在国内做文档管理的企业都在逐渐推动一个全新的概念:企业内容管理成熟度规划模型,我们来系统讲解一下 内容管理成熟度规划模型(Content Management Maturity Model, 简称 CM³)。
这个模型常用于评估一个企业或者组织在内容管理(Content Management, CM)方面的能力水平,帮助制定内容战略、规划信息化路径,并推动企业从“分散内容”走向“智能内容生态”。同样一粒云研究和推动这个模型也是希望在进入AI时代的今天, 一粒云和CM3的融合,不仅是企业实现内容资产治理、提升运营效能的抓手,更是支持组织数字化转型、持续创新和业务增长的核心引擎。
🧩 一、CM³ 模型的核心目的
CM³(Content Management Maturity Model) 是一种评估框架,用于衡量组织在内容管理方面的成熟程度。
它的目标是帮助组织:
- 识别当前内容管理的能力水平
- 规划从初级到高级的演进路线
- 优化流程、治理体系与技术架构
- 支撑知识管理与数字化转型
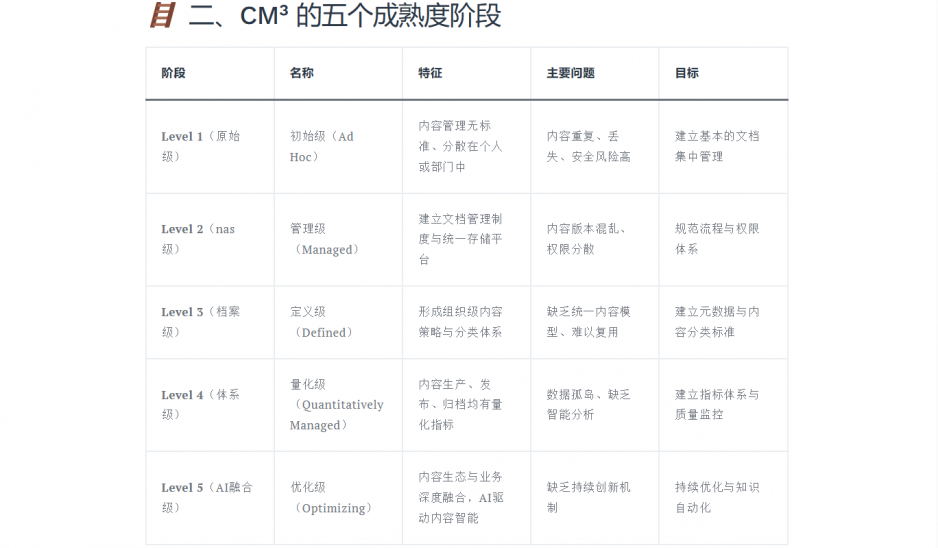
🪜 二、CM³ 的五个成熟度阶段
| 阶段 | 名称 | 特征 | 主要问题 | 目标 |
|---|---|---|---|---|
| Level 1(原始级) | 初始级(Ad Hoc) | 内容管理无标准、分散在个人或部门中 | 内容重复、丢失、安全风险高 | 建立基本的文档集中管理 |
| Level 2(nas级) | 管理级(Managed) | 建立文档管理制度与统一存储平台 | 内容版本混乱、权限分散 | 规范流程与权限体系 |
| Level 3(档案级) | 定义级(Defined) | 形成组织级内容策略与分类体系 | 缺乏统一内容模型、难以复用 | 建立元数据与内容分类标准 |
| Level 4(体系级) | 量化级(Quantitatively Managed) | 内容生产、发布、归档均有量化指标 | 数据孤岛、缺乏智能分析 | 建立指标体系与质量监控 |
| Level 5(AI融合级) | 优化级(Optimizing) | 内容生态与业务深度融合,AI驱动内容智能 | 缺乏持续创新机制 | 持续优化与知识自动化 |
🧠 三、CM³ 的核心构成维度
CM³ 通常从以下六大维度对内容管理进行成熟度分析:
| 维度 | 说明 | 关键指标 |
|---|---|---|
| 1. 策略与治理 | 是否存在统一的内容战略与治理体系 | 内容政策、流程标准化、合规机制 |
| 2. 技术与架构 | 内容管理系统的技术架构与自动化水平 | 系统集成度、平台化、AI 应用程度 |
| 3. 流程与生命周期 | 内容从创建、审批、发布、归档的全生命周期管理 | 生命周期自动化程度、版本管理 |
| 4. 数据与元信息 | 元数据、标签、语义关联与检索能力 | 元数据标准化、检索准确率 |
| 5. 用户与协作 | 用户体验与跨部门协作效率 | 协作机制、访问控制、反馈闭环 |
| 6. 绩效与优化 | 是否建立指标来衡量内容质量与业务价值 | KPI 建立、数据驱动决策能力 |
🏗️ 四、CM³ 的实施步骤
- 现状评估(Assessment)
通过访谈、系统分析、文件调研等方式确定当前阶段。 - 差距分析(Gap Analysis)
对比目标成熟度与现状,识别能力差距。 - 路线规划(Roadmap Design)
制定短期与中长期内容管理建设路线(如3年规划)。 - 体系建设(Implementation)
包括内容策略制定、技术平台建设、流程优化、人员培训。 - 持续优化(Continuous Improvement)
通过度量指标与AI分析不断优化内容质量与生产效率。
🧩 五、CM³ 在企业中的典型应用场景
| 场景 | 应用说明 |
|---|---|
| 文档云/知识库建设 | 指导从分散文件管理 → 企业级知识中心的演进 |
| 数字化办公与协作平台 | 建立统一的内容分类、权限与审计体系 |
| AI 知识检索与问答系统 | 为企业 RAG 系统提供高质量的结构化内容源 |
| 合规与信息安全治理 | 内容流转全程可控、可追溯 |
| 企业内容战略规划 | 支撑内容资产化与知识变现 |
🚀 六、CM³ 与 AI 智能内容管理的结合趋势(2025+)
随着企业进入 内容智能化(Content Intelligence) 阶段,CM³ 模型进一步演化为 智能内容管理成熟度模型(ICM³),融合大模型与知识图谱技术:
| 传统 CM³ | 智能 CM³(ICM³) |
|---|---|
| 文档级管理 | 语义级知识管理 |
| 静态分类体系 | 动态标签与向量检索 |
| 人工审核与发布 | AI 驱动内容推荐与质量评估 |
| 独立平台 | 融合企业知识中枢与多端生态 |
| 测量标准:数量、版本 | 测量标准:知识价值、影响力、复用度 |
🧭 七、总结:CM³ 帮助企业实现从“文件”到“知识资产”的跃迁
🌐 CM³ 的核心价值:
把“内容”从资源变成“资产”,从资产变成“智能生产力”。
演进路径示意:
文档管理(DMS) → 内容管理(CMS) → 知识管理(KMS) → 智能内容管理(ICMS)
是否希望我帮你画出一张 CM³ 五级成熟度模型金字塔图(中英双语),方便展示或纳入你的文档规划?
CM³:内容管理成熟度规划模型(Content Management Maturity Model)
下面给出一个可直接用于评估、规划与落地改进的 CM³ 方法论与工具包,涵盖定义、分级、评估表、路线图、KPI、制度清单与工具映射,适合从零起步到规模化运营的团队。
1. 模型定义与目标
- 定义:CM³ 是面向组织“内容全生命周期管理”的成熟度模型,帮助识别短板、制定演进路径,并持续度量改进效果。
- 目标:
- 建立统一的内容战略与治理体系
- 降低生产与分发成本,提升复用率与一致性
- 强化合规与风险控制
- 支撑多渠道、个性化与智能化内容运营
适用范围:企业官网/商城、品牌与营销、产品知识库、服务/支持文档、内部知识库、媒体/多语言/多区域内容运营等。
2. 维度框架(8 大维度)
1) 战略与目标:内容与业务目标的对齐、北极星指标
2) 治理与合规:政策制度、审批流程、版权/合规、版本留痕
3) 组织与角色:编辑、审核、法务、运营、数据分析的分工与 RACI
4) 流程与生命周期:策划-生产-审核-发布-分发-下架-归档的端到端闭环
5) 内容模型与数据:内容类型、字段、结构化、元数据/标签、Taxonomy/词表
6) 技术与平台:CMS/DAM/搜索/翻译/多语、多渠道投放、API/Headless 能力
7) 运营与分发:渠道矩阵、A/B、个性化、SEO/可发现性、可访问性
8) 度量与优化:指标体系、看板、实验与持续优化机制
3. 成熟度分级(L0–L5)
- L0 混沌/偶发:无统一平台与流程,人治为主,文件散落各处
- L1 可感知/可重复:有基本模板和审批,但靠经验驱动,缺少统一标准
- L2 已定义:统一内容模型/流程/角色清晰,关键制度与标准形成文档
- L3 度量管理:建立指标体系与看板,基于数据进行计划与调整
- L4 预测与规模化:多渠道统一分发,自动化与平台化,复用/多语/权限精细化
- L5 智能与优化:基于数据与 AI 实现智能标签、个性化、动态编排与持续优化
判断方法(简化版):若8个维度中“最低分”为 N,则总体不高于 N;若“平均分≥N 且至少 6/8 维度≥N”,可评为 N。
4. 快速自评量表(打分 0–5)
为每题选择最贴近现状的等级,计算各维度平均分。
- 战略与目标
- 内容目标是否与业务北极星指标对齐并固化在年度/季度计划中?
- 是否有内容资产 ROI/复用率/线索贡献等的常规复盘?
- 治理与合规
- 是否有成文的内容政策(版权、隐私、品牌、无障碍)与执行审计?
- 是否具备版本管理、留痕、责任追溯与自动化合规校验?
- 组织与角色
- 是否完成 RACI 明确与岗位培训,跨团队协作是否顺畅可量化?
- 是否有内容运营与数据分析的例行机制?
- 流程与生命周期
- 是否实现全流程可视化、SLA、瓶颈监控、在制品控制(WIP)?
- 下架/归档/重用/更新是否制度化和常态化?
- 内容模型与数据
- 是否有统一的内容类型/字段/词表/标签规范并强制执行?
- 元数据是否用于驱动检索、推荐、复用与权限?
- 技术与平台
- 是否具备 Headless CMS、DAM、搜索服务、多语/翻译、API 分发?
- 是否与业务系统(CRM/PIM/CDP)联动,自动同步或触发?
- 运营与分发
- 是否支持多渠道编排、A/B 实验、SEO/Schema、可访问性达标?
- 个性化与分群是否落地到规则或模型驱动并可回溯?
- 度量与优化
- 是否有统一指标口径、自动化采集、可视化看板?
- 是否形成“指标-问题-行动-验证”的闭环节奏?
评分建议:0=无;1=在做但零散;2=规范已定义;3=执行稳定并度量;4=跨域联动与自动化;5=可预测、智能与持续优化。
5. 规划路线图(12 个月三阶段)
- 0–90 天:打地基
- 产出:现状评估报告、目标成熟度、差距清单、RACI、政策草案、内容模型 v1、工具选型、PoC
- 快速价值:统一模板、轻量审批、基础 KPI(发布周期/复用率/合规缺陷率)
- 3–6 个月:标准化与规模化
- 上线 Headless CMS/DAM/搜索,多渠道发布打通;元数据/词表落地;多语与翻译流程跑通
- 建立看板与每月复盘;SEO/可访问性标准执行
- 6–12 个月:自动化与智能化
- A/B、个性化、内容推荐;自动标签/摘要/去重;与 CDP/CRM/PIM/MDM 打通
- 建立“实验-评估-推广”机制,逐维度拉升到 L3–L4,试点 L5 能力
6. 核心制度与工件清单
- 内容政策(版权/隐私/合规/品牌/可访问性)
- 内容模型规范(类型、字段、关系)、词表/标签/分类法
- 工作流程与审批矩阵、SLA、留痕规范
- 多语与翻译标准(术语库、翻译记忆库、质量门禁)
- 归档/下架策略与版本治理
- 数据指标字典与看板定义
- RACI 与授权策略(角色、权限、审计)
7. 能力-工具映射(参考)
- L1–L2:文档协作平台 + 轻量 CMS(如入门级 Headless CMS)、基础审批与模板
- L2–L3:Headless CMS + DAM + 搜索 + 翻译管理(TMS)+ 基础多渠道分发
- L3–L4:规则引擎/个性化、A/B、CDP/CRM 集成、PIM/MDM 联动、可观测与告警
- L4–L5:AI/ML 能力(自动标签/摘要、质量检测、生成建议、布局适配)、推荐与动态编排
注:选型遵循“内容模型优先、API 优先、可观测优先”的原则,避免单体系统绑定。
8. KPI 指标体系(选型示例)
- 生产效率:平均发布周期、编辑/审核等待时长、一次通过率
- 复用与一致性:复用率、重复内容占比、术语一致性得分
- 质量与合规:合规缺陷率、可访问性通过率、品牌一致性得分
- 分发与触达:多渠道覆盖、搜索可见度(SEO/Schema)、加载与可用性
- 成果与投入:转化/线索贡献、内容消费深度、内容 ROI、单资产全生命周期成本
- 多语运营:翻译周期、复用记忆率、质量扣分率
9. 风险与防控
- 标准落地难:用“强约束点”固化(模板/字段必填/自动校验)
- 工具替代流程:先梳理流程与模型,再落地工具;避免“以工具代流程”
- 多语/多渠道成本失控:强制复用与结构化,中心化翻译资源与术语库
- 合规与溯源:版本留痕/审批审计/自动扫描(PII/版权/品牌)
- 度量黑洞:先小表、后看板;指标字典统一口径
10. 快速落地示例(B2B 官网上线知识中心)
- 目标:6 个月内从 L1→L3
- 路线:
- 月 1–2:评估与模型 v1、RACI、政策草案、轻量审批、模板化上线
- 月 3–4:Headless CMS + DAM + 搜索,词表/标签治理,多渠道发布;KPI 看板首版
- 月 5–6:A/B 与个性化试点,SEO/可访问性全量执行,季度复盘机制固化
- 成果预期:
- 发布周期缩短 30–50%
- 复用率提升到 35–50%
- 合规缺陷率降低 60%+
- 自然搜索流量提升 20–40%
11. 评分到等级的简单计算
- 每维打分 0–5,计算平均分与最低分
- 总体等级 = min(四舍五入的平均分, 最低分+1 的保守上限)
- 目标等级:期望年内将“最低分维度”从 N 提升到 N+1,并拉齐到目标线
12. 可视化与沟通
- 雷达图展示 8 维得分
- 漏斗图展示生产—审核—发布转化率与瓶颈
- 价值看板:投入-产出(成本/产能/效果)月度趋势