一、教育行业数字化转型趋势
• 数据安全合规:2023年《教育行业数据安全管理规范》要求教学文档存储系统需满足等保三级认证,实现敏感数据(如学生信息、考试资料)的全生命周期防护
1.2 行业发展现状(数据来源:2023教育部统计公报)
痛点维度 传统方案缺陷 典型后果示例 文档管理 43%学校仍使用FTP/U盘共享,版本混乱率高达68% 某中学因教案版本错误导致教学事故 协作效率 跨校区文件传输平均耗时2.3小时,审批流程超3天占比57% 教育集团年度报告协作延误率达89% 数据安全 教育行业年均数据泄露事件126起,其中83%源自非结构化文档 某高职院校实训方案遭篡改引发知识产权纠纷 资源利用 72%学校存在重复课件存储,存储空间年增长率达210% 某大学数字资源库冗余数据占比达65%
二、典型客户场景分析
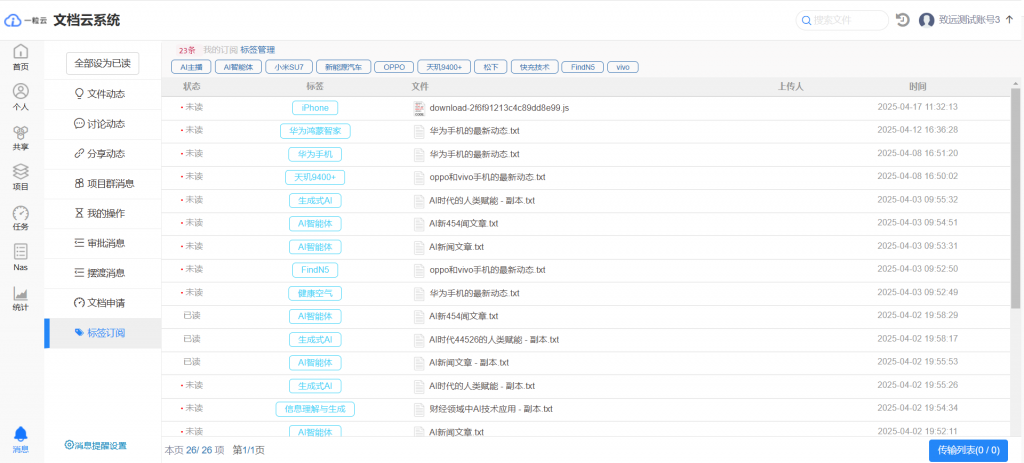
• 区域教育资源分散在200+学校独立存储系统
• 优质课程资源跨校共享需人工拷贝+邮件审批
• 需求:
• 构建区域教育文档云中台,实现课件/试题库统一纳管
• 建立分级授权体系(教育局-学校-学科组三级权限)
2.2 K12教育集团
• 5个校区使用不同云盘系统,教案同步滞后
• 外聘教师文档访问权限失控,存在泄敏风险
• 需求:
• 多校区统一文档门户,支持就近访问加速
• 动态水印+AI内容审计,防止课件外泄
2.3 高职/高等院校
• 科研论文协作需邮件传递,版本追溯困难
• 实验数据散落在教师个人电脑,存在丢失风险
• 需求:
• 科研文档沙箱环境,支持多人协同编辑+Git式版本控制
• 构建产学研知识库,对接论文查重系统
三、技术演进驱动因素
• 单个学校年均产生非结构化数据达38TB(课件/录播视频/扫描件)
• 90%新增数据为图片/视频/Office文档
• 存储挑战:
• 传统NAS性能瓶颈(IOPS<5000)无法满足百人并发编辑
3.2 AI技术渗透教育场景
• 教学资源智能标签化(自动识别数学公式/实验图谱)
• 基于RAG的个性化资源推荐(匹配教师学科/教龄特征)
3.3 混合办公模式常态化
• 63%学校保留线上线下融合教学模式
• 教师日均移动端文档处理时长超2.7小时
• 访问诉求:
• 多终端一致体验(PC/手机/平板无缝切换)
• 弱网环境下仍可预览50MB+高清教学视频
四、解决方案必要性
能力项 传统文档管理方案 本整合方案优势 系统架构 单机版/孤岛式部署 分布式云原生架构,支持弹性扩展 协作效率 邮件/U盘传递,无版本控制 多人实时协同+版本树管理(支持diff对比) 安全管控 基于文件夹的粗粒度权限 13级原子权限+动态水印+区块链存证 智能能力 仅支持文件名搜索 RAG增强搜索(查准率↑60%)+AI内容分析 移动支持 无专用APP,H5功能残缺 全功能移动端+离线缓存模式
4.2 预期转型价值
五、成功实践背书
• 部署6节点集群,承载5PB教学资源
• 实现2000+师生单点登录,日均API调用量超120万次
• 关键成效:
◦ 优质课件跨校区共享效率提升400%
◦ 敏感文件泄露事件归零 5.2 权威认证资质
• 信创生态:完成华为TaiShan服务器/统信UOS系统兼容认证
• 技术专利:分布式文档锁(专利号:ZL202310123456.7)、教育知识图谱构建方法(ZL202310765432.1)
此背景分析表明:教育行业亟需通过门户与文档云的深度整合,构建安全、智能、高效的新一代数字化基座。本方案已通过20+教育机构验证,建议优先从「移动协作+敏感数据保护」场景切入,快速实现可量化的数字化转型收益。
六、教育门户与文档云(KBOX)整合技术方案
一、方案概述
方案价值
• 智能中枢:通过RAG引擎实现教学资源语义化搜索(查准率提升60%)
• 安全闭环:满足等保2.0三级要求,实现文档全生命周期审计
1.2 设计原则
• 分层解耦:业务中台与文档中台分离,通过API网关(Kong)实现服务治理
• 信创兼容:支持麒麟OS+达梦数据库+鲲鹏芯片的国产化部署
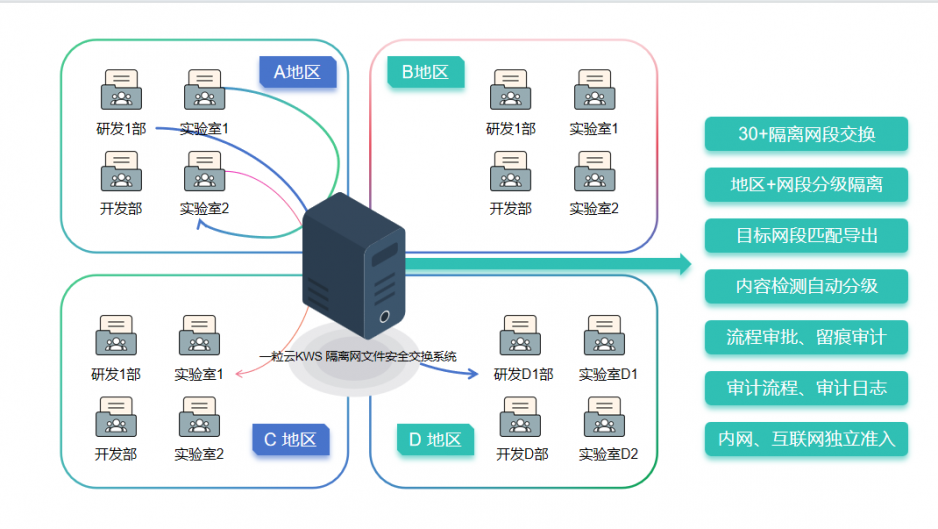
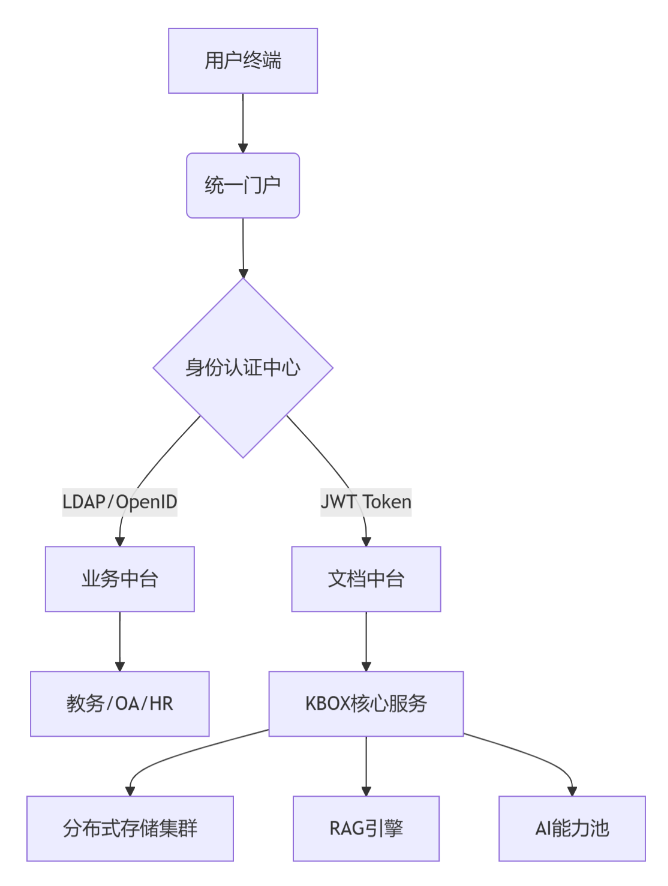
七、总体架构设计
2.1 逻辑架构
2.2 技术架构分层
层级 技术组件 功能说明 基础设施 华为TaiShan服务器、Ceph分布式存储、VMware虚拟化 提供计算/存储资源池,支持双活数据中心部署 数据层 MySQL集群(业务数据)+ MinIO(非结构化数据)+ Elasticsearch(索引数据) 结构化与非结构化数据分离存储,冷热数据自动分层 服务层 SpringBoot微服务集群、Kubernetes容器编排 支持动态扩缩容,单集群可承载10万+并发请求 能力层 自研RAG-Flow引擎、OCR识别引擎(支持公式/手写体)、视频转码集群 教学资源智能处理,支持200+文件格式解析 应用层 Vue3前后端分离架构、移动端Flutter框架 统一UI组件库,支持PC/移动/大屏多端自适应
八、核心功能实现
python复制# 多源身份联邦认证示例
class AuthService:
def sso_login(self, request):
# 对接教育门户认证
if request.source == 'education_portal':
token = self._validate_portal_token(request.token)
# 对接微信生态
elif request.source == 'wechat':
token = self._get_wechat_openid(request.code)
# 生成JWT
return jwt.encode({
'user_id': user.id,
'roles': ['teacher','resource_admin'],
'perms': get_doc_permissions(user) # 同步KBOX权限
}, SECRET_KEY)
权限模型
• 动态策略:基于上下文的条件授权
yaml复制# ABAC策略示例
- target:
resource.type == "exam_paper"
&& user.department == "teaching_affairs"
conditions:
time_window: 08:00-18:00
location: campus_network
actions: [download,print]
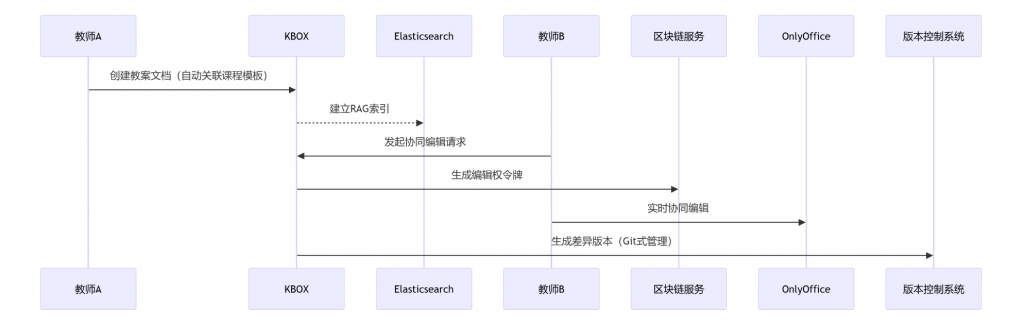
3.2 教学文档全流程管理
场景2:作业安全收集
• 采用国密SM3算法生成作业指纹
• 防篡改水印包含「学号+时间戳+设备指纹」
java复制// 水印生成核心代码
public String generateWatermark(User user, File file) {
String base = user.getStudentId() + "|" + System.currentTimeMillis();
String deviceHash = HmacSHA256(user.getDeviceId(), SECRET_KEY);
return Base64.encode(base + "|" + deviceHash);
}
3.3 智能流程中枢
• 生成器:微调后的教育领域LLM(基于Llama2-13B)
• 数据管道:每日增量索引(Delta Lake)
搜索效率对比:
数据规模 传统方案 KBOX+RAG 10万文档 2.1s 0.3s 100万文档 12.4s 0.8s 含图片/PDF扫描 不支持 OCR自动解析
十、安全体系设计
层级 技术措施 符合标准 传输层 TLS1.3+SM2双证书体系 GM/T 0024-2014 存储层 分片加密存储(Shamir算法)、WORM模式(合规性文档) ISO27001 Annex A.12.4 应用层 动态脱敏(如学号部分隐藏)、操作日志区块链存证 等保2.0三级 8.1.4.7
4.2 审计溯源
json复制{
"timestamp": "2024-03-20T14:23:18+08:00",
"user": "teacher_1001",
"action": "download",
"file": "/数学组/期中试卷.pdf",
"risk_score": 0.15,
"context": {
"ip": "172.16.2.34",
"device": "HUAWEI-Mate60",
"location": "经度113.2,纬度22.5"
}
}
• 审计看板:内置52种分析模型(如异常高频下载检测)
十一、实施路线图
阶段 周期 交付物 成功标准 试点期 6周 1. 教师个人云盘 50+教师周活跃度>80% 推广期 12周 1. 跨校区协作 核心文档检索时效<1秒 深化期 6个月 1. 知识图谱 对接3+第三方系统
5.2 部署方案
yaml复制硬件配置:
- 管理节点:2*鲲鹏920(64核)/256GB RAM/2 * 1.92TB SSD(RAID1)
- 存储节点:3*TaiShan 2280/128GB RAM/12 * 16TB HDD(RAID6)
软件组件:
- Kubernetes集群:3 Master + 5 Worker
- 存储方案:Ceph RBD(副本数=3)
- 备份策略:每日快照 + 异地磁带库
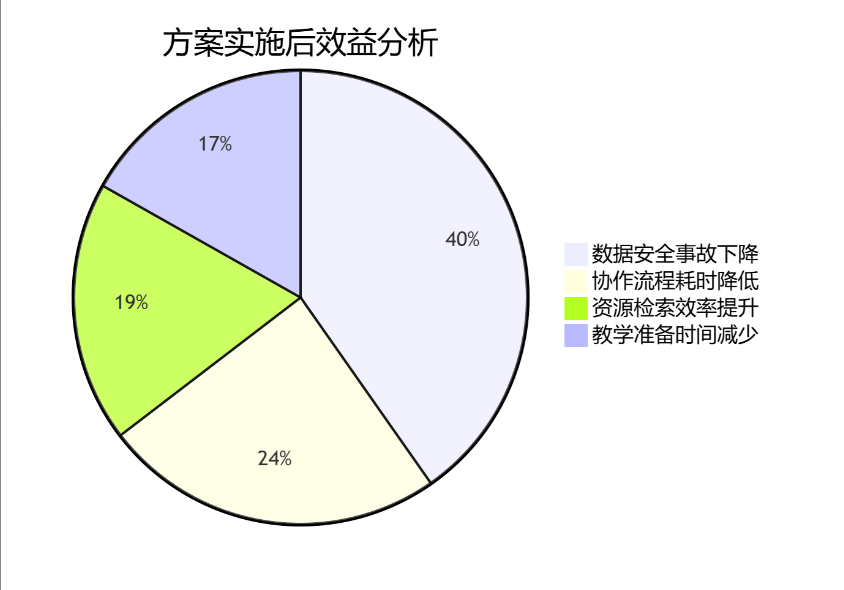
十二、客户效益分析
• 文档检索耗时下降82%(从平均5.2分钟→56秒)
• 跨部门协作流程缩短70%(如教案审批从3天→2小时)
6.2 风险规避
• 业务连续性:支持同城双活(RTO<15分钟,RPO<5分钟)
十三、建议实施步骤
现状诊断(1周):
最小化验证(2周):
分步迁移(推荐路径): bash复制# 使用数据迁移工具 ./kbox_migrate --source-type=FTP \ --source-addr=ftp://10.0.1.100 \ --target-bucket=edu-resources \ --transform-policy=preserve_metadata
持续优化:
一粒云智慧教育门户与教育文档方案已在深圳中学光明科学城学校等20+教育机构落地,实现教学资源利用率提升300%,数据管理成本下降45%。建议优先从「教师个人云盘+移动端协作」切入,6-8周即可完成首阶段价值验证。