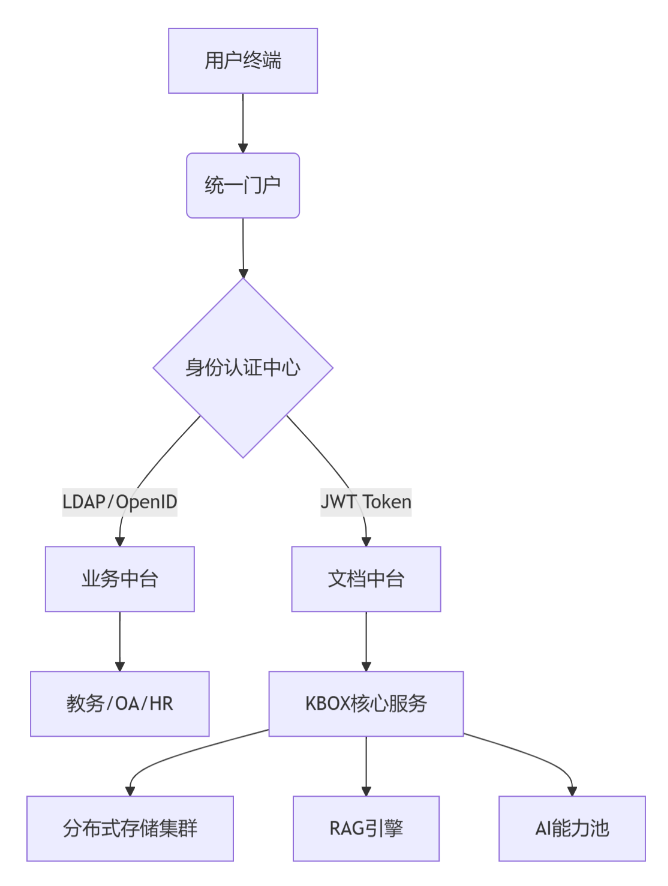
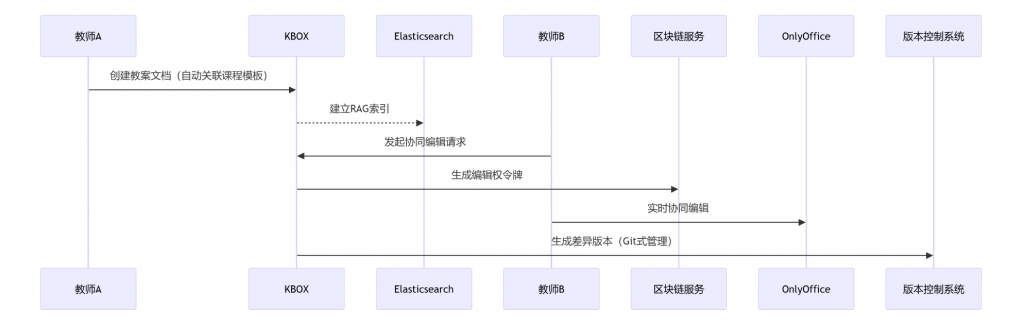
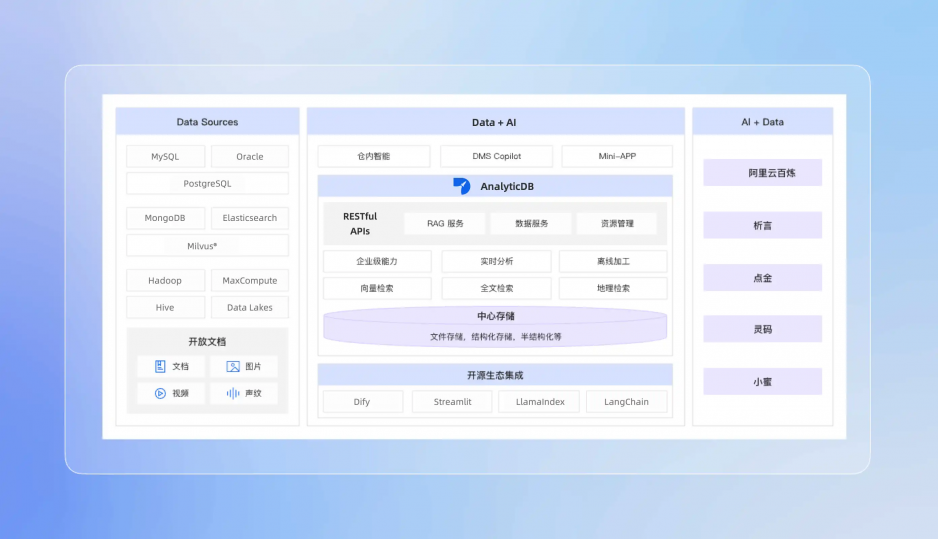
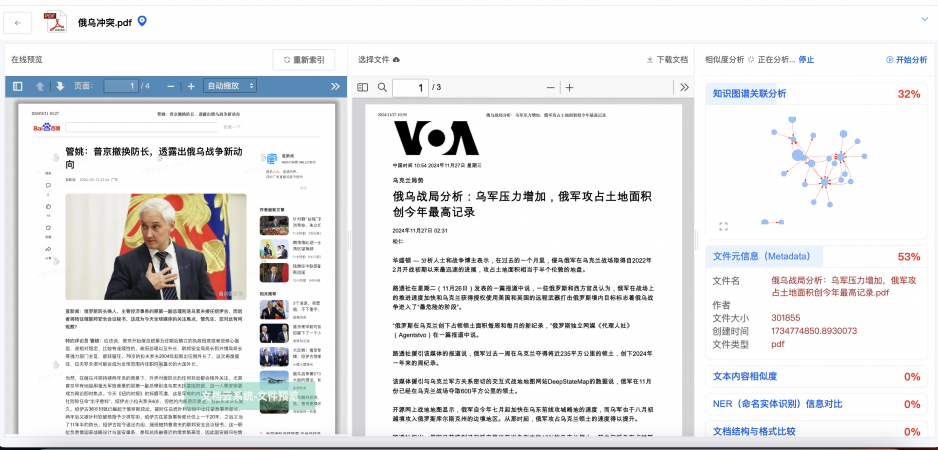
Hadoop、HDFS、Spark 和 Doris 都是大数据领域的关键技术,但它们在功能、应用场景和技术架构上有所不同。以下是对它们的概念解析和它们之间的对比,Flink、Storm 和 Hive 都是大数据生态系统中的重要组成部分,具有不同的功能和应用场景。它们与之前提到的 Hadoop、HDFS、Spark 和 Doris 有一定的重叠和对比性,下面是它们的概念解析及它们之间的对比。:
1. Hadoop
概念:
Hadoop 是一个开源的分布式计算框架,主要用于存储和处理海量数据。它包括两个核心模块:
• HDFS(Hadoop Distributed File System):分布式文件系统,用于大规模数据存储。
• MapReduce:分布式计算模型,用于大规模数据处理。
擅长:
• 存储和处理大规模数据(尤其是批处理数据)。
• 大数据的离线计算任务。
• 提供高容错性和扩展性。
2. HDFS
概念:
HDFS 是 Hadoop 的文件系统,专门为大规模数据存储而设计。它将数据分块存储在多个节点上,通过冗余存储来确保数据的高可用性。
擅长:
• 高效的分布式存储。
• 支持大文件(每个文件可达 TB 级别)。
• 高容错性和高可扩展性,数据块通常复制多个副本。
3. Spark
概念:
Apache Spark 是一个分布式计算框架,提供比 MapReduce 更高效的计算模型,尤其适用于实时流处理和大数据批处理。Spark 可以运行在 Hadoop 的 HDFS 上,也可以独立使用。
擅长:
• 高效的数据处理,尤其是在需要快速计算的情况下。
• 支持批处理和流处理(例如,Spark Streaming)。
• 提供丰富的高级 API,支持机器学习(MLlib)、图计算(GraphX)等高级功能。
4. Doris
概念:
Doris 是一个高性能的分布式 SQL 数据库,最初由百度开发,专注于大数据量的 OLAP(联机分析处理)查询。它采用了分布式存储和计算架构,能处理 TB 到 PB 级别的数据。
擅长:
• 实时 OLAP 查询,适合大规模数据分析。
• 提供高并发、高吞吐量的查询能力。
• 支持 SQL 查询,易于集成到现有数据仓库。
概念:
Apache Flink 是一个开源的流处理框架,主要用于大规模数据流的实时处理。它支持批处理和流处理(批流一体),尤其擅长处理低延迟、实时流数据。
擅长:
• 实时流处理:Flink 最擅长实时处理连续数据流。
• 批流一体:同时支持批处理和流处理的任务,提供统一的编程模型。
• 低延迟与高吞吐:适合低延迟、高吞吐量的场景,如实时监控、实时推荐系统等。
• 容错性:支持状态恢复机制,处理复杂的时间窗口、事件时间等。
2. Storm
概念:
Apache Storm 是一个分布式实时计算框架,用于流数据处理,类似于 Flink,但 Storm 更加注重低延迟和高并发的实时计算任务。
擅长:
• 低延迟实时计算:Storm 是专为实时流处理设计的,能够以毫秒级的延迟处理大量实时数据。
• 高吞吐量:适合需要高速、并行处理的大规模数据流。
• 拓扑结构:通过拓扑的方式对实时计算任务进行定义,每个任务单元称为 Bolt,整个处理流程称为 Topology。
它们之间的关联与对比
• Hadoop 与 Spark:Hadoop 提供了一个分布式存储和计算的基础框架,而 Spark 提供了更高效的计算引擎。Hadoop 的 MapReduce 是 Spark 之前的标准分布式计算框架,但 Spark 在处理速度和功能灵活性上更优,因此许多场景下 Spark 取代了传统的 MapReduce。
• HDFS 与 Spark:HDFS 作为 Hadoop 的分布式文件系统,常与 Spark 一起使用来存储大规模数据集。Spark 通过读取 HDFS 中的数据进行分布式计算。
• HDFS 与 Doris:HDFS 更侧重于数据存储,而 Doris 是一个用于实时数据分析和查询的数据库。Doris 可以作为大数据存储的后端,与 HDFS 一起用于大数据分析。
• Spark 与 Doris:Spark 更侧重于大规模的计算和处理,而 Doris 是一个数据库,专注于 OLAP 查询。在实际应用中,Spark 可以用来做复杂的计算任务后将结果存入 Doris 进行高效查询和分析。
总结
• Hadoop:适用于批量数据存储和处理,尤其适合大数据的离线计算任务。
• HDFS:为大数据提供高效的分布式存储。
• Spark:适用于需要快速计算的批处理和流处理任务,支持更复杂的计算和分析。
• Doris:适用于实时大数据分析,尤其在 OLAP 场景下表现出色。
它们之间的对比性主要体现在存储、计算和查询效率方面,Spark 和 Doris 都可以处理大规模的数据,但 Spark 更侧重计算,而 Doris 则更注重快速查询。
Flink、Storm 和 Hive 都是大数据生态系统中的重要组成部分,具有不同的功能和应用场景。它们与之前提到的 Hadoop、HDFS、Spark 和 Doris 有一定的重叠和对比性,下面是它们的概念解析及它们之间的对比。
1. Flink
3. Hive
概念:
Apache Hive 是一个数据仓库工具,主要用于大数据存储和查询。它基于 Hadoop 架构,能够将 SQL 查询转化为 MapReduce 任务执行,提供了类似 SQL 的查询语言(HiveQL),方便用户进行大数据分析。
擅长:
• 大规模数据分析:适合进行批量数据的离线分析,尤其是需要与 HDFS 配合使用时。
• SQL 风格查询:提供类似 SQL 的查询语言,使得不熟悉 MapReduce 编程的用户也能处理大数据。
• 数据仓库功能:Hive 支持将大数据存储在 HDFS 上,并对其进行有效的管理和查询,适合 ETL 过程中的数据清洗和转换。
它们之间的关联与对比
• Flink 与 Storm:两者都属于实时流处理框架,但 Flink 的优势在于其更为强大的流处理能力、批流一体的支持和更高的容错性,而 Storm 更适合超低延迟的实时计算任务,且相对而言,Storm 的开发和运维难度较大。Flink 更加现代化,能支持复杂的事件时间和窗口操作。
• Flink 与 Hive:Flink 是流处理框架,而 Hive 是一个批处理查询系统。两者可以结合使用,Flink 可以实时处理流数据,并将处理结果存储到 Hive 中以供后续的离线分析和查询。Flink 更适合实时计算,而 Hive 适用于批量数据查询和分析。
• Storm 与 Hive:Storm 和 Hive 的功能差异较大,Storm 用于处理实时数据流,注重低延迟和高吞吐量,适合实时计算;而 Hive 用于批量查询和分析大规模数据,适合离线数据处理。两者也可以结合,Storm 可以处理实时数据流,结果写入 Hive 中供后续查询分析。
• Hive 与 HDFS:Hive 是在 Hadoop 生态中用于数据查询的工具,通常与 HDFS 一起使用。Hive 通过 HDFS 存储数据,并通过 SQL 类似的语言进行查询分析。Hive 适合大数据量的离线处理,不适用于实时计算。
总结
• Flink:适用于实时数据流处理,支持低延迟、批流一体的任务,能够处理复杂的事件时间和窗口计算。
• Storm:专注于超低延迟、高并发的实时流计算任务,适合实时数据流的快速处理。
• Hive:适用于大数据的批量处理和离线分析,特别是在 SQL 查询和数据仓库功能上有优势,常与 HDFS 配合使用。
这些工具在大数据系统中各自担任不同的角色,可以根据业务需求选择合适的框架进行组合使用。
为了更清晰地展示这些技术的概念、用途及其对比关系,以下是两张表格。第一张表格对比了与存储、计算相关的技术,第二张表格则对比了与查询与分析相关的技术。
表格 1:存储与计算相关技术对比
技术 概念描述 主要用途 优势 特点与对比
HDFS Hadoop 分布式文件系统,专为大规模数据存储设计。支持高容错和扩展性。 数据存储,分布式文件系统 高容错性、分布式存储、支持大规模数据存储 HDFS 主要关注于数据存储,数据以块形式分布在多个节点,提供高可用性和扩展性。与计算框架(如 Spark、Flink)结合使用。
Hadoop 开源的分布式计算框架,包含 MapReduce 和 HDFS,适合批处理和存储大数据。 大数据存储与批量计算 高容错性、扩展性好,批量处理能力强 Hadoop 更适合离线批处理和大规模数据存储,MapReduce 是计算引擎,但效率低于 Spark,逐步被 Spark 所取代。
Spark 高效的大数据计算引擎,支持批处理和流处理(实时计算),能在 HDFS 上运行。 数据计算,支持批处理和实时计算 批流一体,高性能,支持机器学习、图计算 Spark 支持内存计算,比 MapReduce 更快,支持流处理和批处理,适合大规模数据的实时计算,比 Hadoop 更加灵活和高效。
Flink 分布式流处理框架,支持实时流数据处理和批流一体计算。 实时流处理、批处理 低延迟,高吞吐量,支持事件时间和复杂的时间窗口 Flink 与 Spark 类似,但更加专注于实时流处理,且支持复杂的时间语义,适合低延迟的实时分析,处理能力强。
Storm 实时流处理框架,主要用于高并发、低延迟的数据流处理。 实时流处理,低延迟计算 极低的延迟,高吞吐量,适合超实时数据流处理 Storm 对实时流处理的延迟要求极低,适合高速、并行计算,但相比 Flink,功能较为简单,缺乏复杂的时间处理能力。
表格 2:查询与分析相关技术对比
技术 概念描述 主要用途 优势 特点与对比
Hive 基于 Hadoop 的数据仓库工具,提供 SQL 类似的查询语言(HiveQL),用于批量查询。 大数据分析与查询,SQL 风格查询 支持 SQL,易于集成,适合批量处理数据 Hive 是一个数据仓库工具,适用于批量数据的分析,查询效率较低,适合离线分析。与 MapReduce 和 HDFS 配合使用,缺乏实时计算能力。
Doris 高性能的分布式 SQL 数据库,适合大规模的 OLAP 查询。 实时数据分析与查询 高吞吐量、高并发、实时查询 Doris 专注于 OLAP 查询,适合大规模数据的快速查询,适合做数据仓库和实时分析,查询性能优于 Hive,且支持高并发查询。
总结
• 存储与计算:
• HDFS 和 Hadoop 主要是用来存储和处理大规模数据,适合批处理任务。
• Spark 和 Flink 都能处理大数据计算,前者强调高效的批处理与流处理,而后者专注于低延迟的实时流处理。
• Storm 更侧重于实时流计算,特别适用于低延迟需求。
• 查询与分析:
• Hive 是传统的批量查询工具,适合在大数据存储基础上进行离线分析,性能较为平缓。
• Doris 是一个专注于 OLAP 的高性能数据库,能够提供实时查询能力,适合做高并发的实时数据分析。
为了更清晰地展示这些技术的概念、用途及其对比关系,以下是两张表格。第一张表格对比了与存储、计算相关的技术,第二张表格则对比了与查询与分析相关的技术。
表格 1:存储与计算相关技术对比
技术 概念描述 主要用途 优势 特点与对比
HDFS Hadoop 分布式文件系统,专为大规模数据存储设计。支持高容错和扩展性。 数据存储,分布式文件系统 高容错性、分布式存储、支持大规模数据存储 HDFS 主要关注于数据存储,数据以块形式分布在多个节点,提供高可用性和扩展性。与计算框架(如 Spark、Flink)结合使用。
Hadoop 开源的分布式计算框架,包含 MapReduce 和 HDFS,适合批处理和存储大数据。 大数据存储与批量计算 高容错性、扩展性好,批量处理能力强 Hadoop 更适合离线批处理和大规模数据存储,MapReduce 是计算引擎,但效率低于 Spark,逐步被 Spark 所取代。
Spark 高效的大数据计算引擎,支持批处理和流处理(实时计算),能在 HDFS 上运行。 数据计算,支持批处理和实时计算 批流一体,高性能,支持机器学习、图计算 Spark 支持内存计算,比 MapReduce 更快,支持流处理和批处理,适合大规模数据的实时计算,比 Hadoop 更加灵活和高效。
Flink 分布式流处理框架,支持实时流数据处理和批流一体计算。 实时流处理、批处理 低延迟,高吞吐量,支持事件时间和复杂的时间窗口 Flink 与 Spark 类似,但更加专注于实时流处理,且支持复杂的时间语义,适合低延迟的实时分析,处理能力强。
Storm 实时流处理框架,主要用于高并发、低延迟的数据流处理。 实时流处理,低延迟计算 极低的延迟,高吞吐量,适合超实时数据流处理 Storm 对实时流处理的延迟要求极低,适合高速、并行计算,但相比 Flink,功能较为简单,缺乏复杂的时间处理能力。
表格 2:查询与分析相关技术对比
技术 概念描述 主要用途 优势 特点与对比
Hive 基于 Hadoop 的数据仓库工具,提供 SQL 类似的查询语言(HiveQL),用于批量查询。 大数据分析与查询,SQL 风格查询 支持 SQL,易于集成,适合批量处理数据 Hive 是一个数据仓库工具,适用于批量数据的分析,查询效率较低,适合离线分析。与 MapReduce 和 HDFS 配合使用,缺乏实时计算能力。
Doris 高性能的分布式 SQL 数据库,适合大规模的 OLAP 查询。 实时数据分析与查询 高吞吐量、高并发、实时查询 Doris 专注于 OLAP 查询,适合大规模数据的快速查询,适合做数据仓库和实时分析,查询性能优于 Hive,且支持高并发查询。
总结
• 存储与计算:
• HDFS 和 Hadoop 主要是用来存储和处理大规模数据,适合批处理任务。
• Spark 和 Flink 都能处理大数据计算,前者强调高效的批处理与流处理,而后者专注于低延迟的实时流处理。
• Storm 更侧重于实时流计算,特别适用于低延迟需求。
• 查询与分析:
• Hive 是传统的批量查询工具,适合在大数据存储基础上进行离线分析,性能较为平缓。
• Doris 是一个专注于 OLAP 的高性能数据库,能够提供实时查询能力,适合做高并发的实时数据分析。