目标读者:单位技术负责人
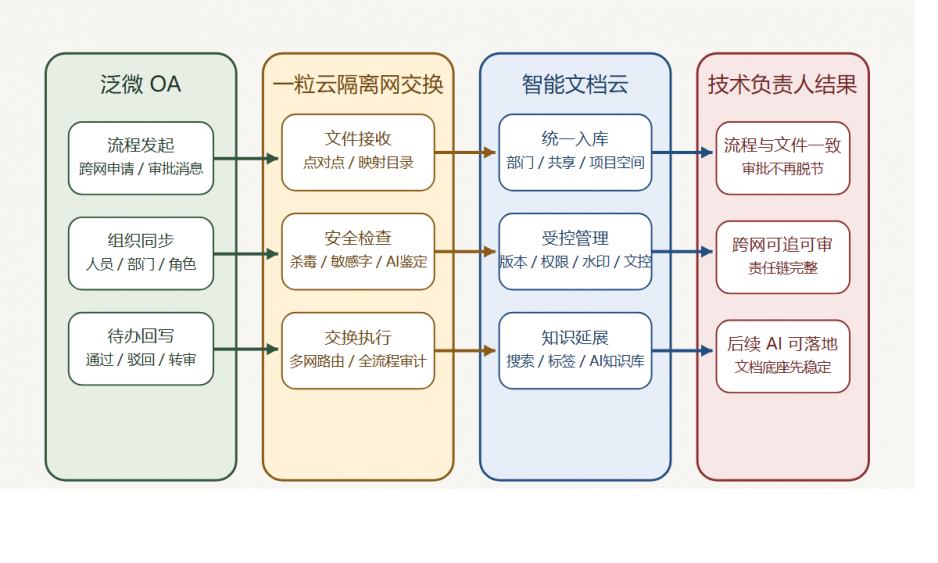
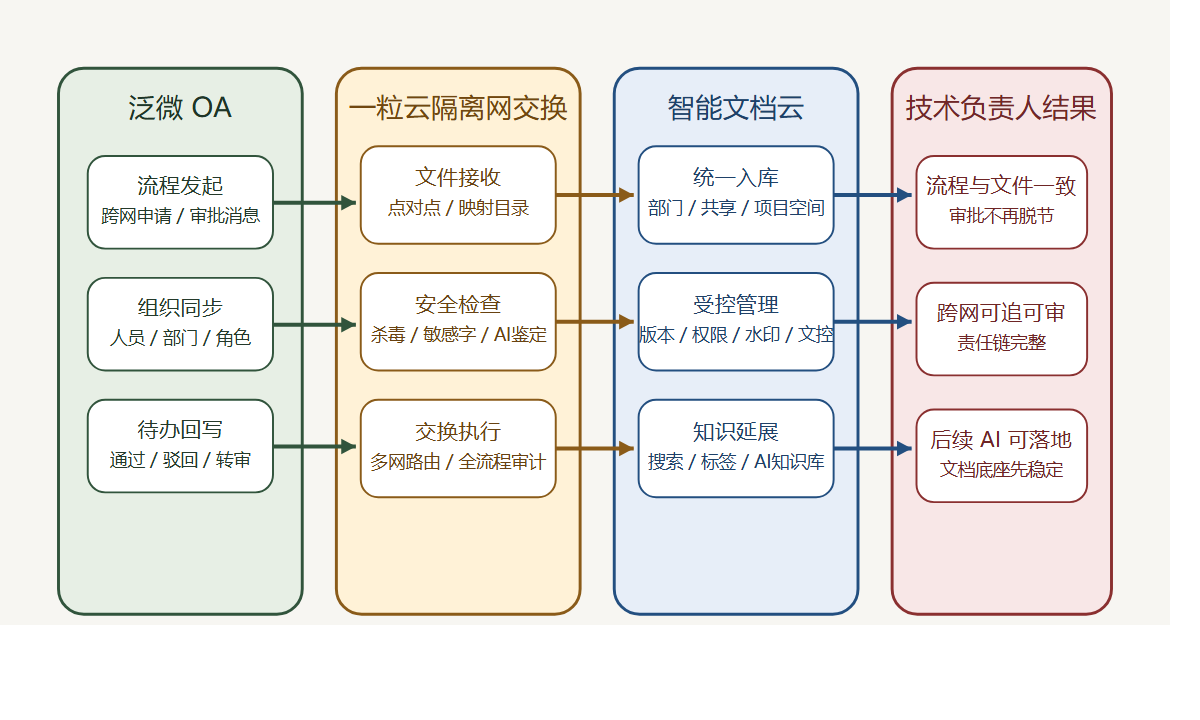
联动品牌:泛微 OA
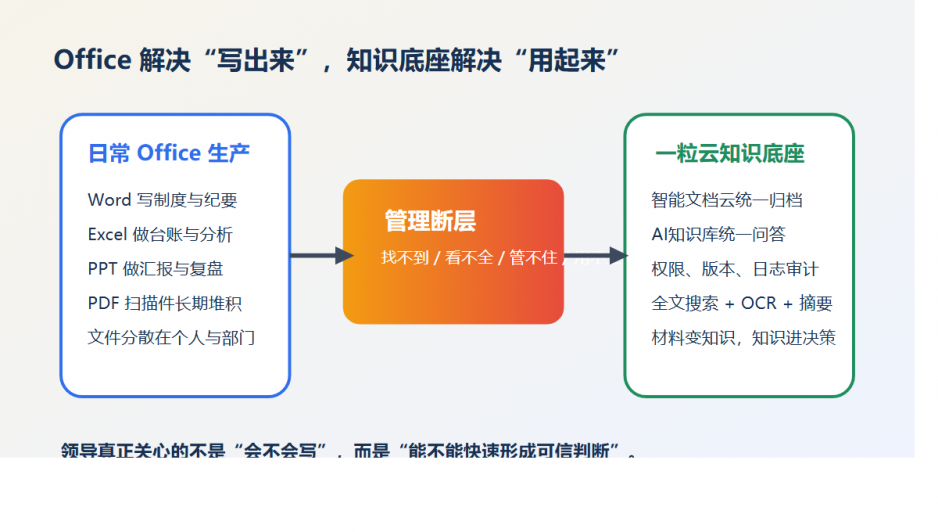
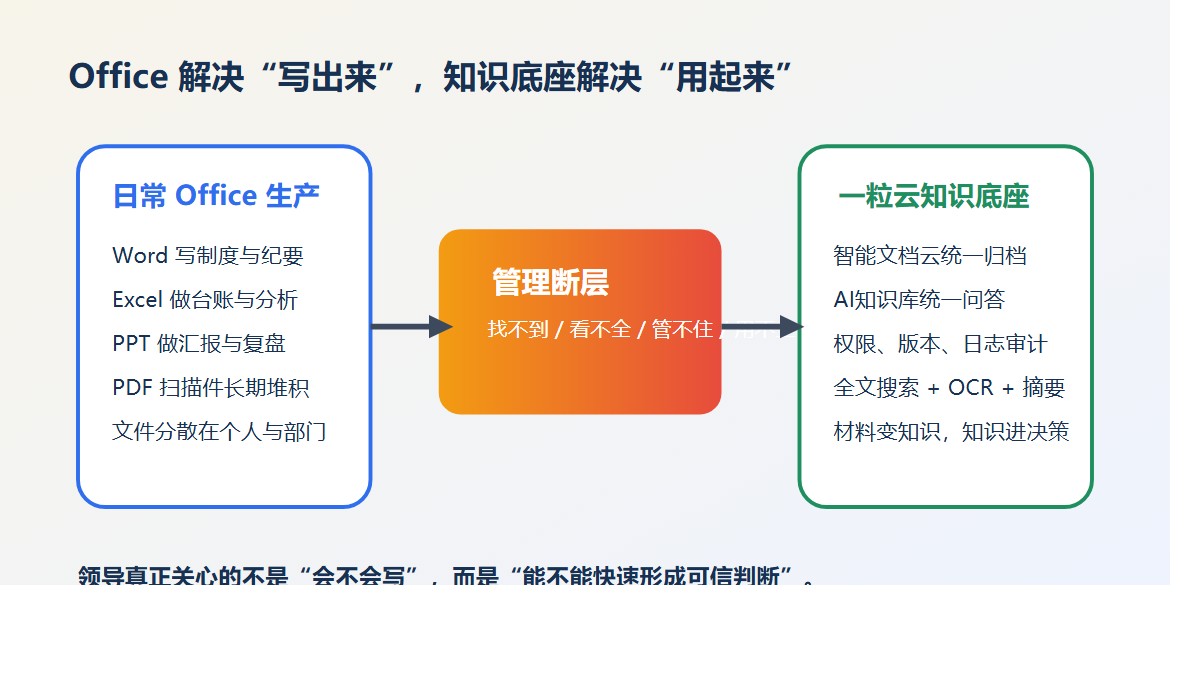
主推方案:一粒云 隔离网文件安全交换 + 智能文档云
延展产品:企业网盘、ISO文控、AI知识库、智能文件汇聚平台
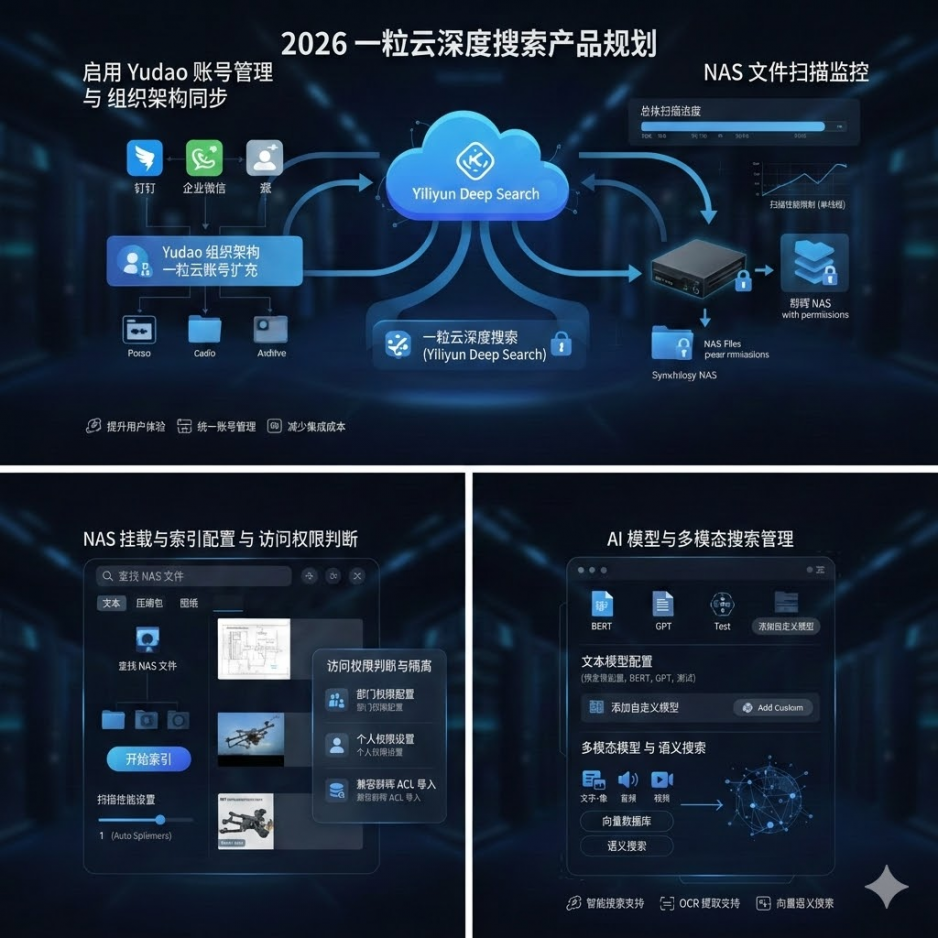
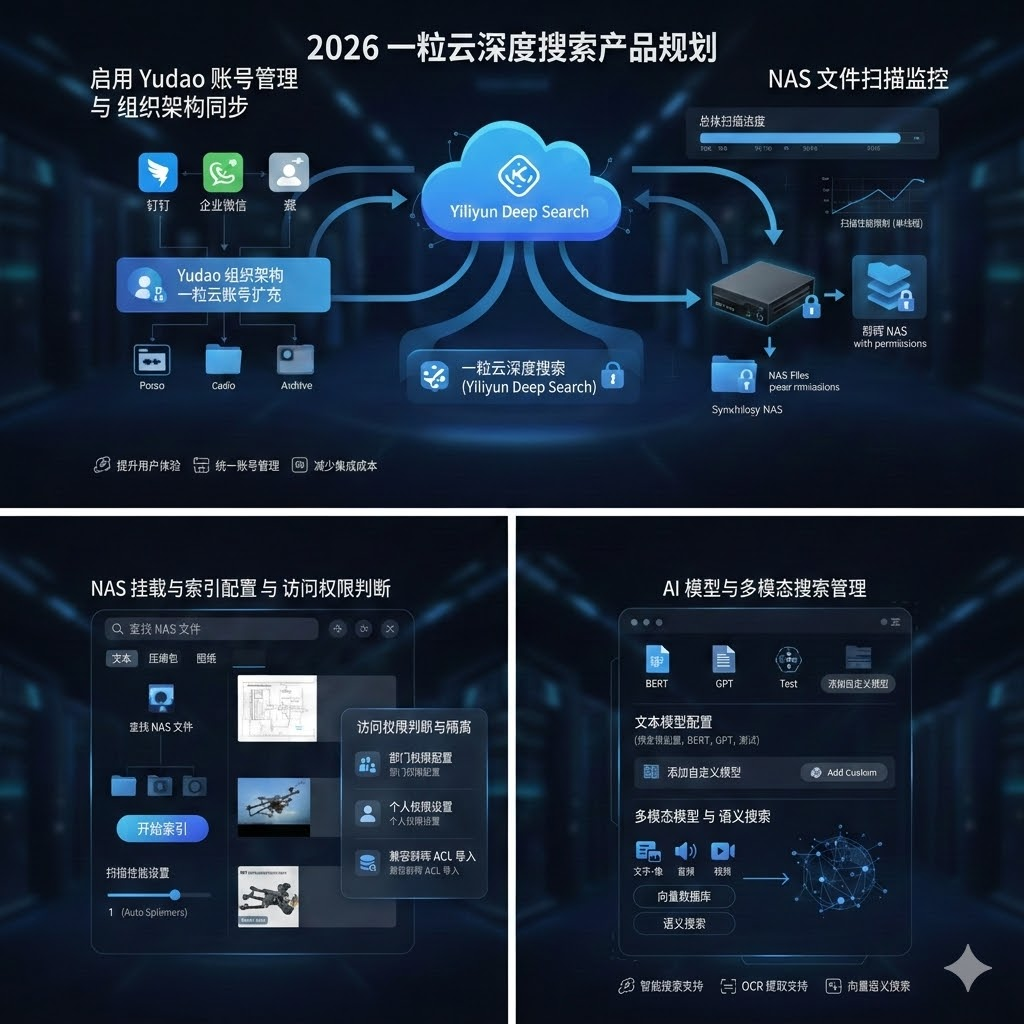
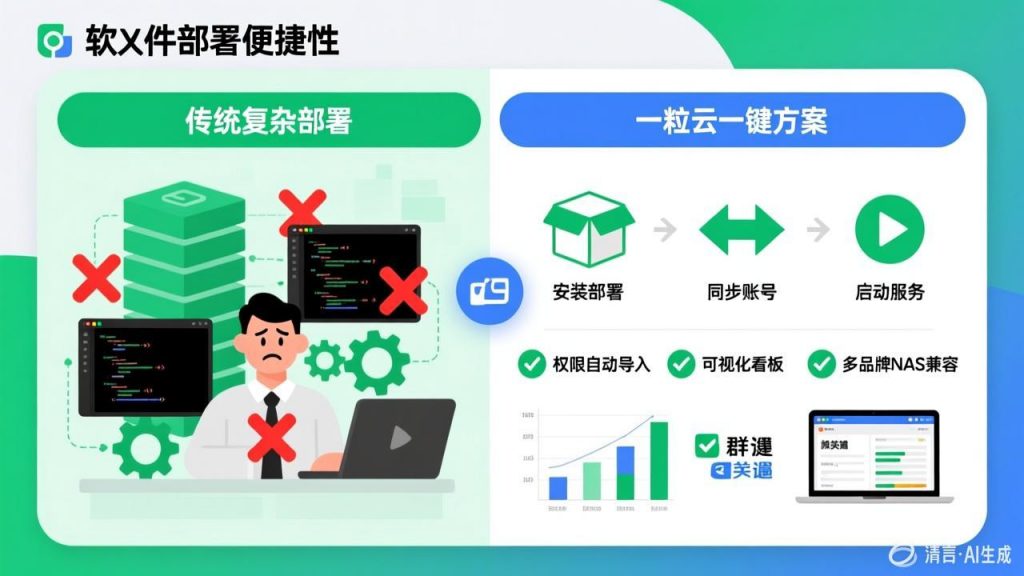
资料显示,一粒云成立于 2015 年,70%+ 为研发人员,全国有 20+ 区域分销渠道,覆盖政府、教育、金融、医疗、制造等行业;公开材料还提到其支持 100+ 文件格式在线预览、13 种原子权限、9 个默认角色,并可对接 ERP / OA / AD / 钉钉 / 企业微信 等系统。隔离网白皮书中还给出过一组数据:在 4000万 文本压缩包、160 个特征下,新算法由 20小时 缩短到 6分钟,速度提升 200倍,准确率 >90%。
很多单位技术负责人都有过这种时刻。
泛微 OA 已经上线。
流程能发起、能审批、能催办。
网闸也有。
隔离网络也分了。
按理说,文件应该已经“可控”了。
可现实是,只要碰到跨网文件,大家还是会下意识地找人盯。
哪个目录能发?
这份文件过没过审?
交换过去的是不是最终版?
进了目标网以后,谁来归档?
事后审计时,能不能把审批单、文件版本、下载记录串起来?
这就是很多单位现在最真实的矛盾。
流程在线了。
文件却还没有真正进入闭环。
而只要文件闭环没建立,技术负责人就会一直卡在两个角色之间:
- 一边要对业务说“流程不能拖”
- 一边要对安全和审计说“责任必须说得清”
问题不在泛微 OA。
问题在于,OA 解决的是“流程流转”,但跨网文件需要的是“审批、检查、摆渡、入库、审计”整条业务链。
先把话说透:为什么泛微 OA 上得越深,技术负责人反而越容易被跨网文件拖住?
因为 OA 管的是“事”,文件跨网管的是“对象”。
泛微 OA 非常适合做:
- 申请发起
- 节点审批
- 人员组织同步
- 待办提醒
- 流程追踪
但一旦文件穿越办公网、研发网、生产网、专网这些边界,技术负责人真正要面对的,不只是流程节点,而是更细的对象级问题:
- 这次审批通过的,到底是哪一份文件。
- 这份文件过网前,做没做病毒查杀和敏感内容检查。
- 文件进目标网络后,是落到了统一空间,还是又回到个人电脑和临时目录。
- 后面有人下载、替换、转发时,是否还能继续追溯。
这就是为什么很多项目看起来“审批都在线”,实际跨网依旧靠人工兜底。
审批单在 OA 里。
文件在共享盘里。
版本在某台电脑上。
交换记录又在另一套系统里。
到了最后,技术负责人只能扮演“人工粘合剂”。
真正的问题,不是少一个审批节点,而是少一条文件闭环
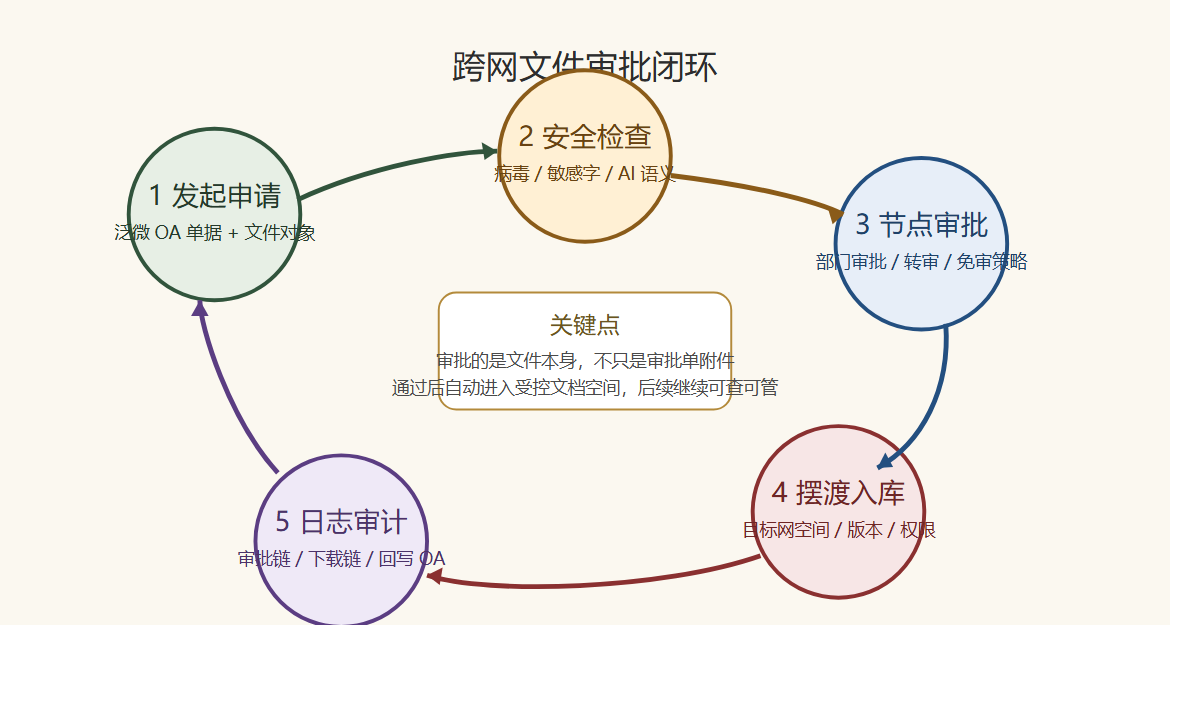
如果把跨网文件当作一个完整业务对象来看,它至少应该经过 5 个动作:
- 发起申请
- 内容检查
- 节点审批
- 摆渡入库
- 全流程审计
很多单位现在其实只做到了第一步和第三步。
也就是“有人申请”“有人审批”。
但第二步、第四步、第五步经常是断的。
白皮书里对传统做法的判断很直接:
U 盘、中间机、单纯网闸摆渡,最大的缺陷不是“不能传”,而是只能解决文件物理位置移动,不能解决哪些文件可以同步、哪些人有权限操作、同步后应该如何处理。
这句话对技术负责人特别重要。
因为它说明一个事实:
文件跨网不是传输问题,而是治理问题。
一粒云这套方案,为什么更适合补在泛微 OA 后面?
不是因为它要替代 OA。
恰恰相反,是因为它愿意把自己放在“文件治理层”。
资料里已经明确提到:
- 一粒云支持与
泛微 / 蓝凌 OA打通审批插件 - 支持
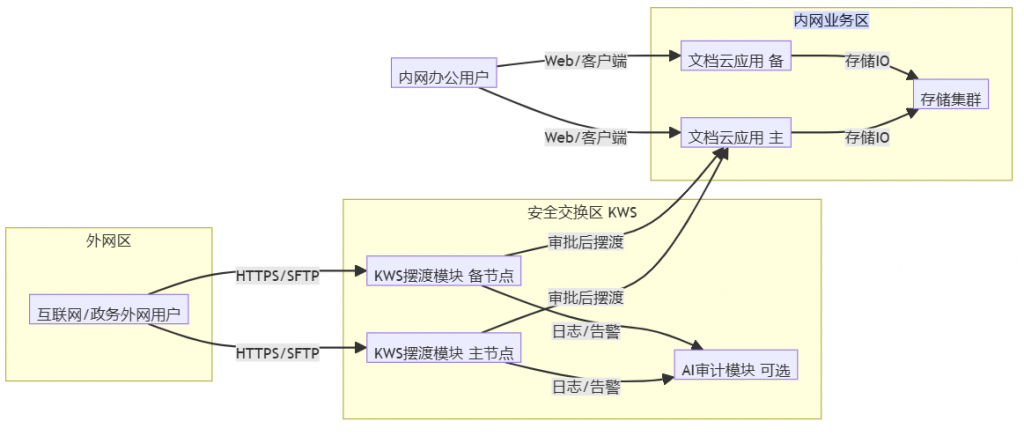
2~4个隔离网络 - 支持三区交换模型,不直接连通隔离网络
- 支持六大模块:
网络与路由配置、自定义数据交换、自定义审批流程、网盘操作模式、内嵌安全模块、全流程日志审计 - 支持病毒查杀、敏感字检测、AI 语义识别、图片 OCR
- 支持点对点发送、自动文件夹映射、部门默认审批管理员、转审、交叉审批
把这些能力和泛微 OA 放在一起看,就会发现它的价值非常明确:
泛微 OA 继续做熟悉的流程入口,一粒云负责把文件对象接住,并且让它跨网以后仍然处于受控状态。
这意味着技术负责人终于能同时满足三件事:
- 不破坏现有 OA 使用习惯
- 不牺牲隔离网络边界
- 不让文件在跨网后继续散落失控
对技术负责人来说,最核心的不是“能不能交换”,而是“交换后还算不算系统资产”
很多跨网项目失败,不是因为摆渡不成功。
而是因为摆渡成功以后,文件又掉回了无序状态。
这类场景非常常见:
- 研发文件审批通过了,最后只是在目标网某个临时目录里躺着
- 外部资料导入内网了,但没人给它定版本、定权限、定分类
- 文件和审批单分离,过一段时间后谁都说不清“当时通过的是哪版”
这时候,技术负责人最怕的不是“这次没传过去”,而是这次传过去了,但半年后仍然无法复盘。
一粒云的优势就在于,交换不是终点。
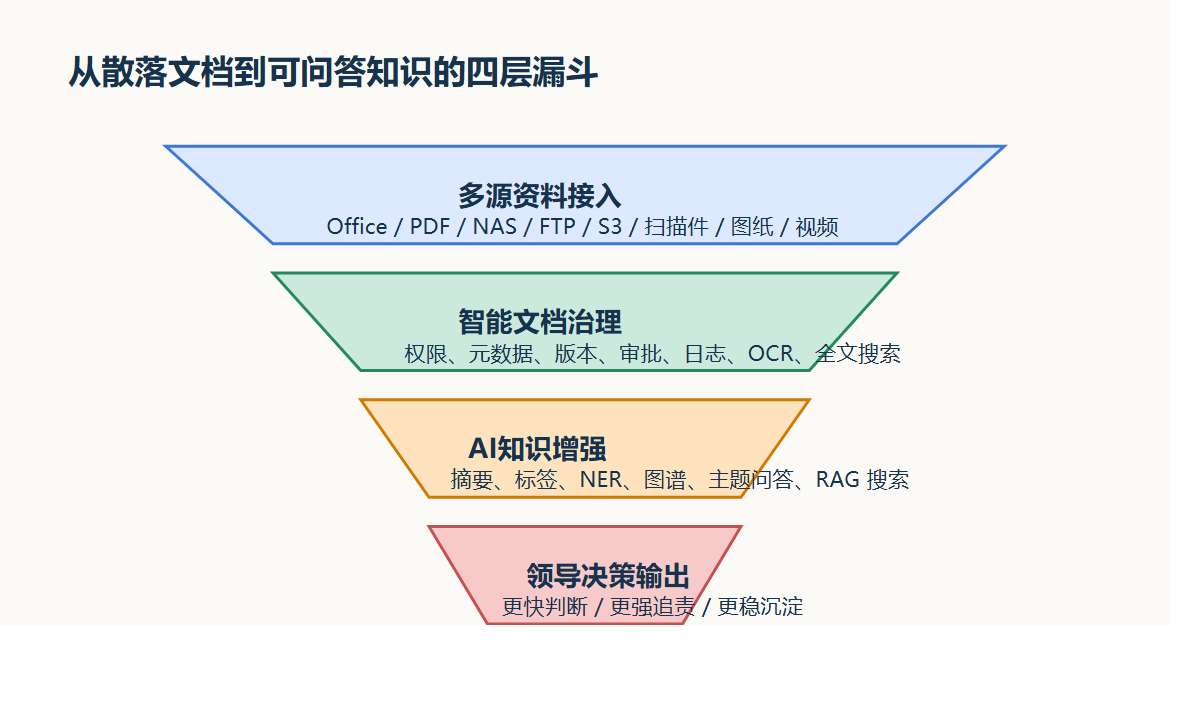
文件通过检查和审批后,还能继续进入智能文档云:
- 落入部门空间、共享空间或项目空间
- 继续受
13种原子权限和9个默认角色控制 - 继续走版本管理、水印、日志审计、回收站、文控策略
- 支持全文搜索、标签、元数据、归类检索
这一步对技术负责人极其关键。
因为它把“跨网行为”接到了“文档全生命周期治理”上。
今天解决的是摆渡。
明天留下的是可搜索、可追溯、可复用的资产。
为什么说这是技术负责人最容易拿结果的一个切入点?
因为它既能解决当下问题,又能给后续建设打底。
第一层价值:先止血
先把最高风险的一条跨网链收住。
例如:
- 办公网到生产网的工艺文件
- 外部供应商到研发网的样件资料
- 办公网到专网的制度文件与项目资料
- 分支单位向总部提交的敏感材料
只要这条链一收住,技术负责人就能立刻减少大量人工盯流程、人工搬文件、人工查版本的工作。
第二层价值:再补责权边界
资料中提到,一粒云支持必审和免审开关、二级审批、转审、部门管理员规则、内外网成员交叉审批。
这意味着审批不是只能“一刀切”,而是可以按部门、目录、场景做策略化配置。
对技术负责人来说,这意味着:
- 高风险目录可以强审
- 低风险目录可以提效
- 文件和人不再只是粗粒度绑定
- 责任边界终于能做细
第三层价值:为 AI 和知识化做准备
现在很多单位都在谈 AI。
但如果底层文件还是散在共享盘、OA 附件和个人电脑里,AI 很快就会变成演示项目。
一粒云资料里已经把全文搜索、摘要、标签、分类分级、NER、知识图谱、统一 RAG 搜索门户列得很清楚。
这意味着技术负责人可以先把文件底座做稳,再考虑知识库、问答、推荐。
顺序对了,AI 才不是空转。

如果现在就要立项,技术负责人最该用什么逻辑去说服领导和业务?
不要从“我要上一套新系统”开始讲。
那样很容易被理解成重复建设。
更稳的表达应该是:
我们不是在补一个工具,而是在补 OA 之后缺失的文件闭环。
具体可以这样讲:
对领导层:
这件事解决的是责任链。
审批单、检查记录、交换结果、入库位置、后续下载都能串起来,审计时不再靠人工拼证据。
对业务部门:
这件事解决的是效率。
不再需要在 OA、共享盘、邮件、临时目录之间来回折返,审批通过后文件自动进入目标空间,后面的人直接用受控版本。
对安全与运维团队:
这件事解决的是边界。
隔离网继续隔离,但跨网文件终于有了标准路径,不再逼着大家走线下绕路。
一个更现实的问题:为什么这类项目更适合现在推进,而不是再等等?
因为过去很多单位还能靠人扛。
现在不行了。
原因有三个。
1. 网络越来越多,文件跨网次数只会增加
办公网、研发网、生产网、视频网、专网、下属单位边界越来越细。
一旦业务继续增长,人工摆渡只会更不可控。
2. 审计与合规要求越来越细
以前能证明“审批过了”就算过关。
现在更看重:
- 审批的是哪份文件
- 传输前检查做了什么
- 传输后落到了哪
- 谁又访问了它
3. AI 建设开始倒逼底层文档治理
如果技术负责人明年还要承担知识库、内容搜索、智能问答这类建设任务,那么今年先把跨网文件和统一入库打通,反而是最划算的动作。
实施上怎么做更稳?不要一上来铺满全单位
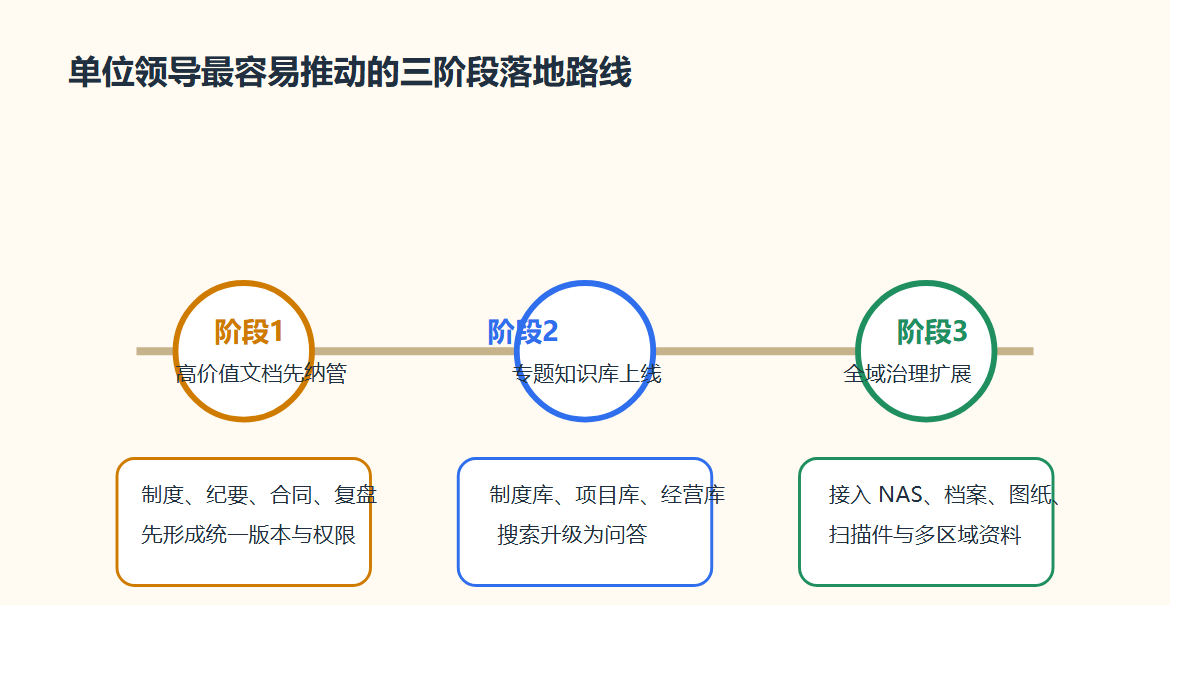
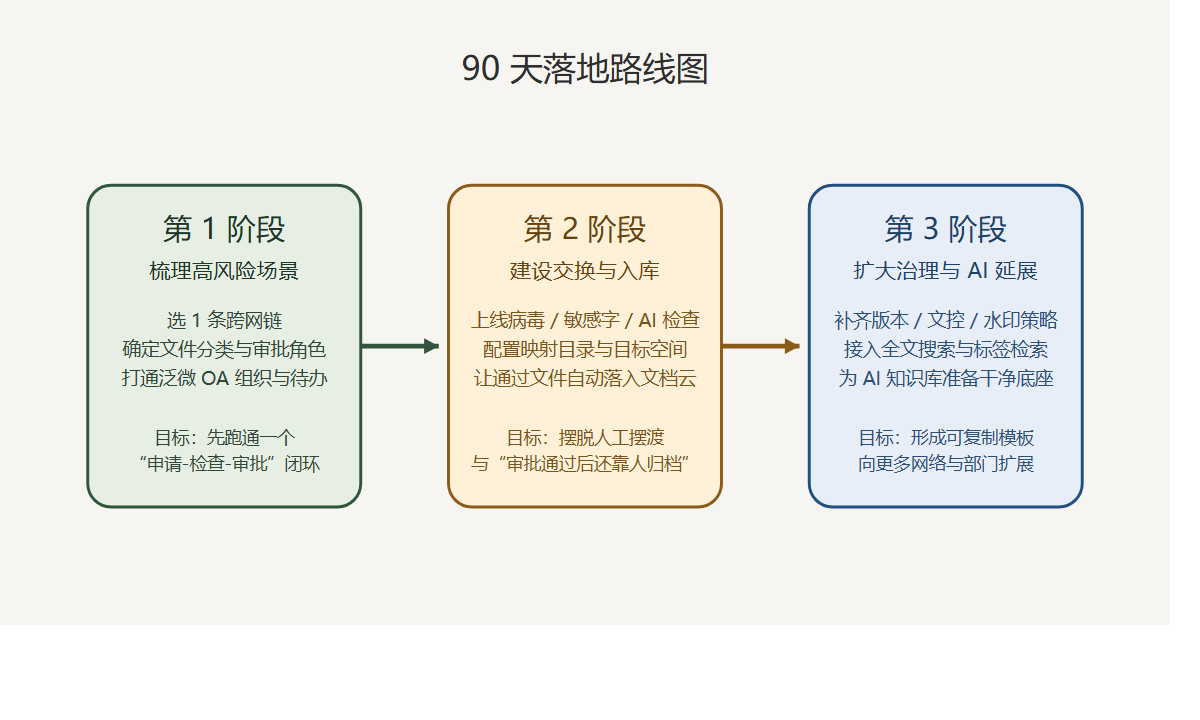
先做 90 天闭环,比一口气做“大平台”更现实。
建议分三步:
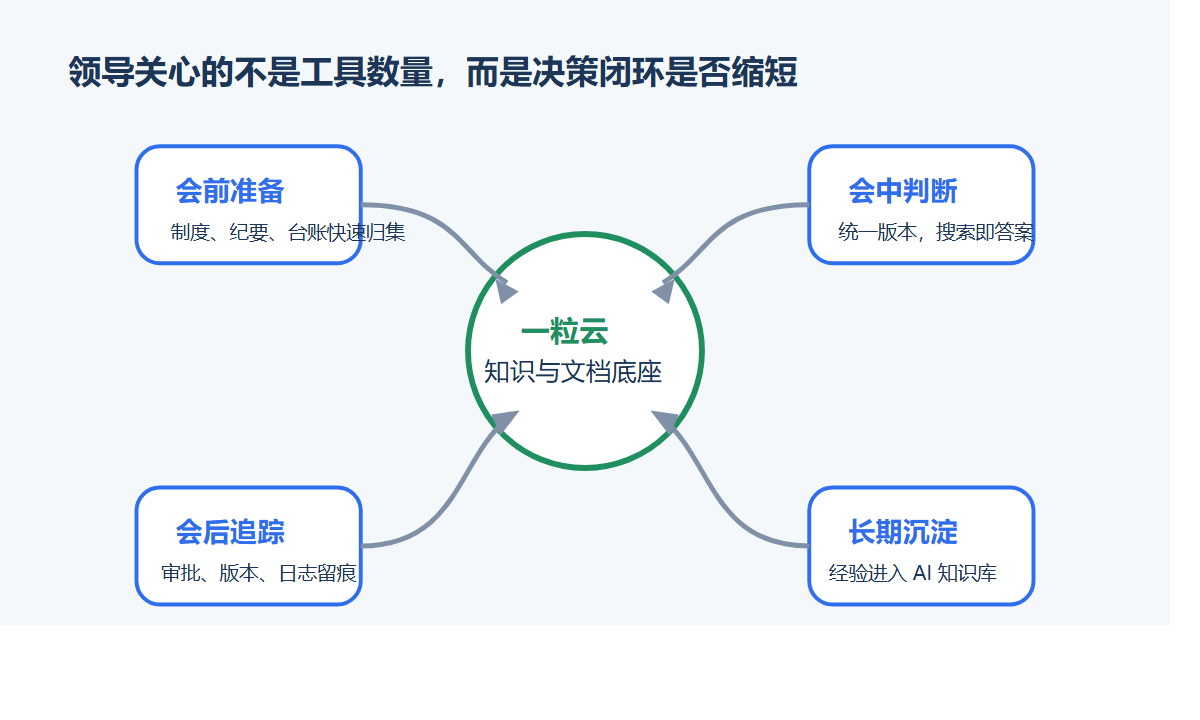
- 先选
1条最高频、最高风险的跨网链。 - 先打通泛微 OA 组织、审批待办和文件交换策略。
- 让通过文件自动进入智能文档云,补齐版本、权限和审计。
做完这三步,技术负责人就能先拿到一个非常直观的结果:
文件跨网不再只是“传过去”,而是“被系统完整接住”。
还有一个技术负责人不该忽略的信息:这类项目更适合集成推进
从渠道体系文件能看出,一粒云不同模块的渠道合作空间大致在 20%~65% 区间。
这意味着,对需要本地化实施、OA 对接、信创环境适配、软硬一体交付的项目来说,它更容易与区域服务商、总包商、集成商形成联合推进模式。
这点很现实。
因为跨网项目很少是单点软件采购。
往往会牵涉:
- OA 审批联动
- 目录与权限设计
- 网络边界规划
- 软硬一体交付
- 上线培训与运维交接
渠道和交付体系能不能跟上,往往直接决定项目成败。
最后一句:技术负责人真正缺的,不是再盯一次流程,而是把文件从“审批附件”升级成“系统对象”
泛微 OA 已经把“事怎么批”做得很成熟。
下一步真正需要补的是:
文件怎么检查、怎么过网、怎么入库、怎么继续受控。
这正是一粒云 隔离网文件安全交换 + 智能文档云 最适合补位的地方。
它不是替代 OA。
而是让 OA 后面的文件链条终于闭上。
如果你现在也是单位技术负责人,可以先自查 4 个问题:
- 你们单位跨网审批通过后,文件是不是自动进入统一受控空间?
- 审计时,能不能快速串起审批单、交换记录、文件版本和访问日志?
- 关键目录的跨网策略,是不是按风险分级配置,而不是一刀切?
- 你们现在谈的 AI 知识库,底层文件是不是已经具备统一入口和统一权限?
如果这 4 个问题里有 2 个答不上来,就说明你现在缺的不是更多审批,而是这条闭环。
欢迎在评论区聊聊,你们单位现在最卡的是哪一步:
A. OA 审批和文件对象脱节
B. 文件过网后没有统一入库
C. 审计时日志串不起来
D. 想做 AI,但底层文件还没治理好
关注 一粒云,下一篇继续拆:
为什么很多单位已经做了等保和网络隔离,真正拉不开差距的,却是文件治理这层基础设施。