备选标题 1: 钉钉已经全员在线,为什么文件还是找不到、管不住、留不下?
备选标题 2: 群消息秒回,关键附件却总失控?很多公司 IT 都卡在这条“最后一公里”
目标读者:公司 IT
联动品牌:钉钉
主推方案:一粒云 企业网盘 + ISO文控
延展产品:智能文档云、智能文件汇聚平台、AI知识库
依据模块:钉钉与 H5 集成、企业网盘功能列表、ISO 文控、多源存储纳管、日志审计与安全治理
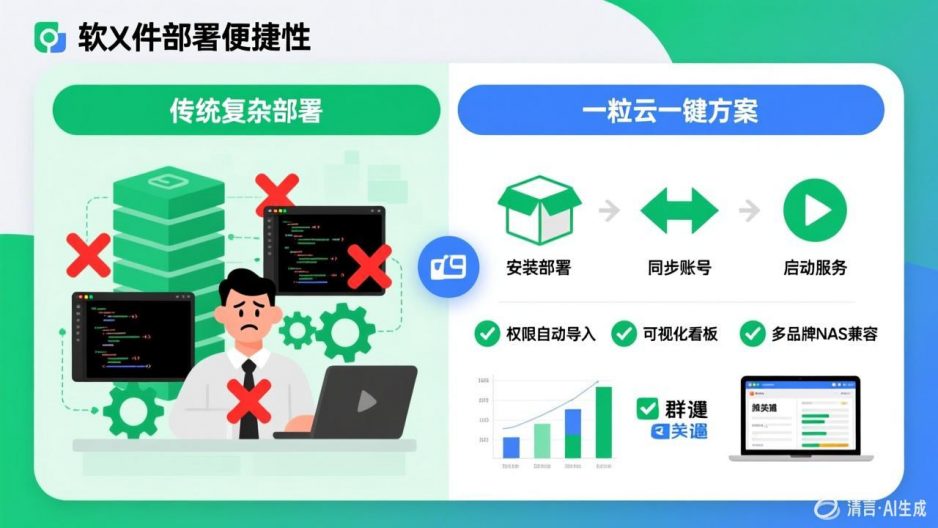
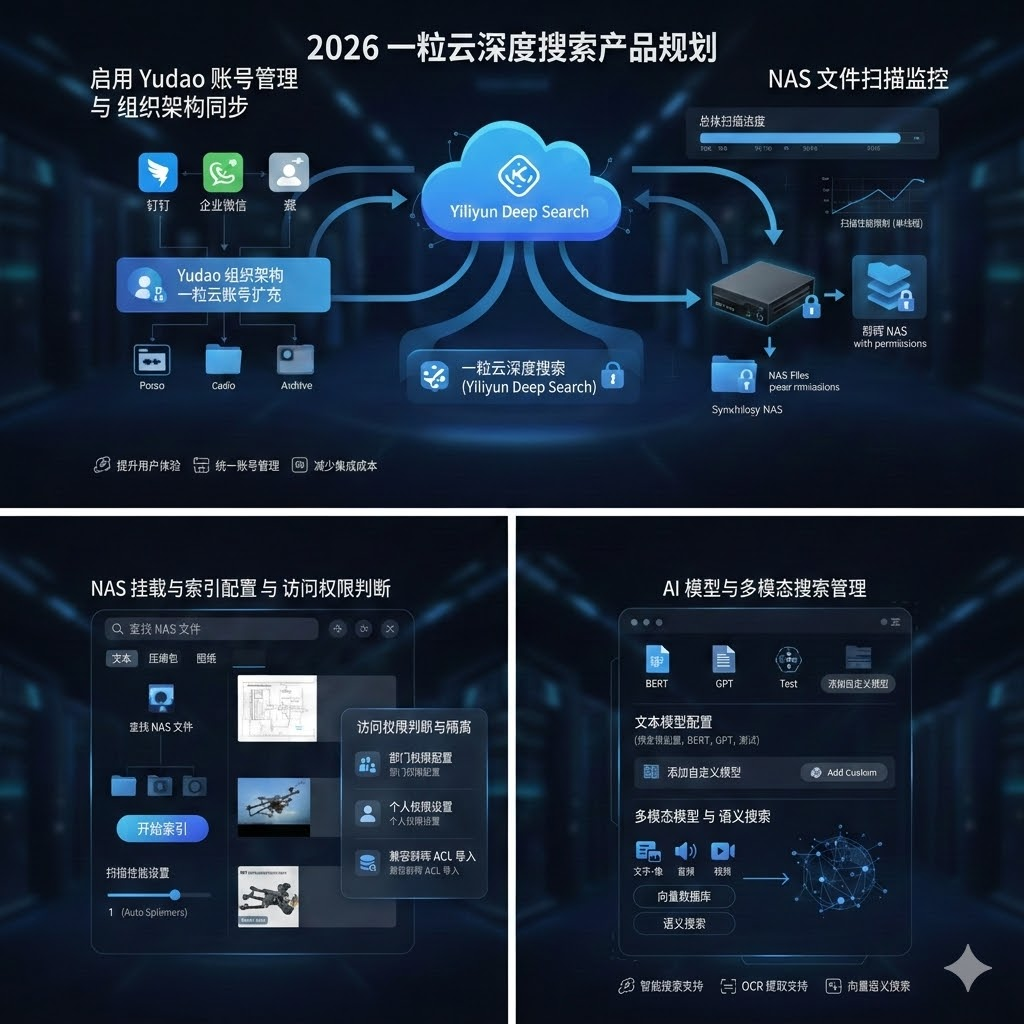
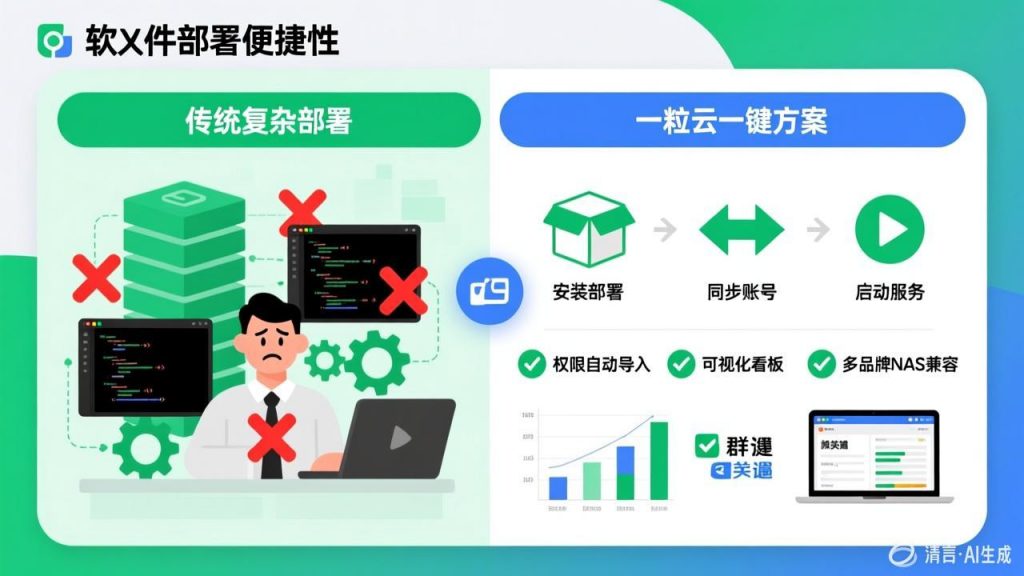
已披露支撑信息显示:一粒云成立于 2015 年,研发占比 70%+,服务 2000+ 中大型企业客户,保持 100% 成功交付率;系统支持 13 种原子权限、9 个默认角色、100+ 文件格式在线预览,并支持 NAS / FTP / S3 纳管、钉钉 / 企业微信 / OA / ERP / H5 集成。
很多公司 IT 这两年都遇到同一个悖论。
钉钉越来越活跃。
审批越来越在线。
消息触达越来越快。
但一到真正要找附件、核版本、追责任的时候,组织还是会突然慢下来。
合同在群里传过。
制度在审批里挂过。
图纸在网盘里存过。
最终版到底是哪一份,却没有人敢拍板。
这不是钉钉的问题。
钉钉擅长的是把人连起来、把消息送到位、把流程推起来。
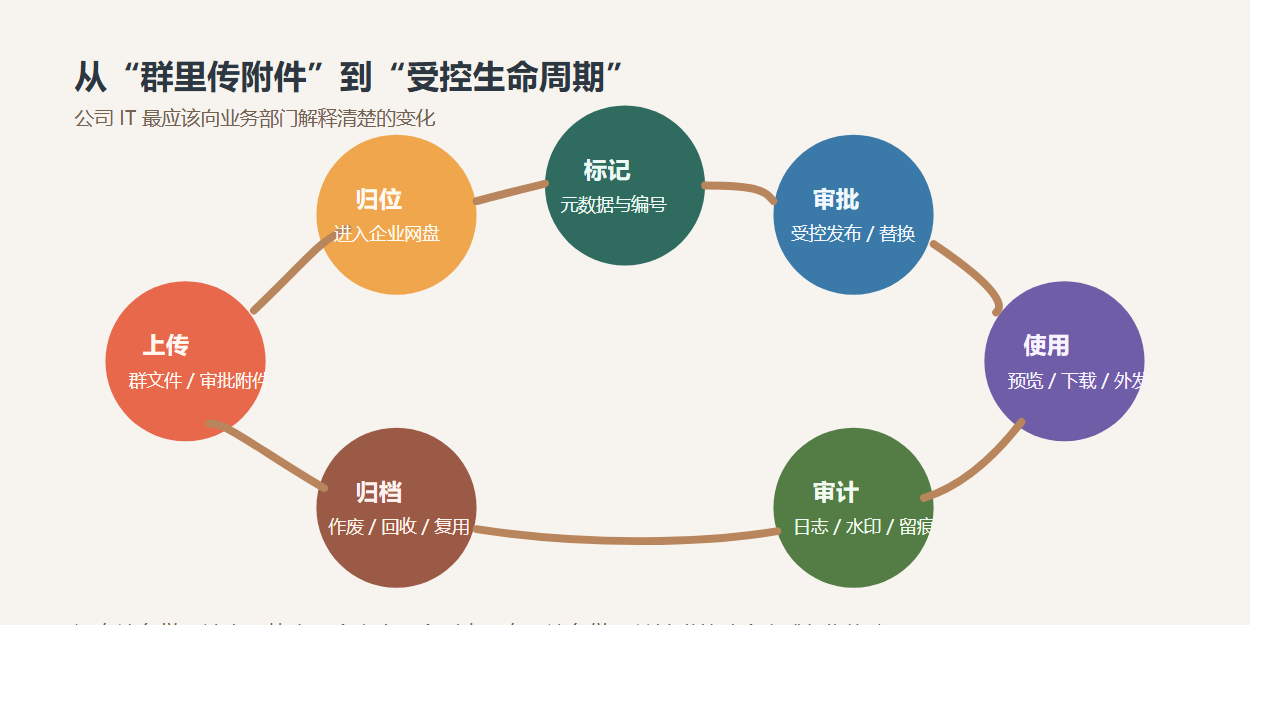
可公司 IT 真正头疼的,往往不是消息链,而是附件链。
一份文件从产生到被使用,至少要经过这些环节:
- 上传到群或审批
- 被多人下载转发
- 形成多个副本
- 发生版本替换
- 对外发送或归档
只要这条链没有统一规则,消息越快,文件越容易失控。
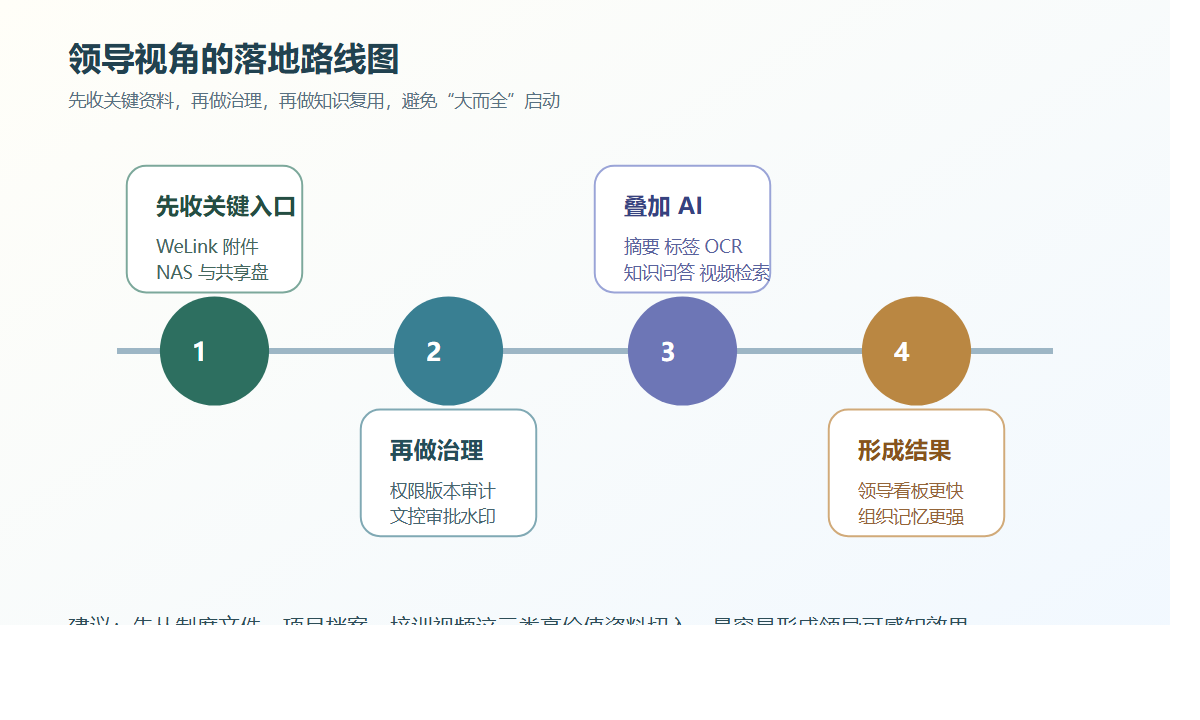
所以,对已经深度使用钉钉的企业来说,下一步最值得补的,不是再堆一层流程,而是把文件真正纳入 企业网盘 + ISO文控 的受控体系。
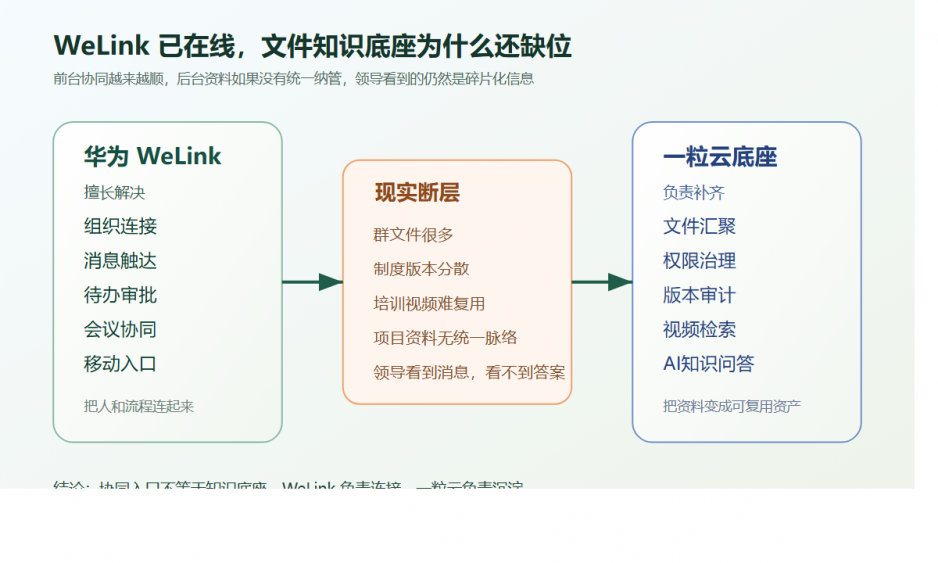
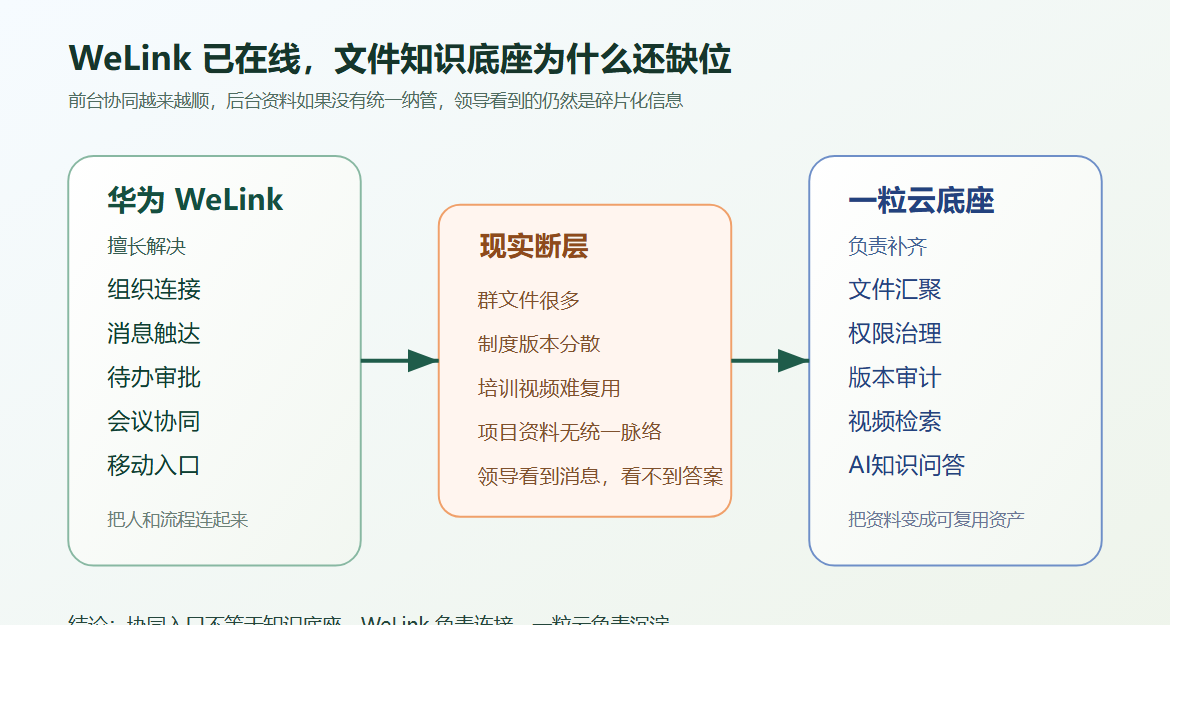
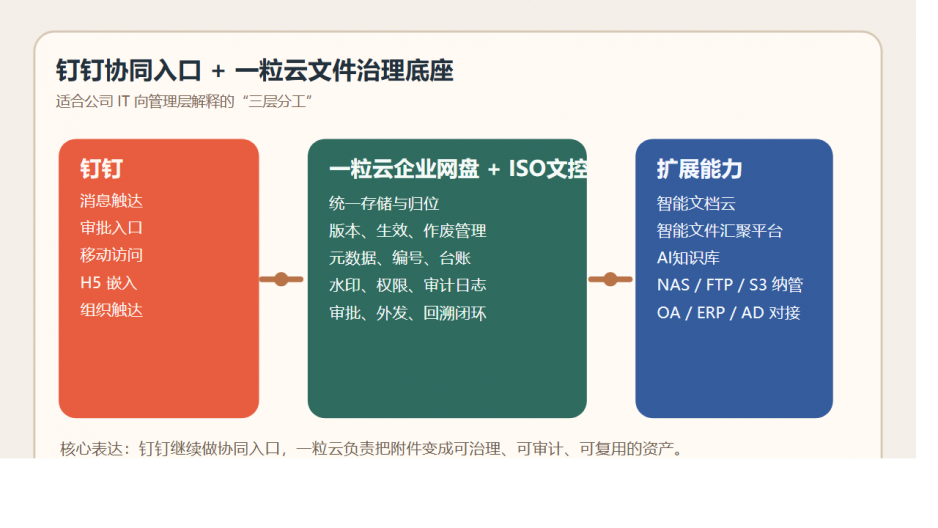
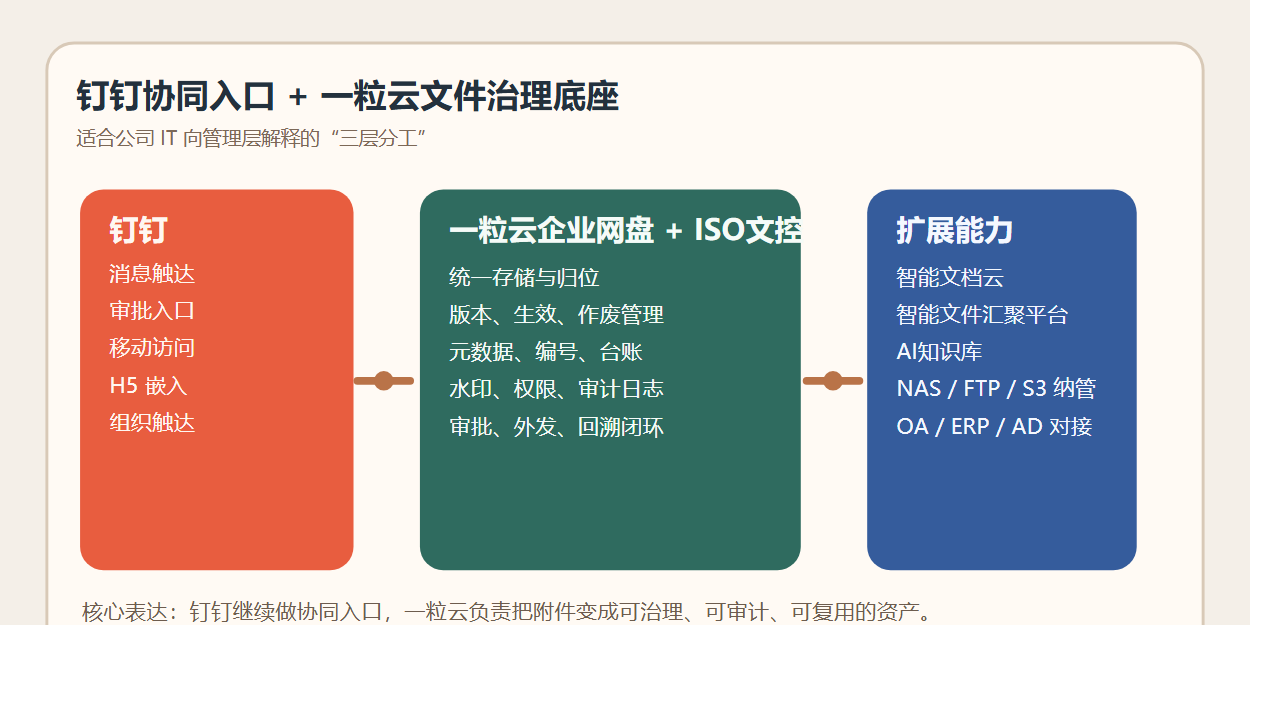
先说结论:钉钉管触达,一粒云管文件闭环
如果把钉钉看成组织协同入口,那一粒云更像附件治理底座。
钉钉负责:
- 消息触达
- 审批发起
- 移动入口
- 组织协同
一粒云补的则是:
- 文件统一存储与归位
- 在线预览、编辑、版本回退
- 权限、水印、日志、审计
- 元数据、编号、受控发布、作废管理
- 历史存储与业务附件的统一纳管
这套分工的价值在于,让“消息在线”升级成“文件可控”。
为什么很多企业钉钉用得越深,附件问题反而越明显?
因为流程量上来后,附件已经不是补充信息,而是业务本体。
最常见的 4 类问题,公司 IT 一定见过。
问题一:同一个文件,组织里同时存在 4 个版本
制度修订了一次。
合同改了两轮。
项目方案又按领导意见补了一版。
最后你会看到:
- 钉钉审批单里一版
- 群文件里一版
- 部门共享盘一版
- 员工桌面上还有一版“最终版2”
真正的问题不是存储空间不够,而是没有唯一生效版本。
ISO文控 的作用,就是把关键文档从“谁手上有一份”,变成“系统里只有一份受控版本”。
问题二:钉钉把消息送到了,但文件没有归位
很多组织已经把钉钉作为默认办公入口。
员工觉得自己已经在线办公了。
可 IT 很清楚,附件并没有真正进入统一资产池。
它们可能散在:
- 钉钉群文件
- 钉钉审批附件
- 本地电脑
- NAS
- FTP
- 历史共享盘
这意味着领导追一份资料时,IT 还是要跨多个入口去兜底。
问题三:出了问题能找到流程,找不到证据链
审批记录还在。
谁点了通过也能看到。
但文件是否被替换过、谁下载过、谁外发过、谁看的是旧版,往往说不清。
资料里明确提到,一粒云支持文件操作日志、审批日志、基于文件的日志审计、设备控制、预览与下载水印。
这对 IT 的意义很直接:从“流程可查”升级成“文件可追”。
问题四:员工天天在钉钉里传资料,知识却沉不下来
今天群里传一份模板。
明天另一个项目群再传一次。
后天新人入职,又从老员工那里私聊要一版。
长期下来,企业并不缺文件。
企业缺的是一个能持续沉淀高价值附件的底座。
一粒云为什么更适合补在钉钉后面,而不是替代钉钉?
因为最现实的数字化项目,从来不是推倒重来,而是补齐断层。
现有资料已经给出了很明确的联动线索:
- 支持
钉钉企业微信集成 - 支持
H5嵌入 - 支持
API / SDK - 支持对接
OA / ERP / HR / AD - 支持
NAS / FTP / S3纳管
这意味着公司 IT 不需要做一件高风险的事: 强迫员工换入口。
更合理的做法是:
- 继续让钉钉作为消息和移动入口。
- 用一粒云承接关键附件、共享资料和历史文件。
- 对高价值资料叠加
ISO文控,形成编号、版本、生效、作废、审批闭环。 - 再把后续搜索、知识库、内容分析逐步叠上去。
这条路对 IT 最友好,因为它先解决“归位”,再解决“增值”。
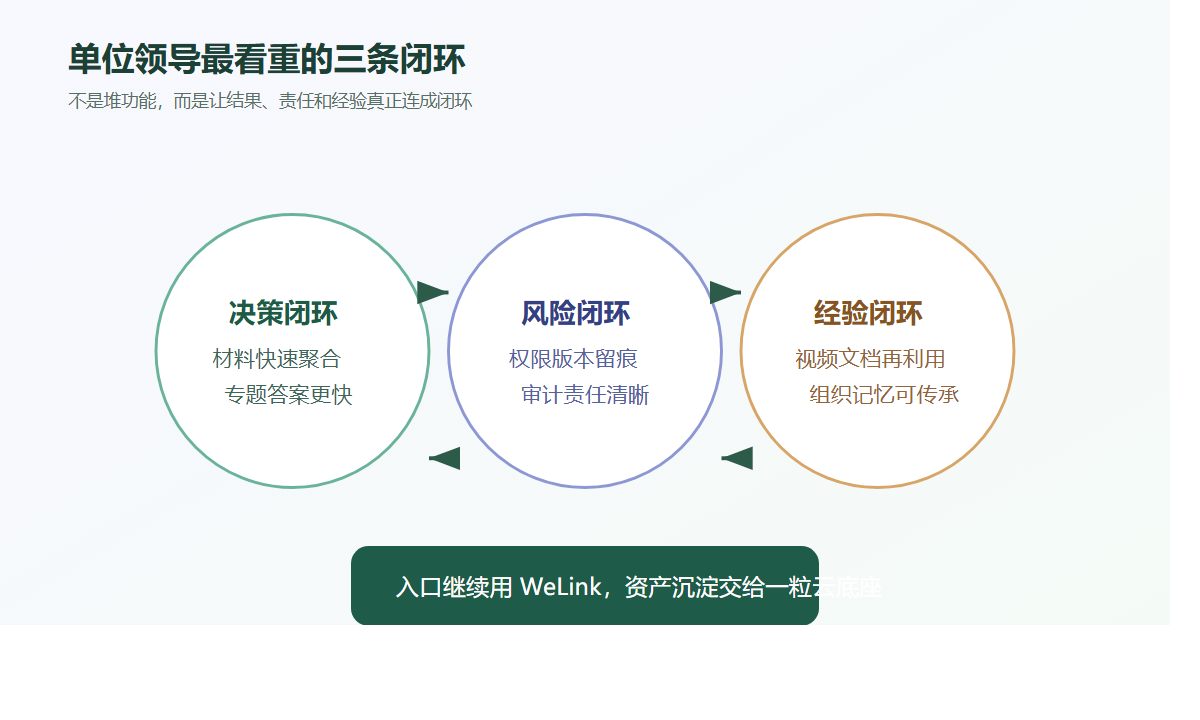
公司 IT 最需要的,其实不是更多功能,而是一条清晰的治理链
把资料里的能力串起来看,会更清楚。
企业网盘层面,一粒云已经覆盖:
- 个人空间、部门空间、共享空间
- 在线预览、多人协同、版本管理
- 高级检索、全文检索、标签检索
- 水印、回收站、编辑锁、审计日志
13种原子权限和9个默认角色
ISO文控 层面,又进一步提供:
- 上传、下载、更新、分享、删除、预览等动作审批
- 元数据表单
- 自动编号
- 表格化台账
- 受控发布、版本替换、历史追溯
这就形成了一条 IT 能真正向管理层解释清楚的治理链:
钉钉负责通知和流转,企业网盘负责存储和协作,ISO文控负责关键资料的受控生命周期。
一个典型场景:钉钉流程已经上线,制造/项目资料还是反复失控
这个场景在制造、工程、研发型企业里最典型。
资料在 Word、Excel、PPT、CAD 里产生;
通过钉钉群或审批发起协作;
审核通过后,再被下载到本地、传给供应商、转存到共享盘。
真正危险的不是审批阶段,反而是审批后的流转阶段。
因为一旦缺少统一文件平台,IT 会连续遇到这些问题:
- 现场看到的是不是最终版,没人能保证
- 同一个部门内部谁能编辑、谁只能预览,规则不稳定
- 对外发出的附件,是否带水印、是否过期失效,难统一
- 旧资料能不能快速归档,能不能避免继续被误用,也难统一
资料中的客户案例已经能说明这类需求并不小:
景嘉微场景披露过5000 用户 / 30T 文件 / 1 个总部节点 + 5 个交换节点信宇人场景披露过400用户、其中150研发,且集成OA / AD / CAD 在线看图- 隔离交换资料中还明确写到,可与
钉钉做审批消息联动和嵌入式审批
这些信息说明,一粒云不是在讲一个轻量文件夹工具,而是在解决复杂组织里的非结构化资料治理问题。
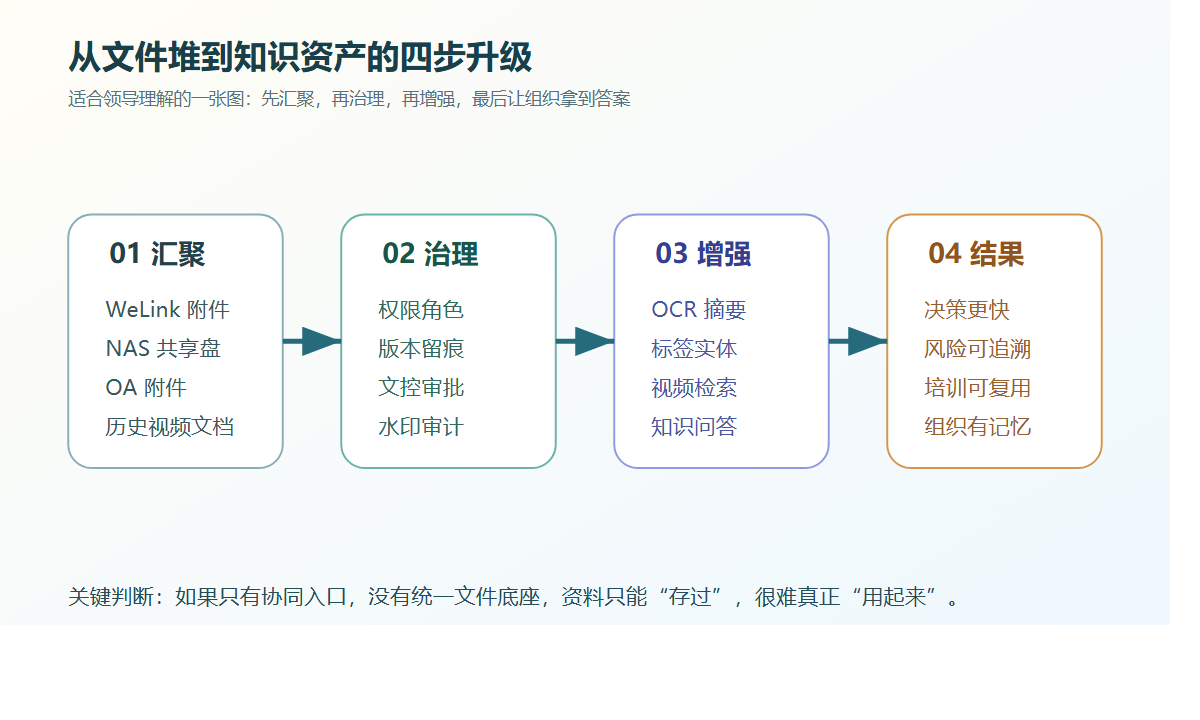
为什么 IT 应该先做“企业网盘 + ISO文控”,而不是一上来就做 AI?
因为没有受控文件底座,AI 很容易变成“回答不稳定、引用不可信”的表面智能。
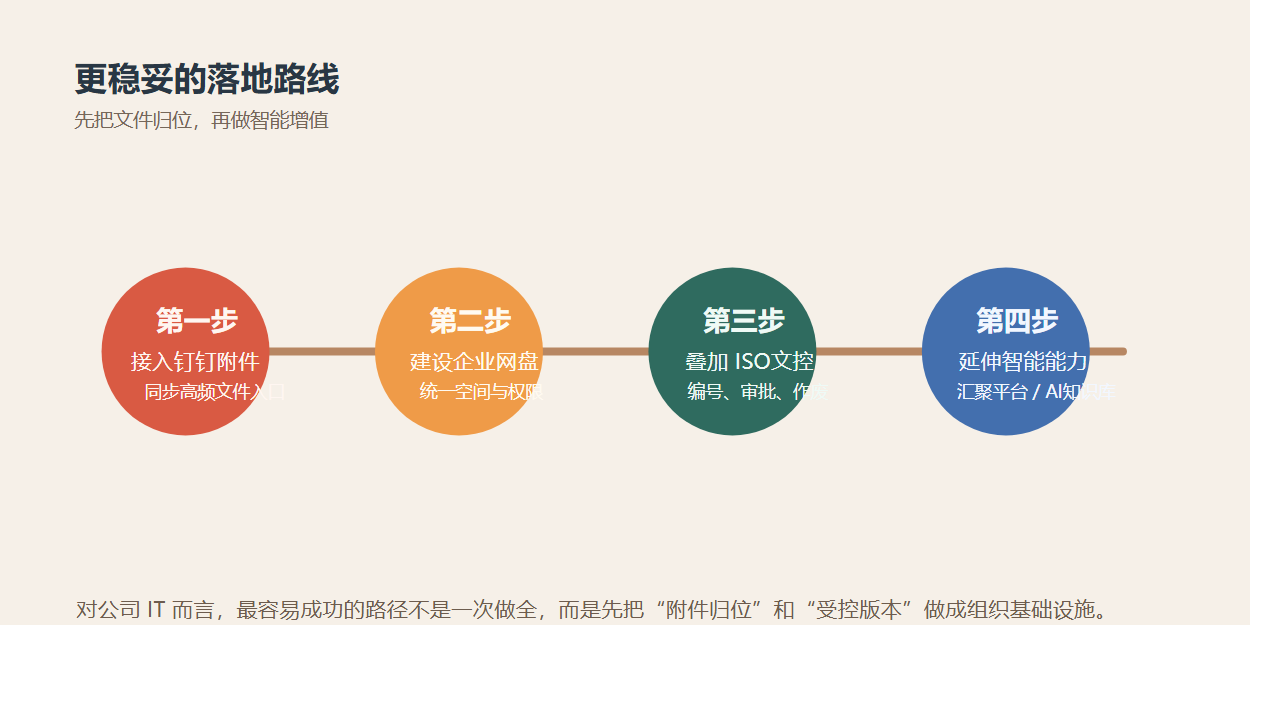
正确顺序通常应该是:
- 先把高频文件收进统一入口。
- 先把权限、版本、日志、审批做扎实。
- 再把高价值文件做标签、搜索、知识库和智能分析。
也就是说,企业网盘 + ISO文控 不是 AI 的替代品,反而是 AI 能真正落地的前提层。
这一点对公司 IT 很关键。
因为 IT 真正要交付给业务的,不只是一个“能用”的系统,而是一条后续还能不断升级的底座。

如果你们已经在用钉钉,什么时候说明这件事该立项了?
可以直接看 5 个信号。
信号一:群里文件很多,但真正可复用的资料很少
这说明消息很活跃,资产却没有沉淀。
信号二:领导一问“最终版在哪”,还是只能靠人肉确认
这说明版本治理和生效机制没有建立。
信号三:NAS、共享盘、钉钉附件并存,没人敢说入口统一
这说明现网已经进入“多入口失控期”。
信号四:审计或复盘时,能查到流程,查不到完整文件证据链
这说明流程在线了,文件闭环还没建立。
信号五:企业已经在讨论 AI知识库,但底层附件仍旧散乱
这说明立项顺序要调整,先把文件底座打稳。
对渠道和项目推进来说,还有一个现实价值
现有资料虽然不能公开写具体价格,但已经足够说明一件事:
一粒云的渠道体系成熟,全国有 20+ 区域分销渠道,合作空间约 20%~65%。
这对公司 IT 也有现实意义。
因为很多项目最终不是卡在功能,而是卡在本地交付、协同推进、后续服务。
渠道体系成熟,意味着后续方案联动、实施支持和区域服务更容易形成闭环。
最后一句话:钉钉解决不了所有问题,但它很适合接上一粒云这层底座
如果你的判断标准只是“消息能不能到人”,那钉钉已经做得很好。
但如果你的判断标准升级为:
- 文件能不能统一归位
- 关键版本能不能唯一生效
- 谁看过、改过、发过能不能追溯
- 资料能不能沉成组织资产
那公司 IT 迟早都要补上这层能力。
对已经深度使用钉钉的企业来说,最稳妥的路线不是再造入口,而是把一粒云 企业网盘 + ISO文控 接在入口之后,把文件真正变成受控资产,再逐步延伸到 智能文档云、智能文件汇聚平台 和 AI知识库。
如果你是公司 IT,你所在单位现在最痛的一点,是“版本混乱”、 “附件分散”,还是“审计追责难”?
欢迎在评论区写下你遇到的真实场景,也可以把这篇文章转给正在推进钉钉协同、文件治理、知识库建设的同事一起讨论。
关注公众号,下一篇继续拆解一粒云在不同系统联动下的落地打法。