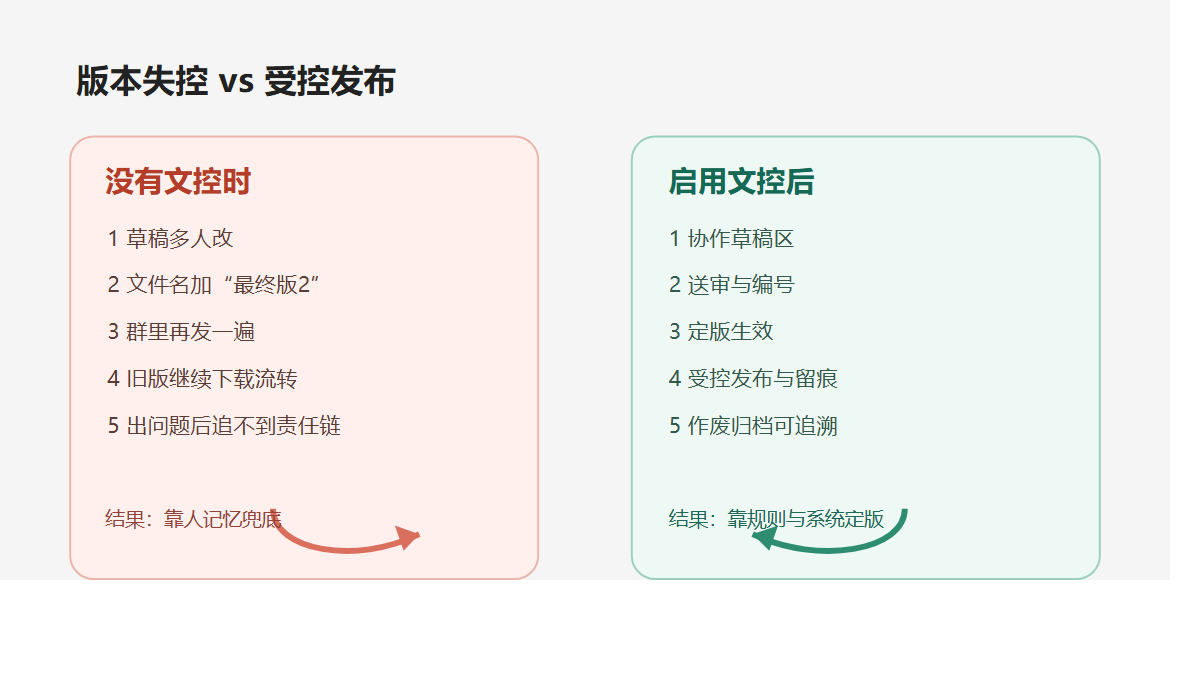
第二,能共享,不等于能受控
很多企业的文件不是不能传,而是不敢传。
外发以后谁看过?
下载以后有没有继续转发?
是不是应该先审批?
有没有留痕?
如果出了问题,能不能倒查责任?
一旦这些问题靠“群里说一声”“口头提醒一下”来维护,组织规模越大,风险越大。
第三,老资料越来越多,但搜索还停留在“按文件名找”
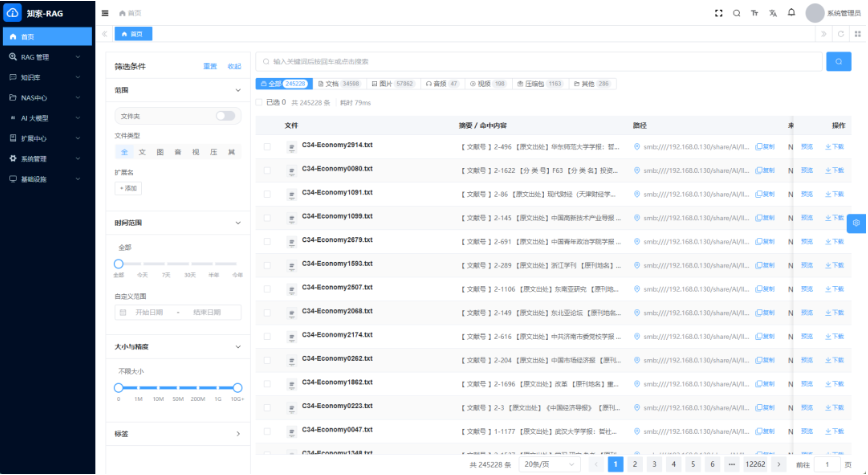
现有资料里,一粒云公开写到支持:
- 全文检索
- 标签搜索
- 文件内容搜索
- OCR 场景识别
- 中英混合搜索
- 高亮和分类统计
1 秒搜索千万文件
这件事对老板意味着什么?
意味着以后开会前找资料,不是继续靠“问最懂的人”,而是系统能直接按内容、主题、编号、标签、时间把结果拉出来。
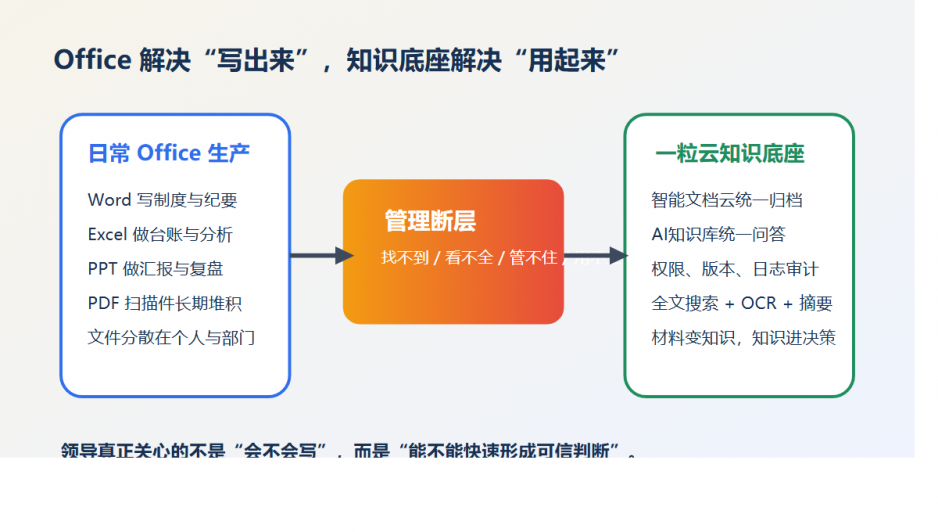
第四,买的是存储,丢掉的却是知识复用能力
很多老板真正焦虑的,不是资料没存下来。
而是资料虽然存下来了,却没有变成下一次可以直接复用的经验。
老项目结束,文件留在 NAS。
新人接手,又从头来一遍。
同样的问题,第二年还在重复犯。
这不是执行问题。
这是文件只被“保存”了,却没有被“治理”和“知识化”。
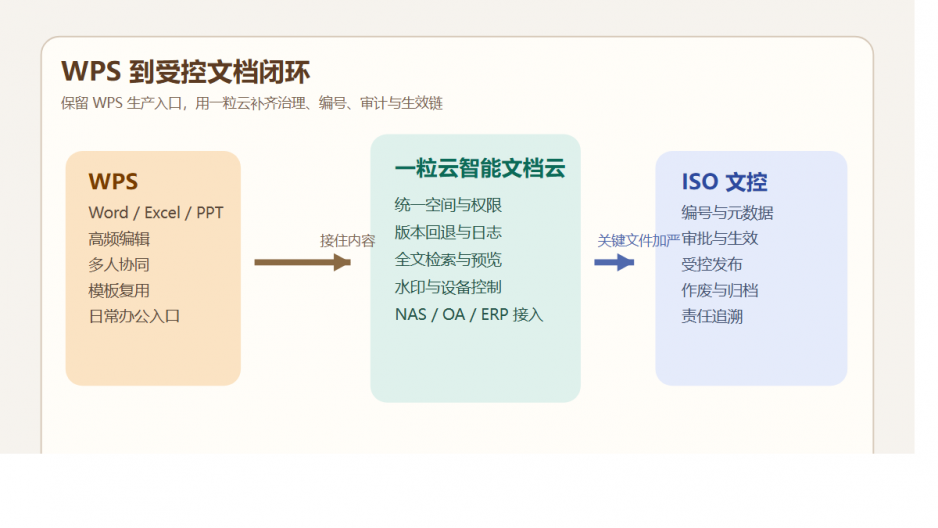
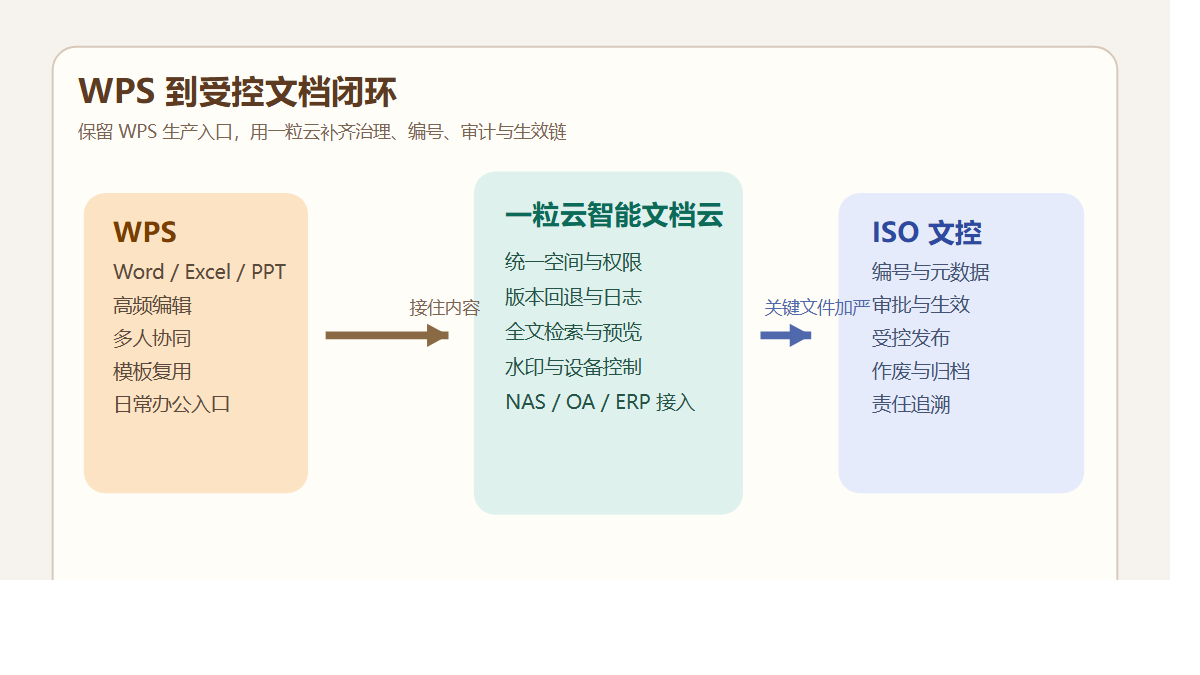
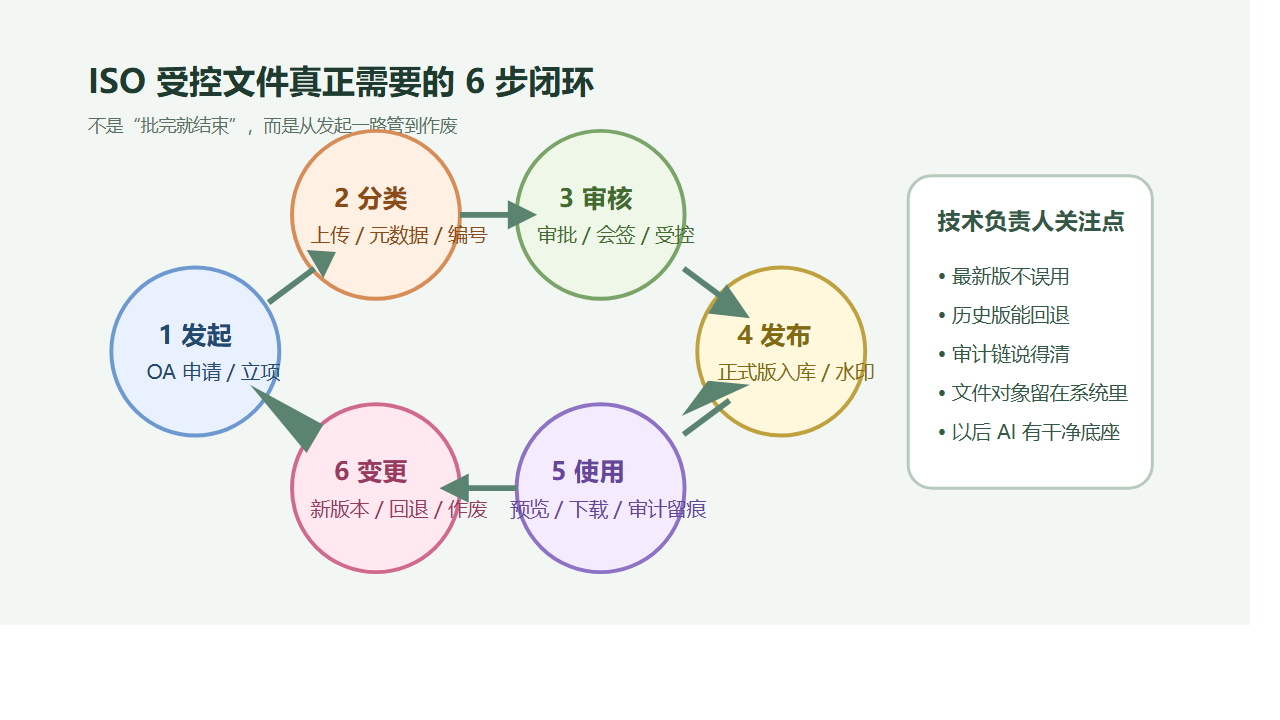
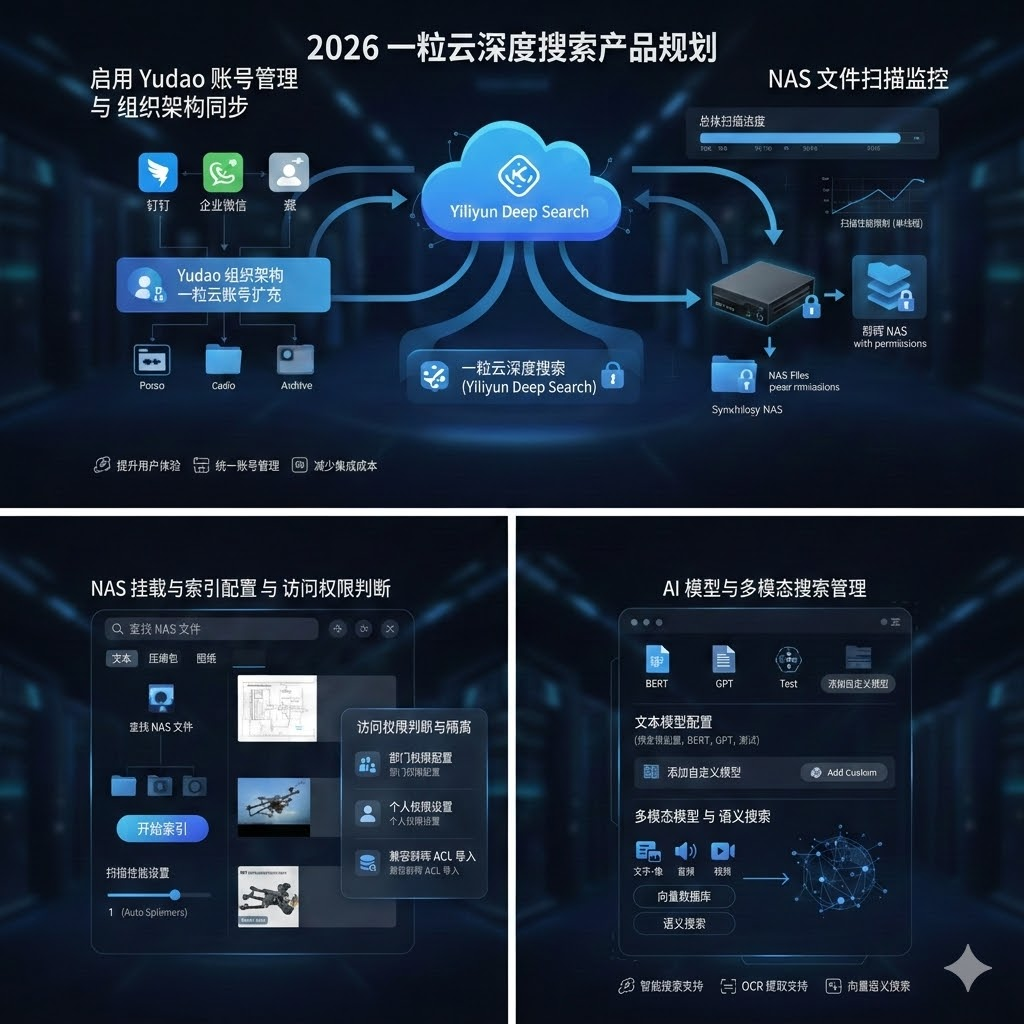
一粒云这层治理中台,到底补上了什么?
如果只看功能表,很容易把它理解成“另一个网盘”。
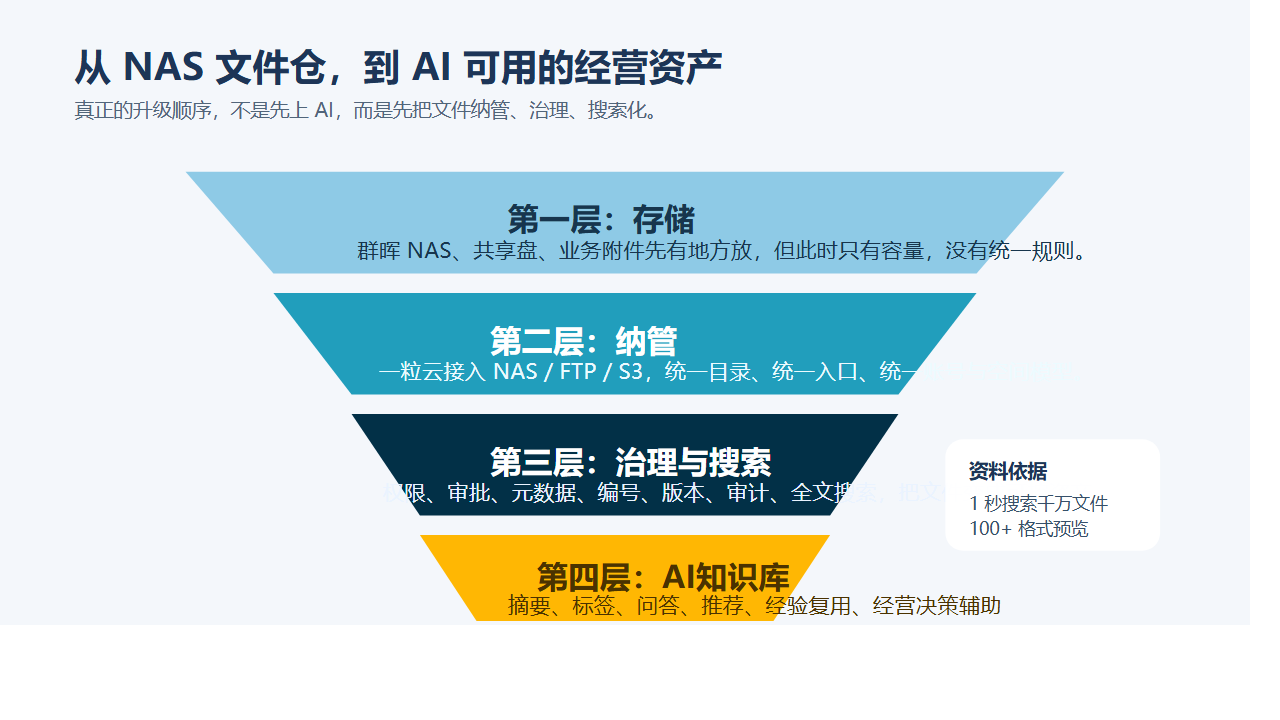
但从现有资料看,它更准确的定位,是一层建在 NAS 之上的文件治理操作系统。
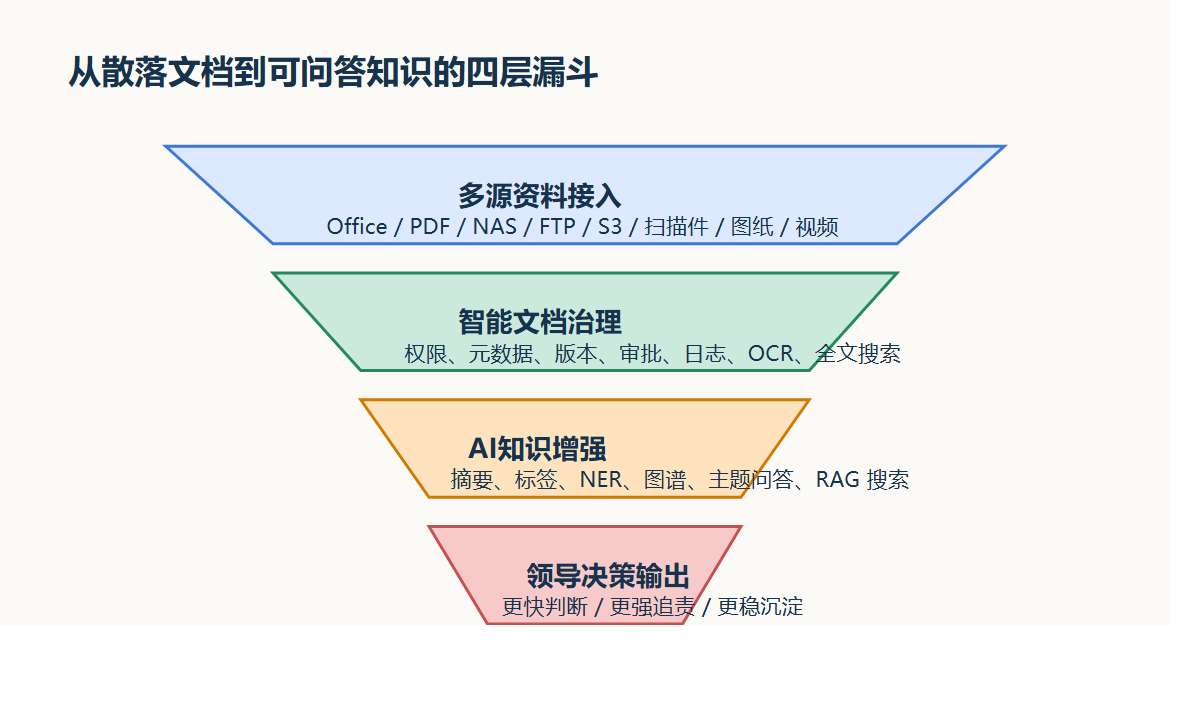
它做的不是简单搬文件,而是把分散文件统一纳进来,再加上规则。
1. 先纳管,不推翻原有 NAS 投入
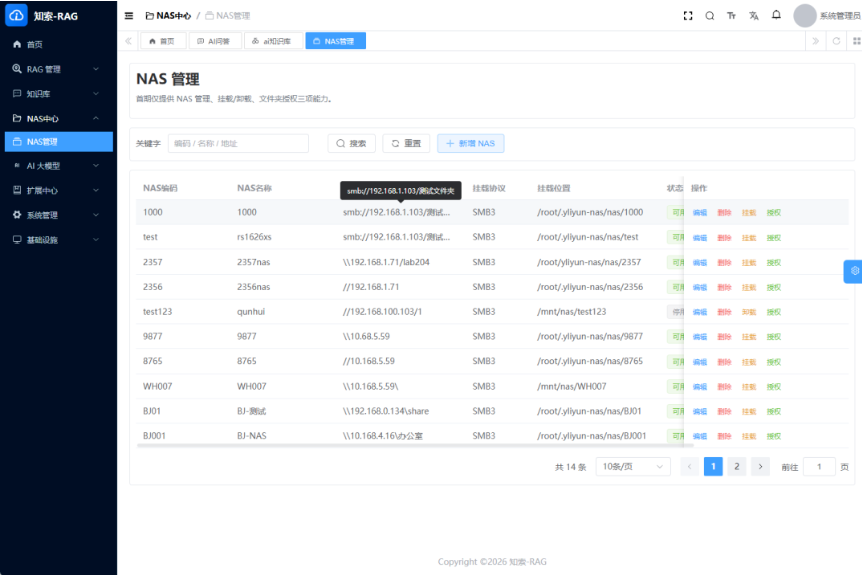
材料中明确写到支持 NAS / FTP / S3 挂载与纳管。
这意味着什么?
意味着企业不用一上来就推翻已有群晖环境。
原来的 NAS 继续做底层存储。
上面再接一粒云,统一入口、统一目录、统一账号、统一空间模型。
老板最怕的是“重复建设”。
这套路线的好处恰恰是:保留旧投入,补齐新能力。
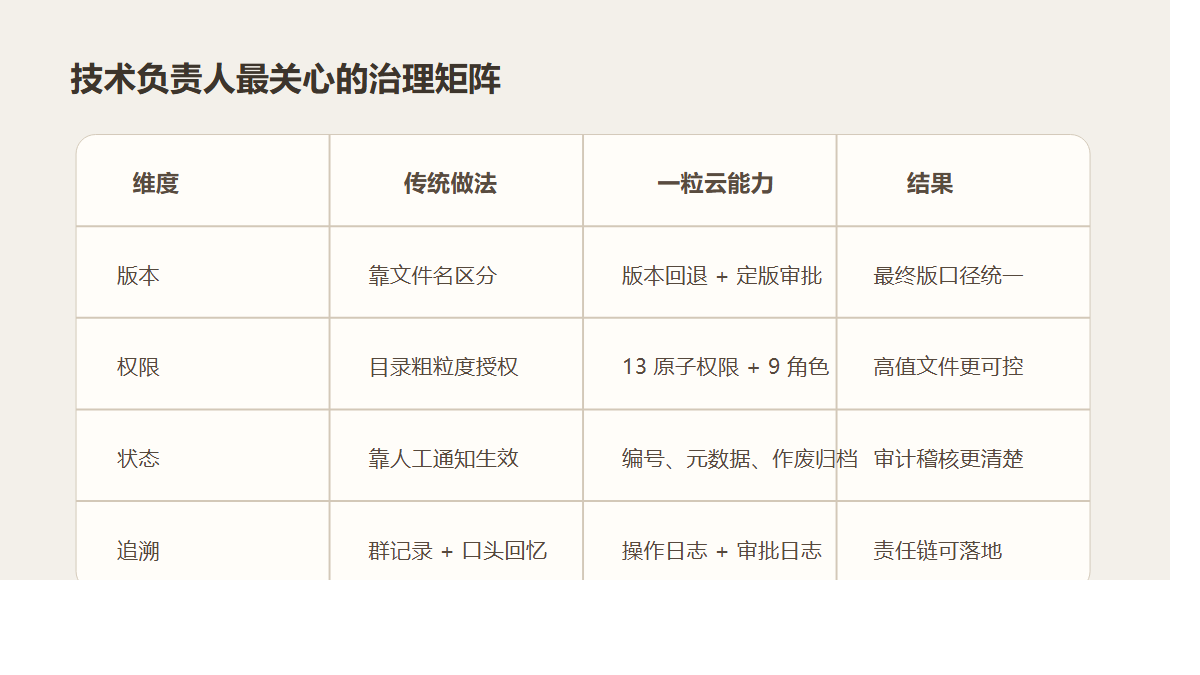
2. 再治理,把“谁能做什么”真正规则化
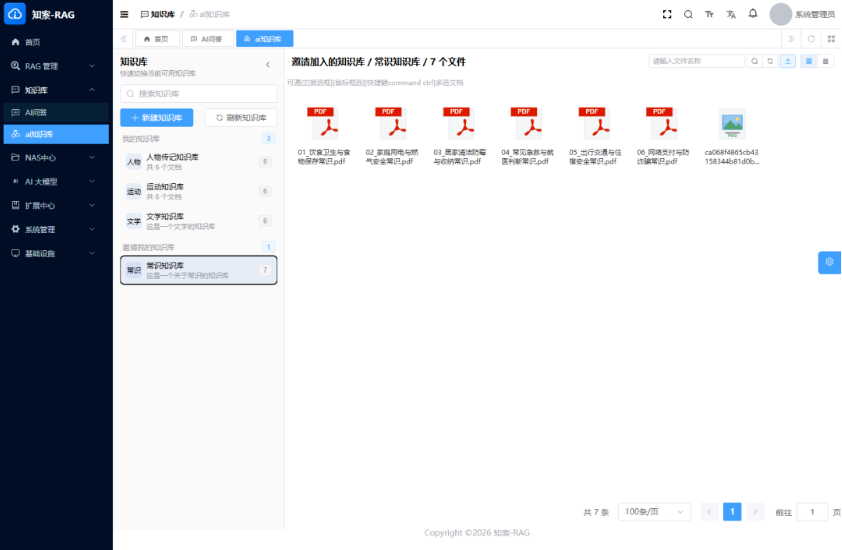
资料中公开写到支持 13 种原子权限、9 个默认角色,还支持个人空间、项目群空间、共享空间、部门空间等模型。
更关键的是,上传、下载、编辑、分享、删除、预览等动作都可以挂审批。
这意味着关键资料终于可以做到:
- 谁能看,系统说了算
- 谁能改,系统说了算
- 谁能外发,系统说了算
- 谁审批过,系统有记录
老板最关心的“责任边界”,这时候才真正开始成立。
3. 再搜索,把文件从仓库变成可调度资产
文件的价值,不取决于存了多少。
而取决于关键时刻能不能调出来。
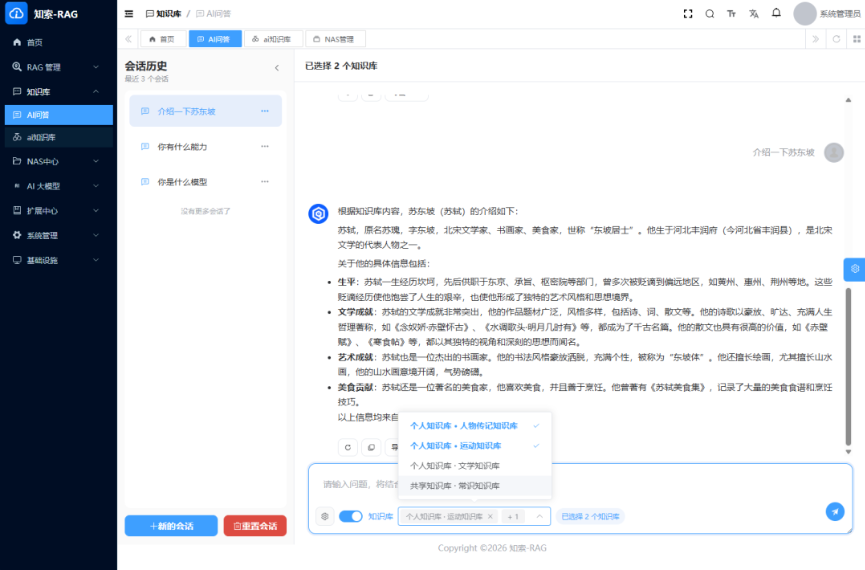
现有资料显示,一粒云除了传统检索,还支持摘要、标签、分类分级、NER、知识图谱和统一 RAG 搜索门户。
这一步非常关键。
因为它让搜索从“找文件名”,升级成“找内容、找关系、找答案”。
4. 最后知识化,让 AI 真正吃到企业自己的资料
很多企业主已经不缺 AI 概念了。
真正缺的是:AI 能不能吃到真实、干净、受控、可追溯的内部资料。
这恰恰是治理中台的意义。
没有统一入口,没有统一权限,没有版本和元数据,AI 只能做演示。
有了这些底层规则,AI知识库、知识问答、摘要推荐、制度对照、经验复盘才开始有真实价值。
为什么这个方案特别适合制造业、工程型企业和多分子公司企业?
因为这些企业的文件最容易“看起来都在,实际上都不在”。
比如制造业老板会非常熟悉这几类场景:
- 设计图纸在研发部
- 工艺文件在生产部
- 商务合同在销售或法务
- 交付资料在项目部
- 供应商往来文件在邮箱和聊天工具里
每一份资料都重要。
但每一份资料又都分散。
到了老板要看经营情况、项目进展、质量追溯、客诉处理的时候,组织就会暴露出两个问题:
第一,调资料慢。
大家都说“有”,但谁都不能立刻拿出“最新版”。
第二,责任不清。
出了问题以后,知道文件发生过变化,却很难快速追到哪个节点、哪个人、哪个版本。
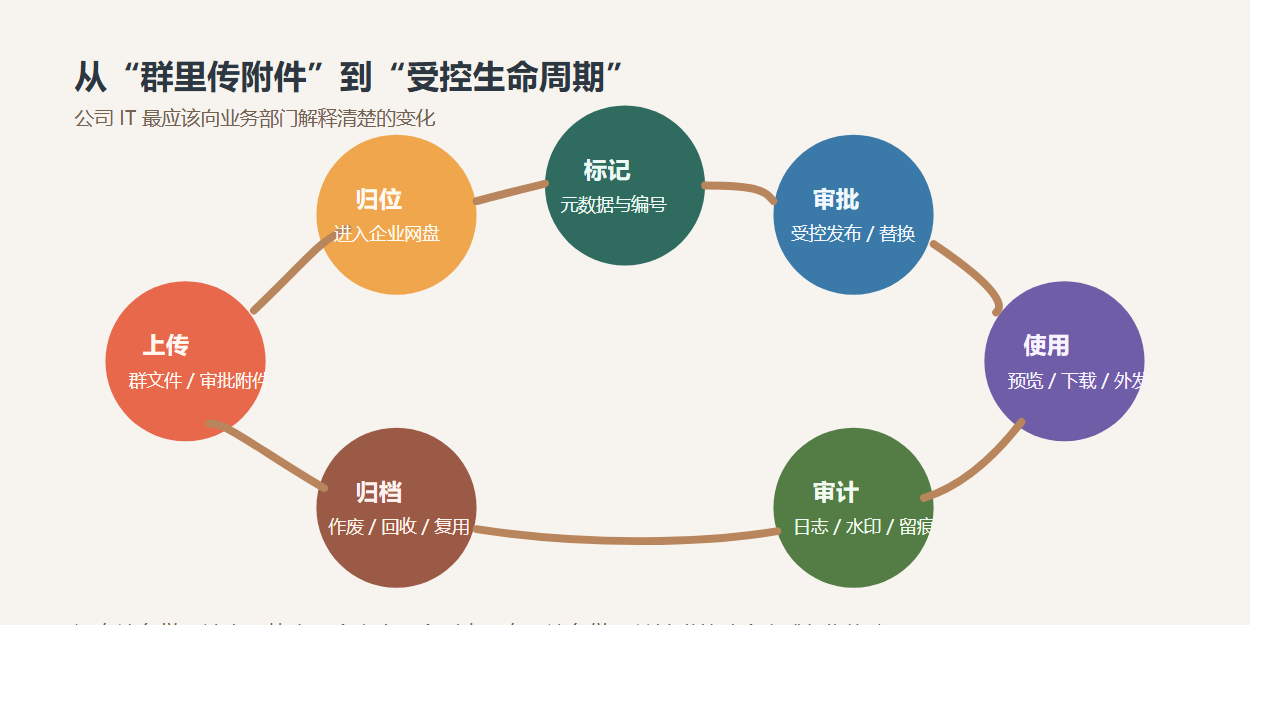
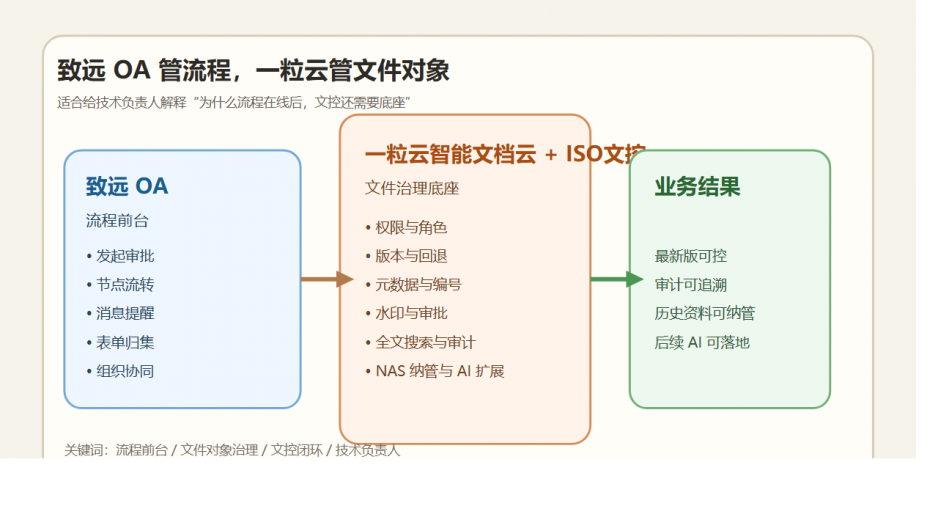
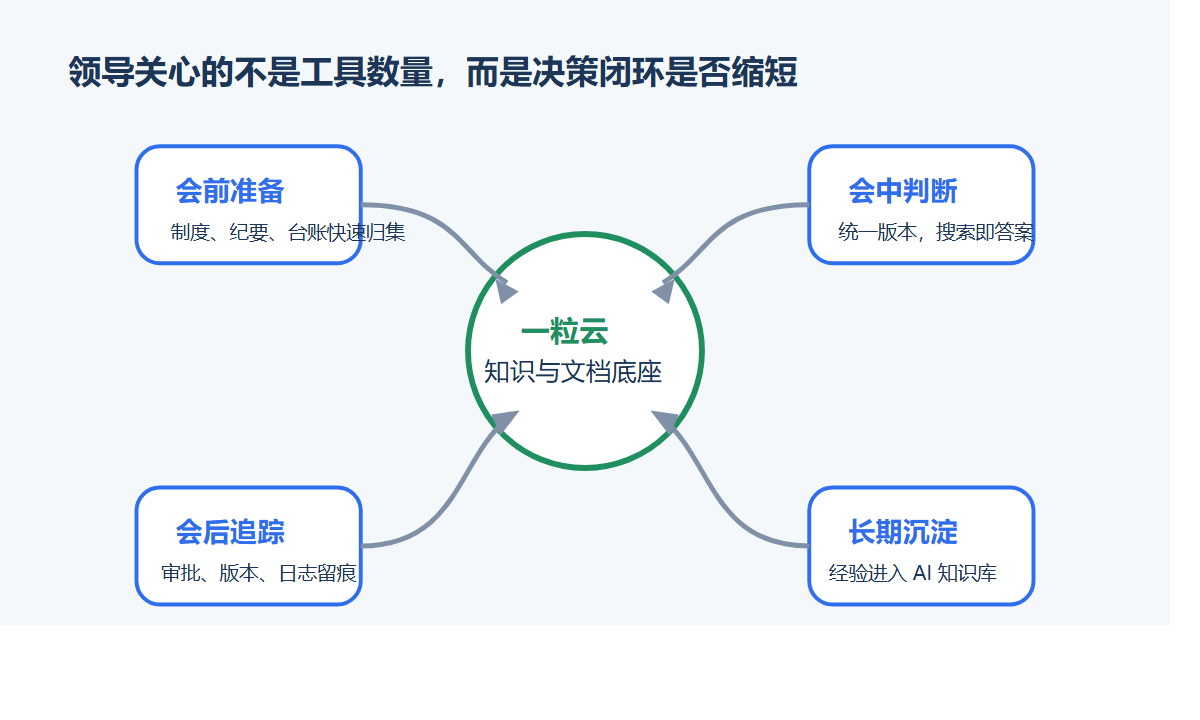
而一粒云的价值就在于,它不是只做一个展示层。
它把文档元数据、自动编号、版本链、审批链、访问记录、全文搜索和 AI 辅助阅读都连在一起。
对老板来说,这就不是“文件管理升级”这么简单了。
而是把原来最模糊、最依赖人的那一部分组织能力,开始交给系统。
公开案例和规模数据,为什么足够说明它不是纸上方案?
老板看方案,最怕两个词:概念化、理想化。
但现有公开材料里,至少有几组数据是有说服力的。
一组是容量规模。
华为电教云案例披露过 500+300TB 的有效存储空间。
一组是组织复杂度。
景嘉微场景披露过 5000 用户、30T 文件、1 个总部节点、5 个交换节点。
还有一组是研发协同复杂度。
信宇人案例中披露了 400 用户、150 研发,并出现 OA / AD / CAD 等协同要素。
这些数字至少说明一件事:
一粒云面对的不是“小团队共享网盘”场景。
它已经在多节点、多角色、多规则、多系统协同的环境里跑过。
还有一个老板往往不会主动问,但很重要的判断标准:本地服务能不能跟上
软件好不好,不只看功能。
还要看谁在本地持续服务。
公开资料显示,一粒云全国有 20+ 区域分销渠道。
从价格体系文件能看出,它的渠道合作空间大致在 30%~65%。
这组信息对老板的意义是什么?
不是让你去算利润。
而是说明这类产品更容易形成区域交付网络,本地服务商更有动力长期投入实施、培训、运维和二开联动。
换句话说,老板买的不是一套“装完就走”的软件。
而是一个更容易长期陪跑的服务体系。
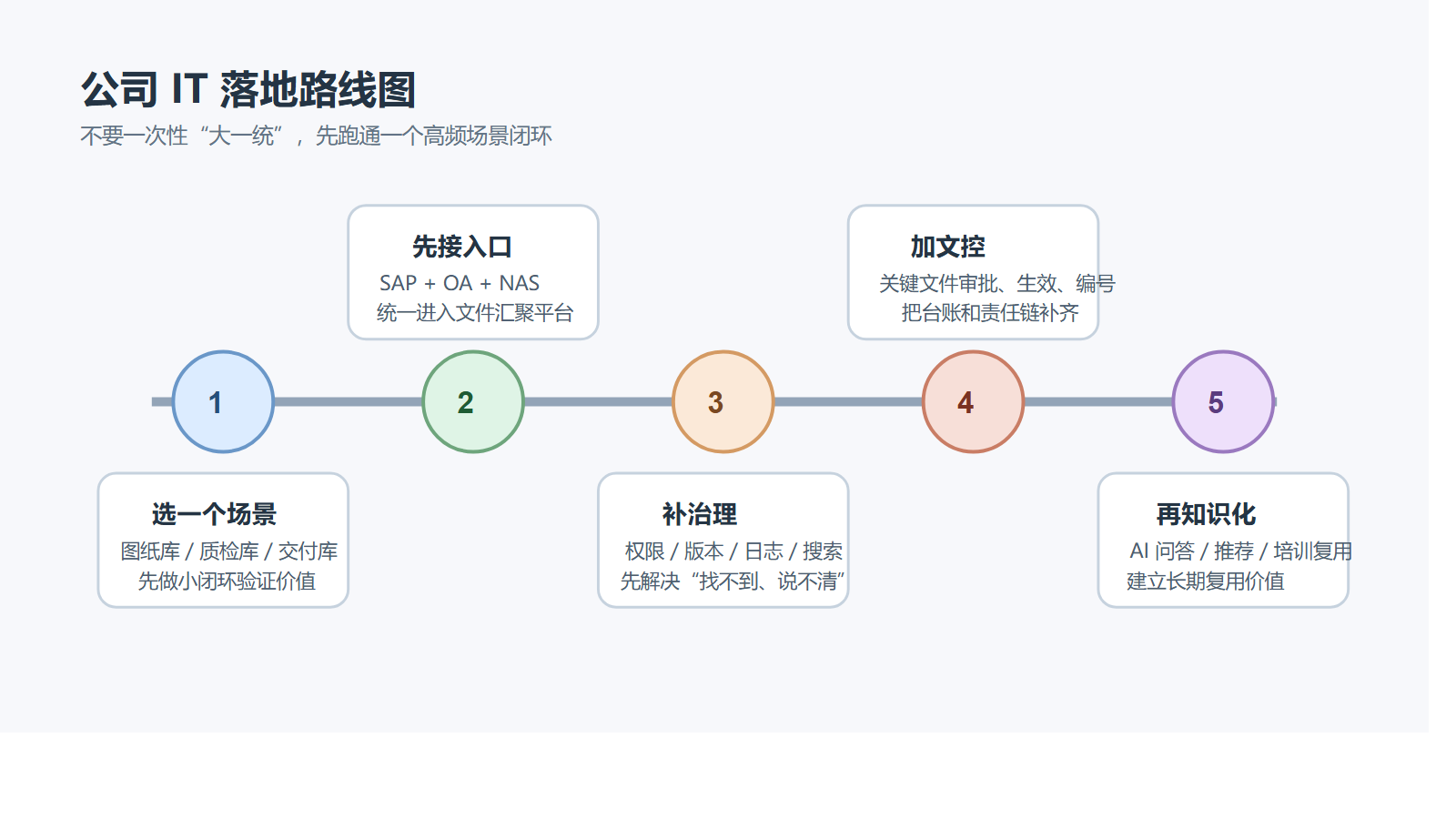
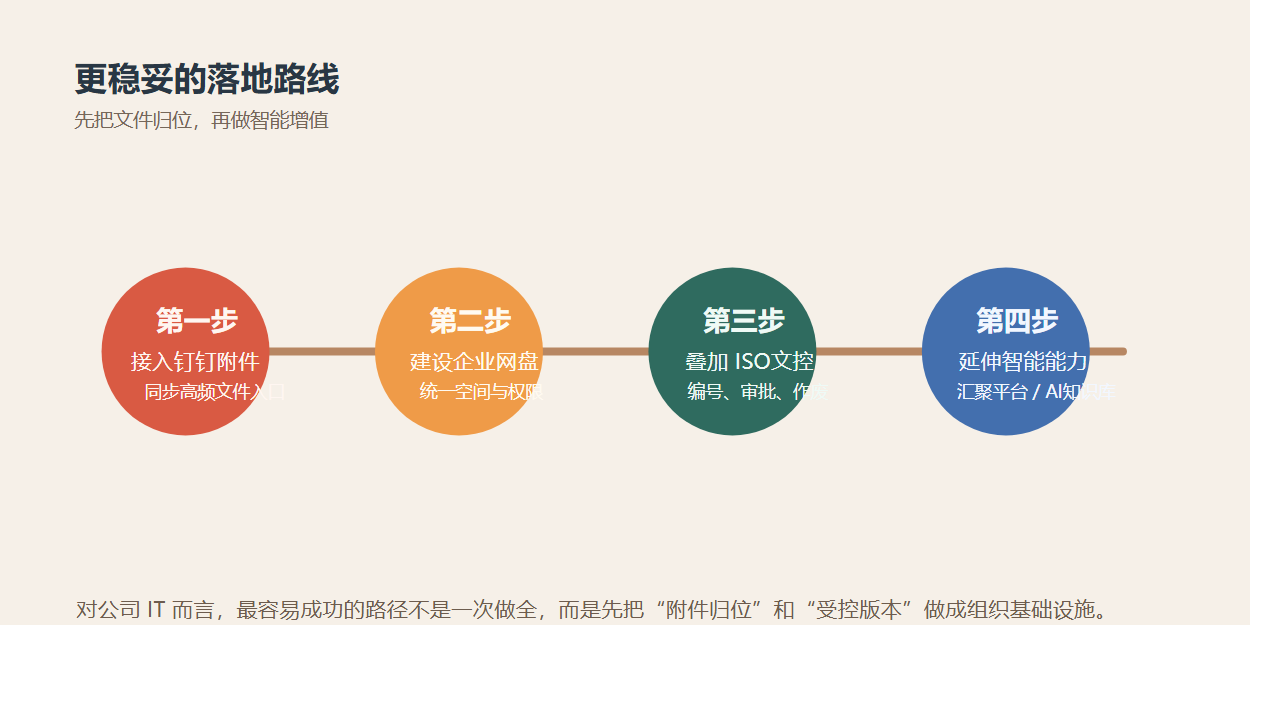
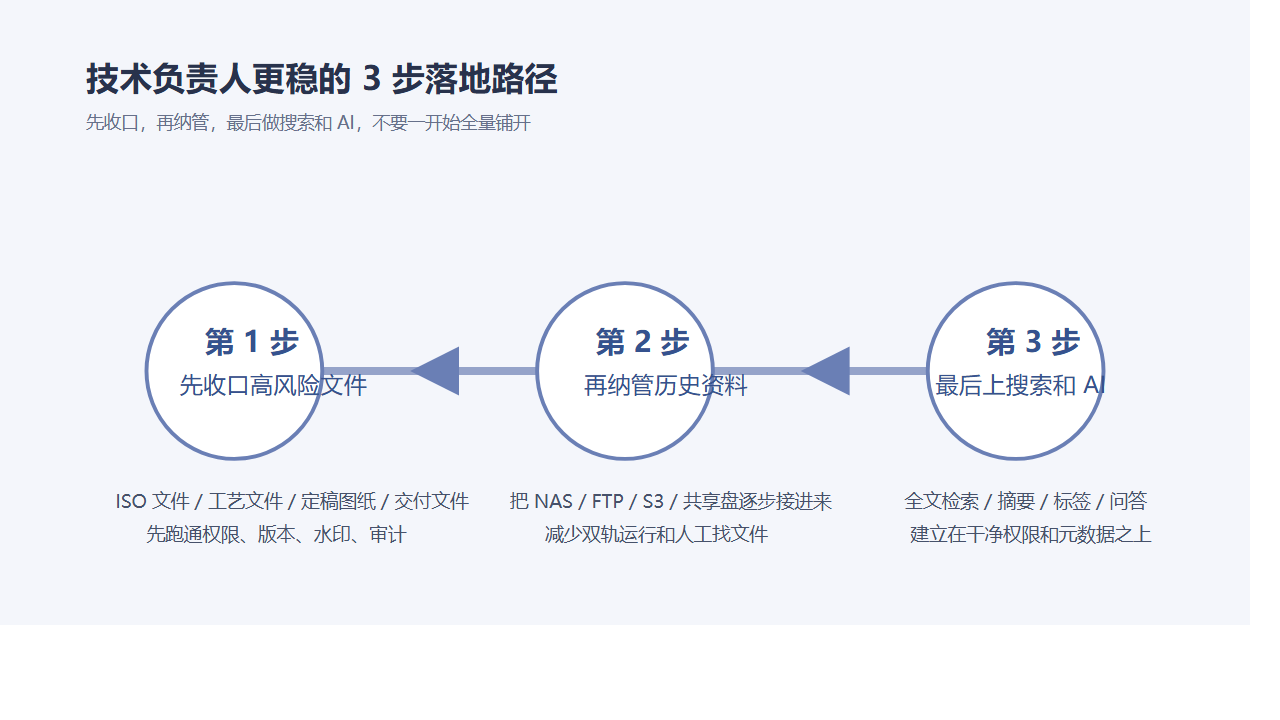
如果你现在已经有群晖,最现实的升级路径是什么?
不是推倒重来。
也不是一次上满所有模块。
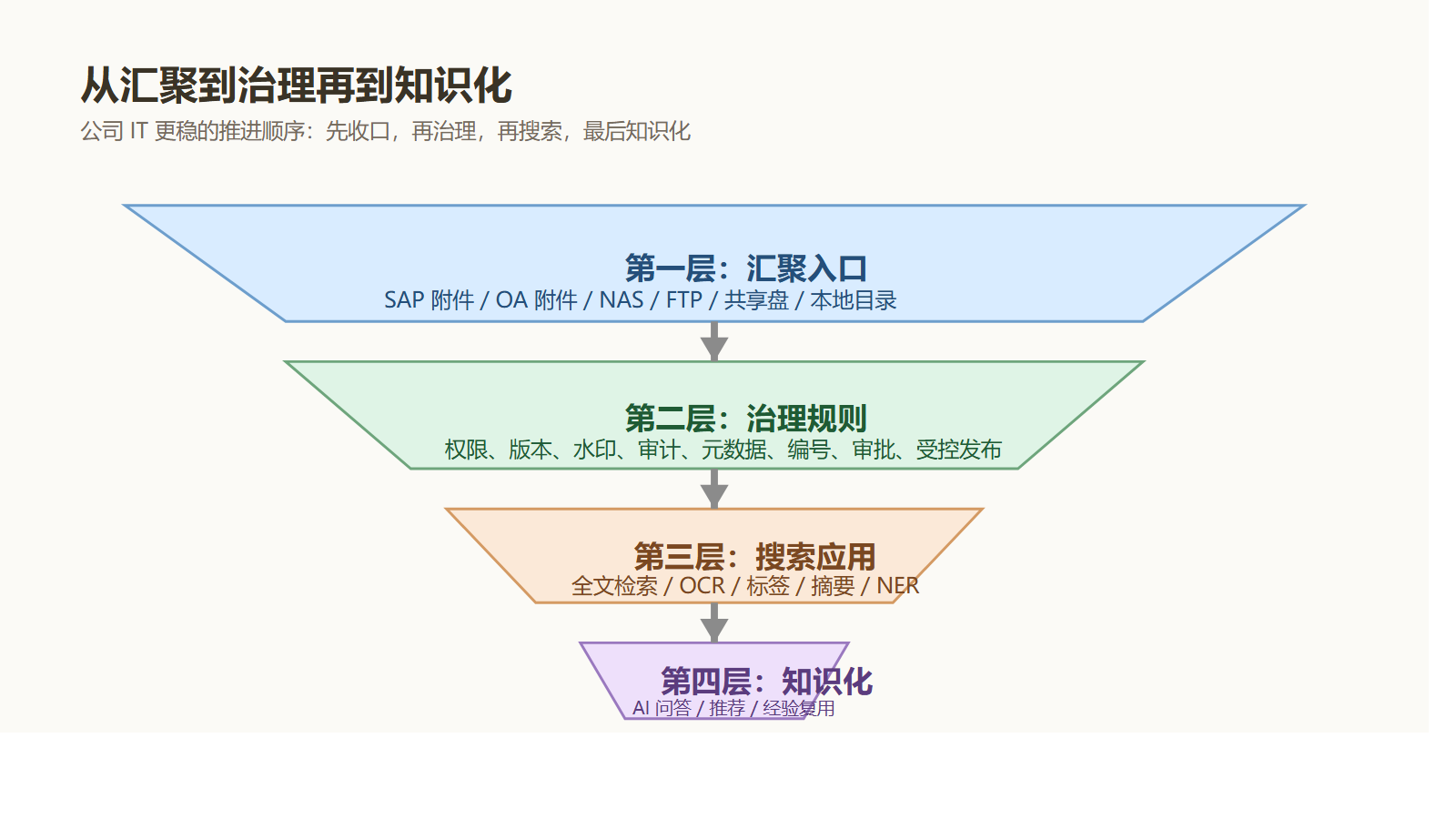
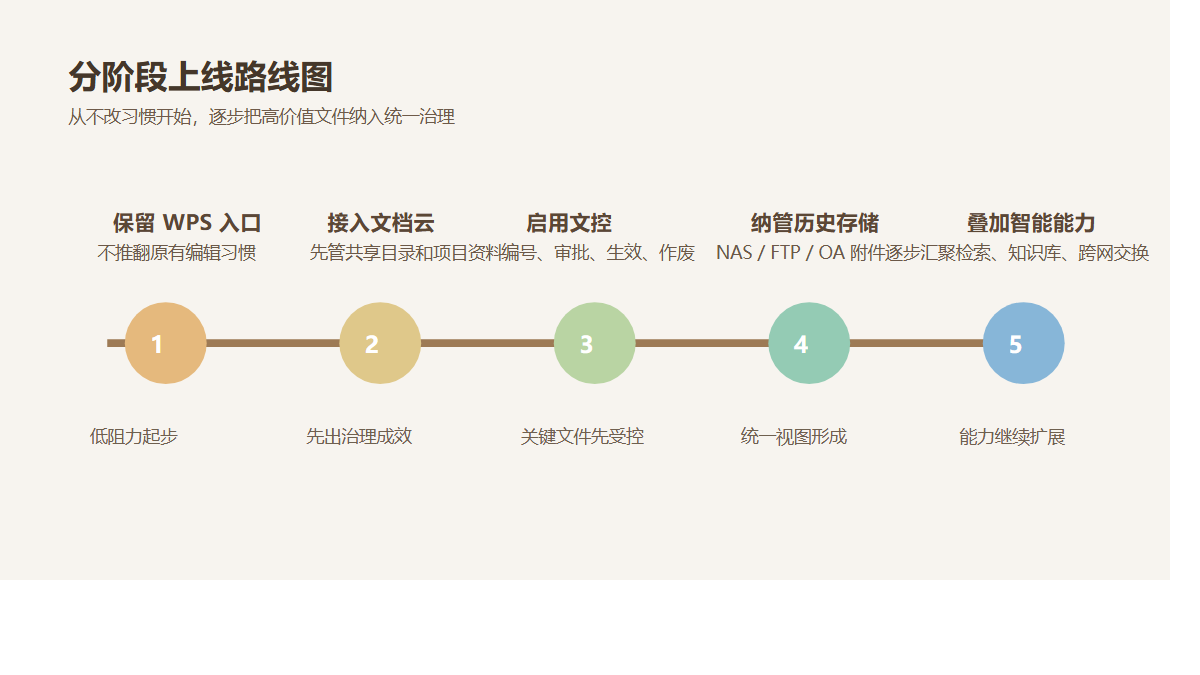
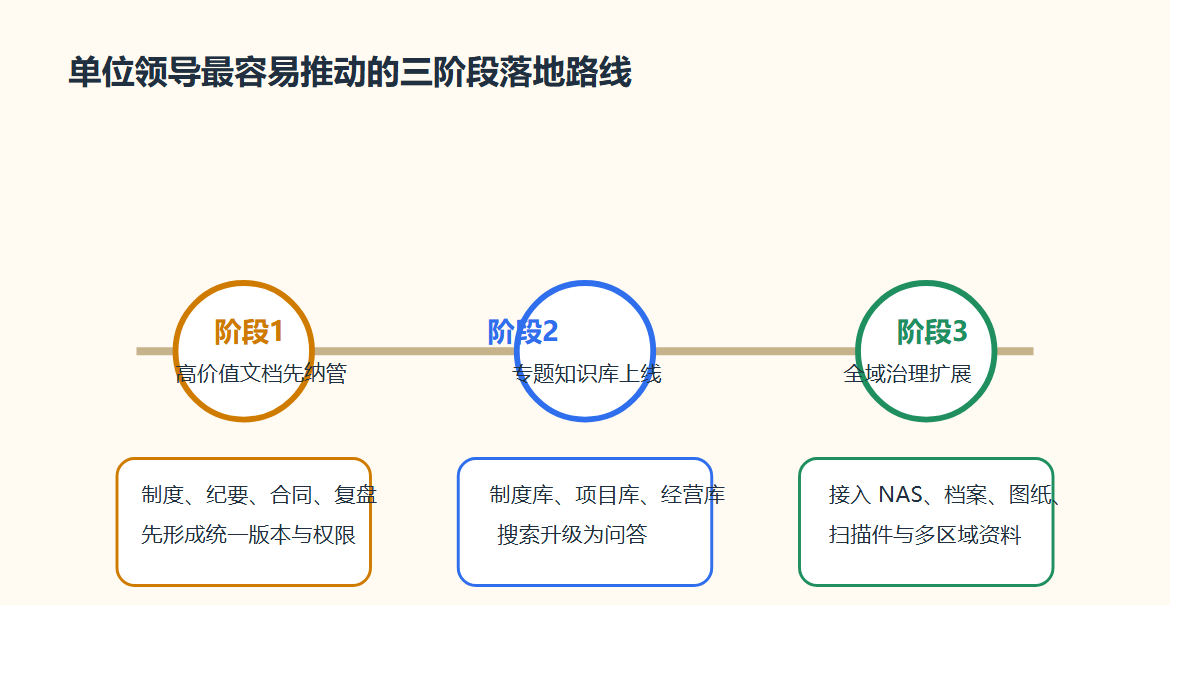
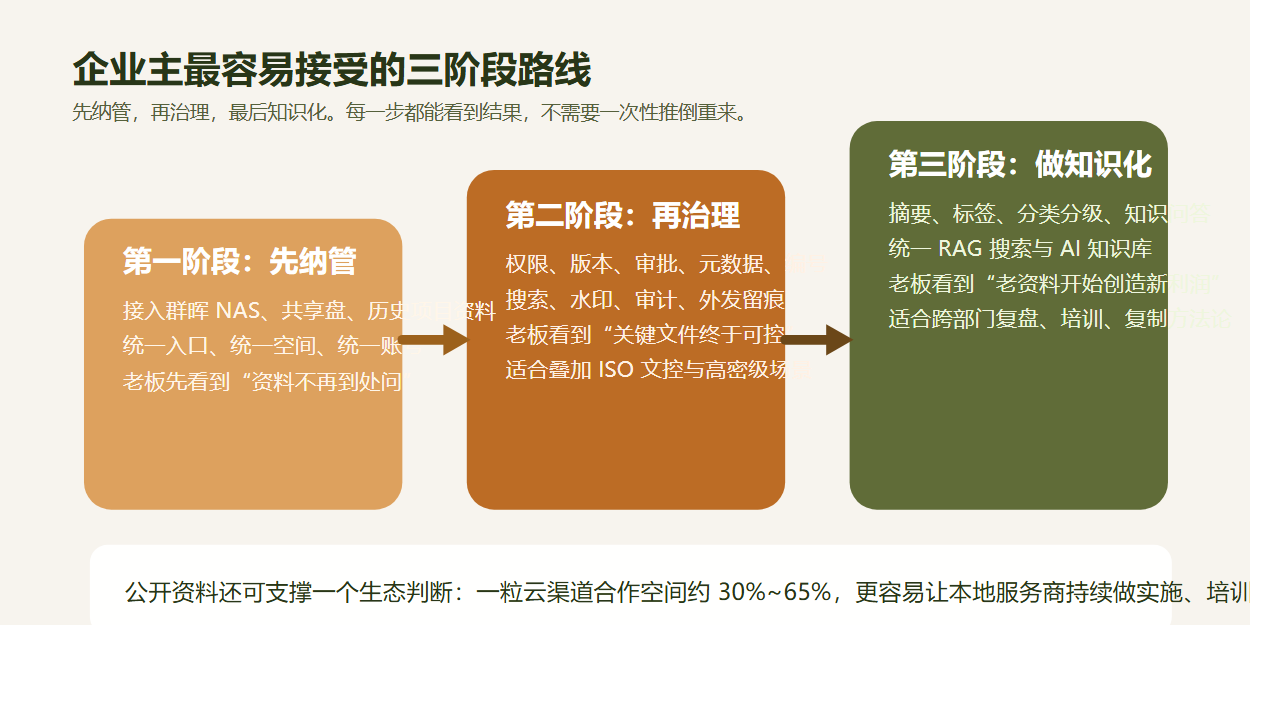
更现实的路线,通常分三步。
第一步,先纳管
先把群晖 NAS、共享盘、历史项目资料、关键业务附件接入统一入口。
先解决“资料别再到处问”。
第二步,再治理
把权限、版本、审批、元数据、自动编号、日志审计、外发留痕建起来。
先解决“关键文件终于可控”。
第三步,最后知识化
把全文搜索、摘要标签、分类分级、AI 问答、经验库沉淀叠上去。
再解决“老资料开始创造新利润”。
老板真正该问的,不是‘还要不要再买一台 NAS’,而是‘文件能不能开始为经营结果负责’
如果一个平台只能回答:
那它更像一个存储产品。
如果一个平台还能回答:
- 关键文件能不能统一纳管
- 哪些资料必须审批和留痕
- 哪份才是唯一版本
- 老项目资料能不能变成知识库
- AI 能不能真正建立在企业自有文档之上
那它才真正接近企业级基础设施。
所以,很多老板不是买错了群晖。
而是买完群晖之后,少补了一层最关键的治理能力。
从这个角度看,群晖负责把文件存下来。
一粒云负责把文件真正管成资产。
这才是企业从“文件越来越多”走向“文件越来越值钱”的分水岭。
互动区
如果你是企业主,你现在最想先解决哪一个问题?
NAS 里文件越来越多,但开会前还是找不齐最新版项目、图纸、合同都在流转,但责任链和版本链不清楚老资料沉不下来,AI 和知识库一直停留在概念上系统已经很多了,但文件还是散在各处,没有统一入口
欢迎在评论区留下你的答案。
也欢迎把这篇文章转给公司 IT 负责人、信息化负责人或项目负责人,一起讨论:
群晖之后,企业最该补的,到底是下一块硬盘,还是那层决定效率和风险的治理中台?
关注 一粒云 公众号,下一篇继续拆:
为什么很多企业的 OA、ERP、CRM 都在跑,关键文件却还是沉不成真正的 AI 知识库?
资料依据:本文基于当前目录中的 KDOCS-V5.1.4(智能文档云系统)(视频检索与推荐)、一粒云_云盘功能列表-5.0、文档云模块化+全部组件-指导价格(2025-07)、Synsea-4080-EX-隔离文件安全交换一体机 等文件整理