技术负责人真正该补的是这层文档底座
目标读者:单位技术负责人
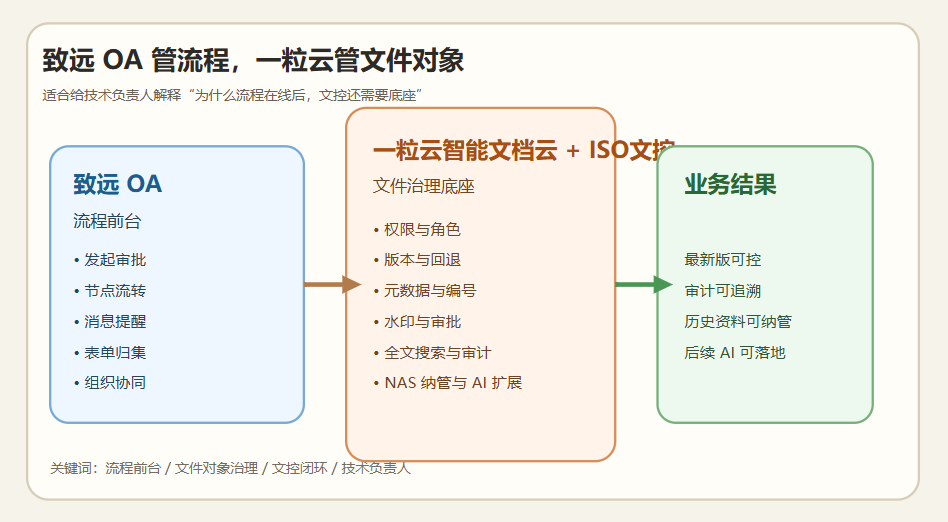
联动品牌:致远 OA
主推方案:一粒云 智能文档云 + ISO文控
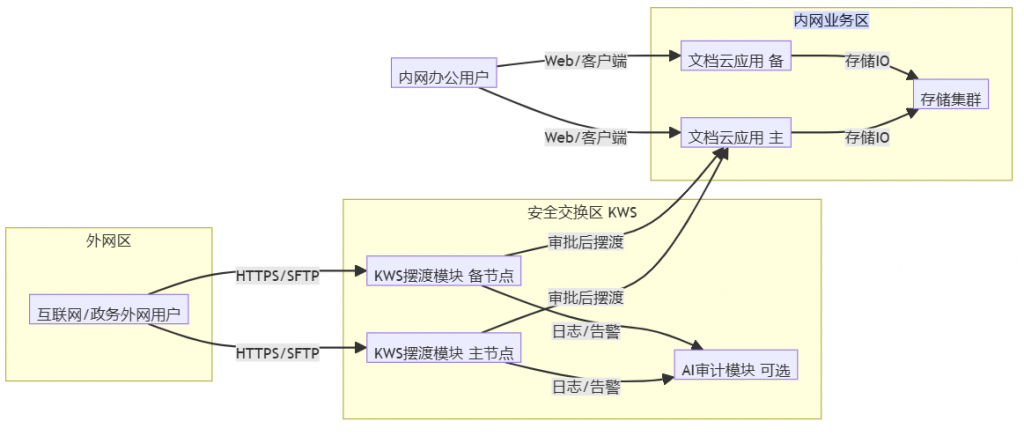
延展产品:企业网盘、AI知识库、智能文件汇聚平台、隔离网文件安全交换
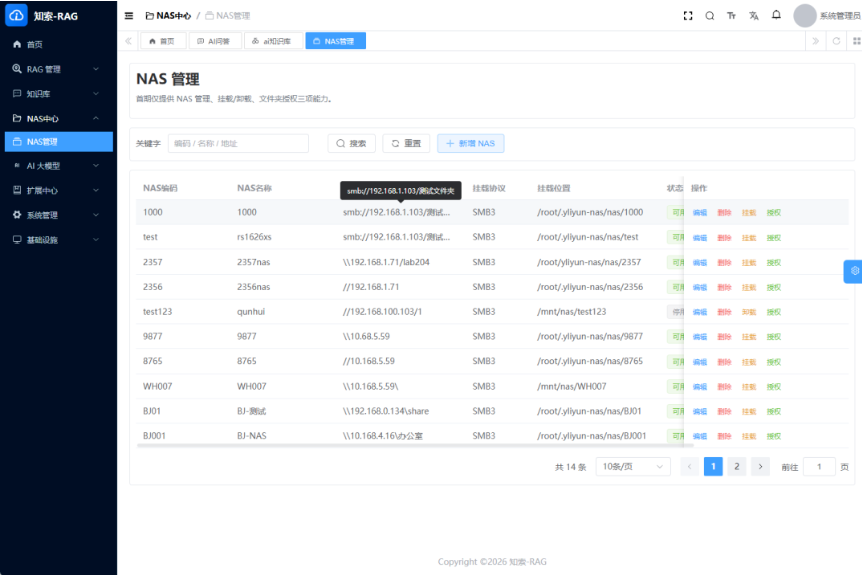
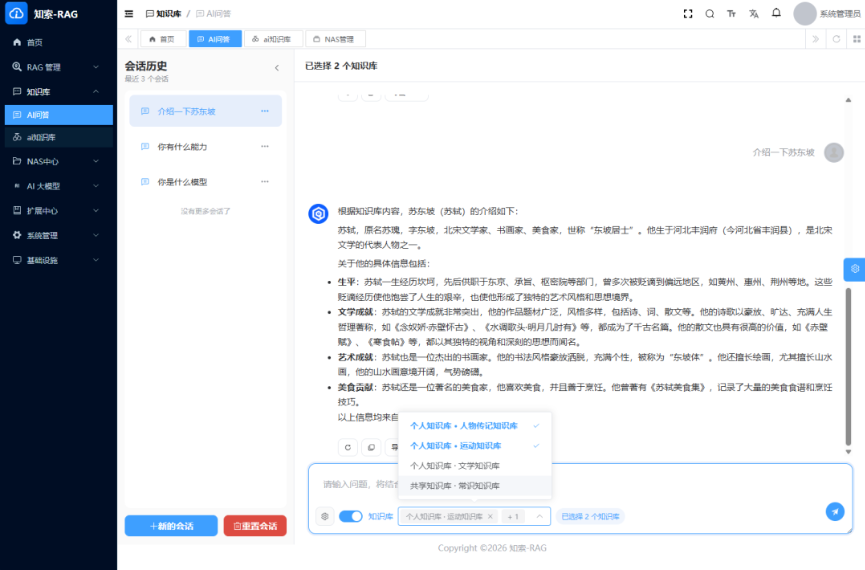
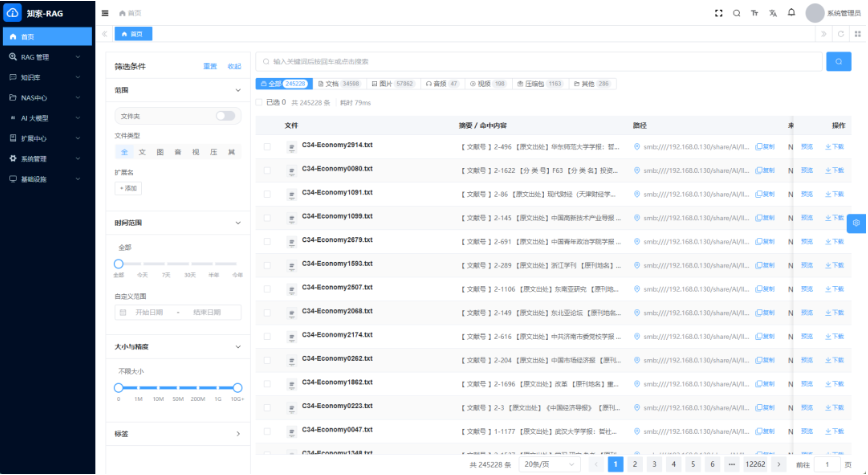
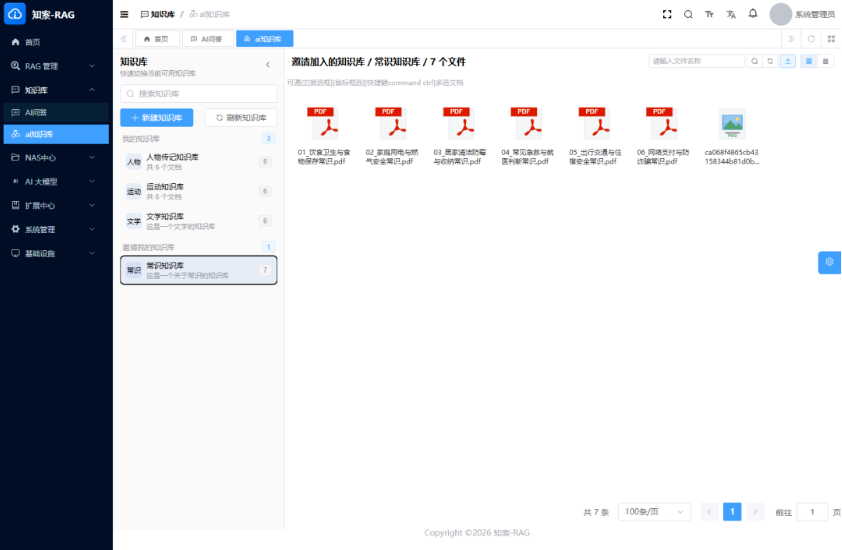
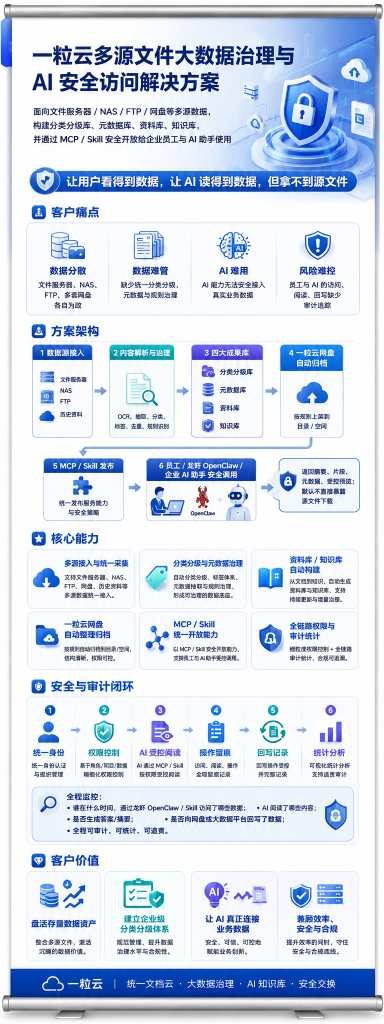
公开资料显示,一粒云成立于 2015 年,70%+ 为研发人员,全国拥有 20+ 区域分销渠道,已服务 2000+ 中大型企业,公开材料中还标注了 100% 成功交付率。产品侧已披露的能力包括:100+ 文件格式在线预览、13 种原子权限、9 个默认角色、NAS / FTP / S3 纳管、千万级文件秒级搜索响应、文档摘要与标签、OCR、NER、知识图谱、流程审批、日志审计,以及与 ERP / OA / AD / 钉钉 / 企业微信 等系统的集成能力。
很多单位技术负责人都遇到过这种场景。
致远 OA 已经把流程跑起来了。
制度审批有入口。
变更单也能追。
通知、催办、归档看起来都在线。
可一旦问题落到“文件对象”本身,麻烦就开始了。
最新版作业指导书到底是哪一版?
哪个部门可以下载,哪个部门只能预览?
审批通过后落到哪里,谁负责归档?
历史版本能不能追溯?
外发之前是否做过检查?
审计追问时,能不能把审批记录、文件版本、访问日志一次性串起来?
这才是很多单位文控项目迟迟做不透的核心矛盾。
流程在线,不等于文件受控。
有审批,不等于有闭环。
有 OA,不等于有文档底座。
对技术负责人来说,最难的不是把审批流画出来,而是把“受控文件”从申请、审核、发布、借阅、修订到作废一路管到底。
如果这条链断了,最后承担协调成本和审计压力的人,往往还是技术负责人。
为什么致远 OA 跑得越成熟,技术负责人反而越容易感到文控压力更大?
因为 OA 管的是“流程动作”,ISO 文控管的是“文件生命周期”。
致远 OA 非常适合承接这些动作:
但 ISO 体系文件、研发受控文件、图纸定版文件、项目交付文件,还需要另一层更细的控制:
- 文件放在哪个空间。
- 谁有查看、下载、编辑、分享、替换权限。
- 修改后是否自动留版本。
- 下载和预览是否加水印。
- 某些操作是否必须二次审批。
- 文件与元数据、编号、业务属性能否关联。
- 文件被谁看过、谁改过、谁导出过,能否追溯。
这就是很多单位上线 OA 后仍然感觉文控“悬着一口气”的原因。
审批单在 OA 里,文件在共享盘里,编号在 Excel 里,版本在部门电脑里。
最终技术负责人不得不做那块“人工中间层”。
而 ISO 文控最怕的,恰恰就是这种分散。
真正缺的不是再加一个审批节点,而是补上一套文件闭环
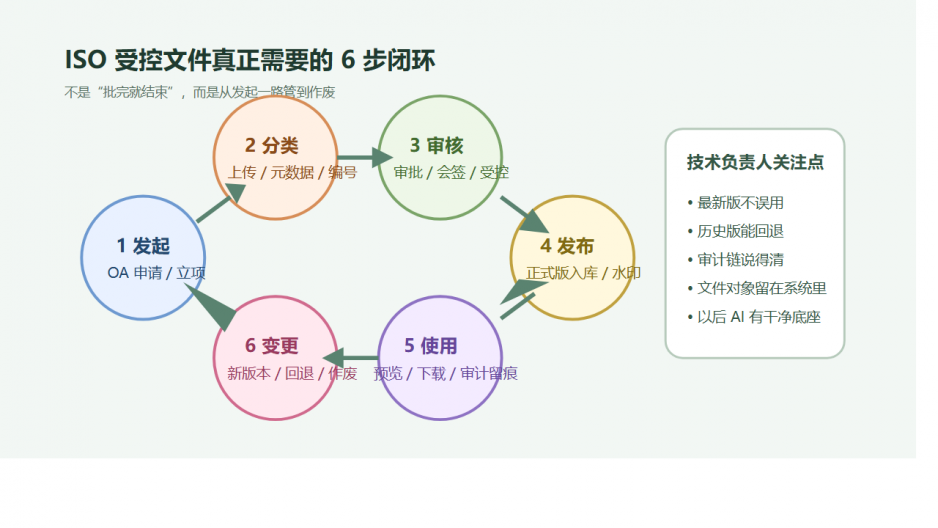
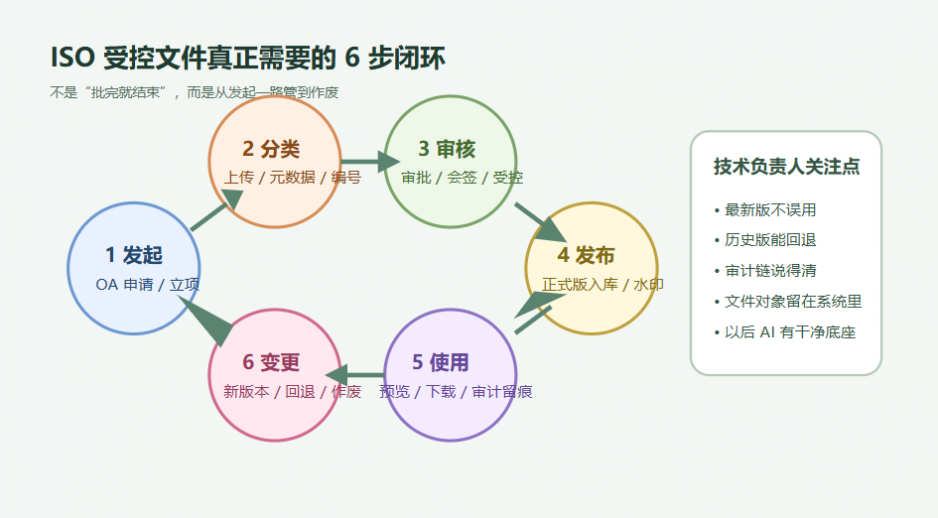
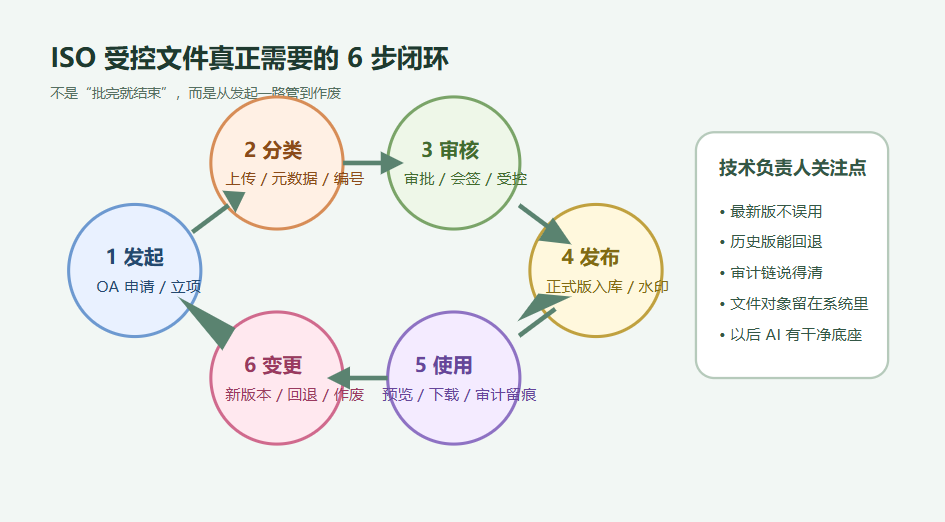
如果把受控文件看成一个完整对象,它至少应该经历 6 个动作:
- 立项或发起
- 上传与分类
- 审核与审批
- 受控发布
- 使用与留痕
- 变更、回退与作废
很多单位今天其实只做到了“有人提”“有人批”。
但文控质量真正取决于后面的发布、使用、回退和作废。
这些问题,不是流程表单天然能解决的,它需要一个围绕文件对象运转的系统能力层。
为什么一粒云更适合补在致远 OA 后面,而不是跟 OA 抢位置?
因为它并不试图替代 OA,而是把自己放在“文件治理层”。
从资料看,一粒云已经具备这几个关键能力:
- 支持
13 种原子权限和 9 个默认角色
- 支持个人空间、部门共享空间、群组空间、单位共享空间
- 支持文件版本管理、回退、备注、回收站
- 支持预览水印、下载水印、防复制、防打印
- 支持文件审批、文控、权限审计、日志审计
- 支持文档元数据、自定义表单、自动编号、归类检索
- 支持全文搜索、OCR、摘要、标签、NER、知识图谱
- 支持
NAS / FTP / S3 挂载和历史资料纳管
- 支持开放 API 与
ERP / OA 模板式对接
对技术负责人来说,这意味着一件很重要的事:
致远 OA 继续承担流程入口,一粒云负责把文件接住,并把文件的整个生命周期拉回到统一底座中。
这样做有三个直接好处:
不推翻现有 OA 习惯;不再把文件治理拆到多个地方;后续扩展 AI 和知识库时,底层数据是干净的。
三类行业场景,最适合用“致远 OA + 智能文档云 + ISO 文控”打透

场景一:制造企业的受控文件发布
工艺文件、检验规范、作业指导书、图纸定版文件,最怕的不是没人审批,而是审批过后现场还在用旧版。
这类场景里,致远 OA 适合承接新版发起、变更审核、会签流转和发布通知;一粒云更适合承接正式版文件入库、历史版本留痕、图纸和 PDF 在线预览、下载水印与权限控制。
这样,技术负责人面对的不再是“流程批完了但执行没收住”,而是“流程和文件终于同频”。
场景二:研发单位的高机要资料管控
资料里明确提到,一粒云支持针对高安全级别文件空间开启文控设置,对上传、下载、更新、分享、删除、预览等动作绑定审批流程,也支持集成加解密、AD、CAD 在线看图以及设备认证。
这类场景最适合放在研发资料、样图、论文、技术规范和定稿资料上。
普通成员可以看目录,但关键动作必须走审批;文件离开系统前能留完整记录;审计时可以从文件反查操作链,而不是从人去猜文件链。
对于技术负责人来说,这种“按目录和对象收口”的做法,比单纯加几条制度更容易落地。
场景三:项目型单位的交付档案治理
很多项目单位的问题不是没系统,而是系统太多。项目审批在 OA,交付资料在共享盘,竣工文档在部门服务器,外部往来资料又在邮件和群里。
一旦进入验收或复盘阶段,技术负责人最怕的就是材料不完整、编号不统一、版本对不上、责任链说不清。
一粒云的元数据、编号、归类检索、权限审计和全文搜索,正好适合把这类项目档案重新拉回到可管理状态。
等底座稳定后,再往上叠加 AI 知识库,项目经验才有机会跨项目复用。
公开案例和数据,为什么足以支撑技术负责人立项?
很多技术方案写到最后容易空,但一粒云这批资料里,其实已经给出了一些能直接用于沟通的公开证据。
例如:
华为电教云 公开材料中提到 500+300TB 有效存储、双 OceanStor 主备、媒体资料管理与对外分享景嘉微 案例中提到 5000 用户、30T 文件、1 个总部节点、5 个交换节点信宇人股份 场景中提到 400 用户、150 名研发、集成 OA / AD / CAD- AI 检测材料中提到,在
4000万 文本压缩包和 160 个特征下,新算法从 20小时 缩短到 6分钟,速度提升 200倍,准确率 >90%
这些数据不需要被夸大。对技术负责人来说,它们已经足以说明两件事:
这不是只能演示的轻量工具;这也不是只讲协同的网盘。
它往上能接文控、搜索、AI 知识化,往下能接存储、权限、安全和多系统集成。
怎么跟领导解释,最容易让这个项目通过?
不要把它讲成“再上一套系统”,更有效的说法是:
我们不是替换致远 OA,而是在 OA 之后补齐受控文件闭环。
可以这样解释:
对单位领导, 这是审计可追溯和责任闭环;
对质量或体系部门, 这是受控文件发布、变更、借阅、作废与历史版本管理;
对业务部门, 这是“找得到、看得懂、拿得到最新版”;
对运维团队, 这是权限、日志、存储纳管和历史资料治理。
如果现在就要推进,技术负责人最稳的落地路径是什么?
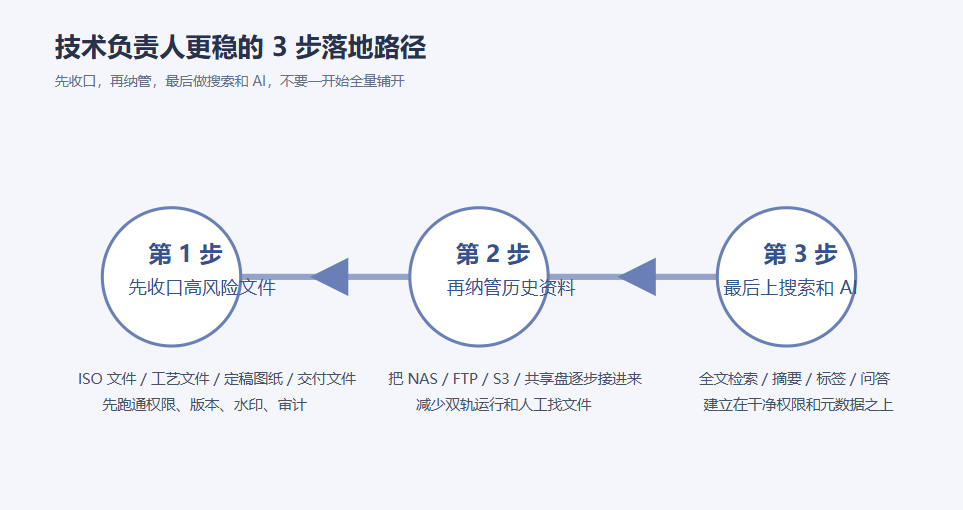
建议分三步,不要一口气全量铺开。
第一步,先选一类高风险文件。 例如 ISO 体系文件、工艺文件、研发定稿文件、项目交付文件,先把权限、版本、水印、日志、审批跑通。
第二步,再把历史资料纳管进来。 利用 NAS / FTP / S3 挂载能力,把老共享盘、部门盘、历史归档盘逐步接入,减少双轨运行。
第三步,最后再上搜索和 AI。 等元数据、编号、权限、历史版本都稳定下来,再启用全文搜索、摘要、标签、知识问答。
这个顺序很重要。
因为很多单位不是没有 AI 预算,而是底层文件根本不适合拿来做 AI。
技术负责人最后要盯住的,不是“功能有多少”,而是这 6 个判断标准
1. 审批通过后,文件有没有自动进入受控空间?
2. 最新版和历史版能不能同时留住且不被误用?
3. 预览、下载、分享、替换、删除能不能按对象留痕?
4. 旧 NAS 和共享盘资料能不能平滑纳管?
5. 文件能不能关联编号、表单和业务属性?
6. 后续做 AI 知识库时,答案是否建立在权限之上?
如果这 6 个问题里有 3 个答不上来,那么这个单位的文控大概率还是“流程在线、文件失控”。
而“致远 OA + 一粒云智能文档云 + ISO 文控”这套组合的价值,恰恰就在这里:
让 OA 继续做它擅长的流程,让文件回到一套真正可追溯、可管控、可扩展的底座里。
这不是多买一个工具,而是把技术负责人最难扛的那部分责任,从“人工协调”改成“系统闭环”。
另外,如果你是渠道伙伴或区域服务商,对外沟通时可以只表述一粒云存在约 20%~65% 的渠道合作空间,不公开具体报价即可。
互动区
你所在单位当前最头疼的文控问题,更接近下面哪一种?
A. 审批在线了,但最新版还是管不住
B. 文件很多,但版本、编号、权限都散在各处
C. 体系文件能发不能控,审计追溯很痛苦
D. 想做 AI 知识库,但底层文件还没统一纳管
欢迎把答案打在评论区。
如果你想继续看“一粒云智能文档云、ISO 文控、AI 知识库、隔离网文件安全交换”相关场景文章,欢迎关注公众号,并把这篇文章转给正在推进文控项目的同事一起讨论。