概述
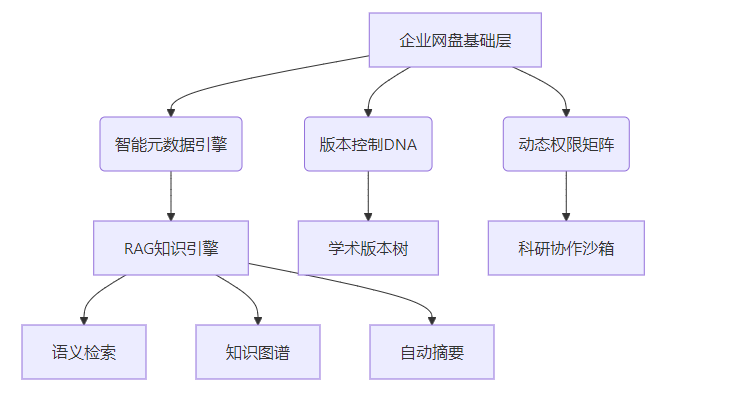
一粒云深度搜索产品基于NAS的独立搜索解决方案,旨在帮助集成商与最终客户通过简单易用的方式实现对存储在网络附加存储设备(NAS)中的文件进行高效、智能的搜索管理。通过将传统的文件管理与先进的AI搜索技术相结合,我们不仅提升了用户在文本和多模态数据搜索方面的效率,还能提供强大的权限管理和数据保护功能。
该解决方案不仅支持云盘与NAS文件之间的无缝集成,还能对不同类型的文件提供定制化的搜索体验,从文本文件到图像、视频、音频等多模态数据都能一站式处理,确保集成商和最终客户能够在多个应用场景下便捷地完成数据管理和搜索任务。
主要功能
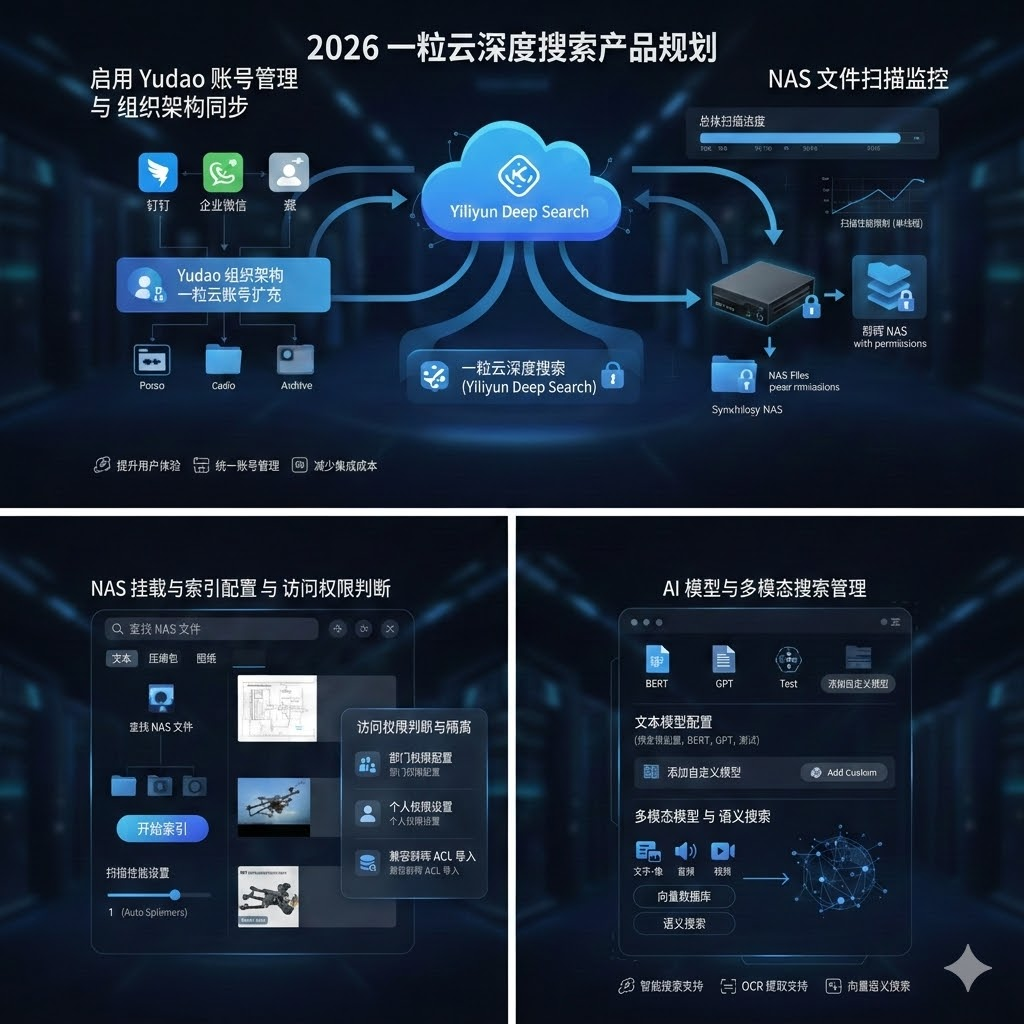
1. 启用Yudao的组织架构与账号同步
- 功能描述:
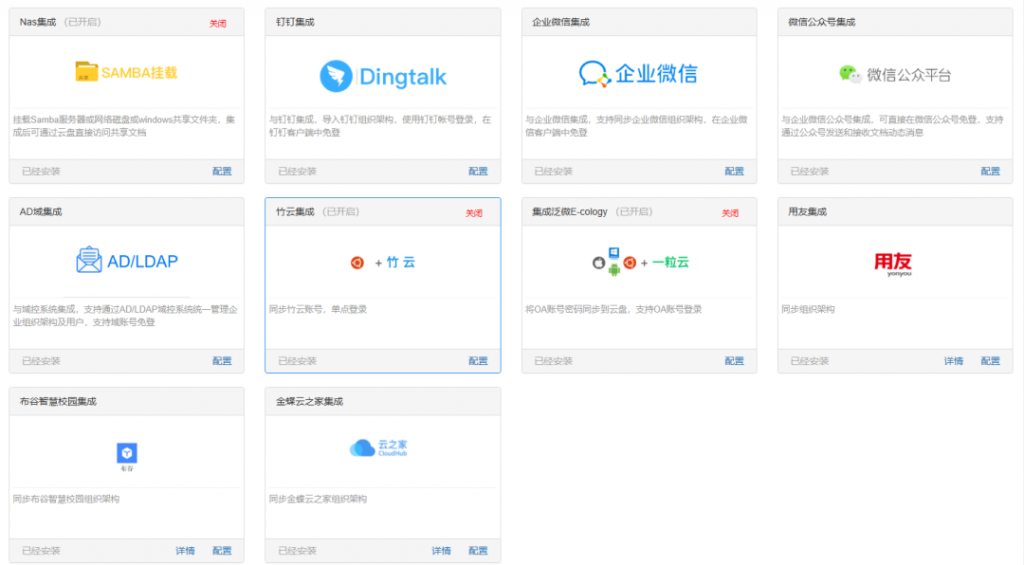
我们的解决方案基于一粒云的账户扩展,实现与Yudao的组织架构与账号同步。通过这一功能,集成商和客户可以轻松将一粒云的账户信息同步到Yudao组织架构中,确保用户账号的一致性和统一管理,简化身份验证与授权管理。 - 与钉钉、企业微信同步:
开发了钉钉和企业微信与Yudao组织架构同步的组件,方便用户在多个平台间共享账户信息,减少重复操作和管理负担。无论是团队成员的管理还是权限设置,都能够在统一的框架下实现,极大提高了操作的便捷性。 - 价值与优势:
- 提升用户体验:确保跨平台、跨工具的无缝衔接。
- 统一账号管理:管理员可以方便地进行账号审核、权限管理等操作。
- 减少集成成本:无需额外为每个平台单独配置账户,简化了部署和维护过程。
2. 添加访问权限判断与文件隔离
- 功能描述:
该功能支持对NAS文件进行访问权限配置与隔离,用户可以为不同的部门或个人配置与云盘一致的访问权限,确保数据的安全性与合规性。 - 与云盘一致的访问权限管理:
用户可以为挂载到NAS的文件设置部门或个人访问权限,确保访问控制灵活且高效。通过导入和导出操作权限,管理员能够快速复制、迁移或备份权限设置,简化权限管理流程。 - 兼容群晖访问清单导入:
提供群晖NAS的访问清单导入功能,帮助用户更便捷地将现有的权限管理迁移到我们的深度搜索解决方案中,避免重复配置。 - 价值与优势:
- 灵活的权限控制:支持部门和个人级别的权限配置,确保文件访问的安全与合规。
- 高效的迁移支持:通过导入群晖权限清单,减少了系统部署和权限管理的工作量。
- 数据隔离:通过权限判断与文件隔离,避免了不同用户间的数据泄露或误操作。
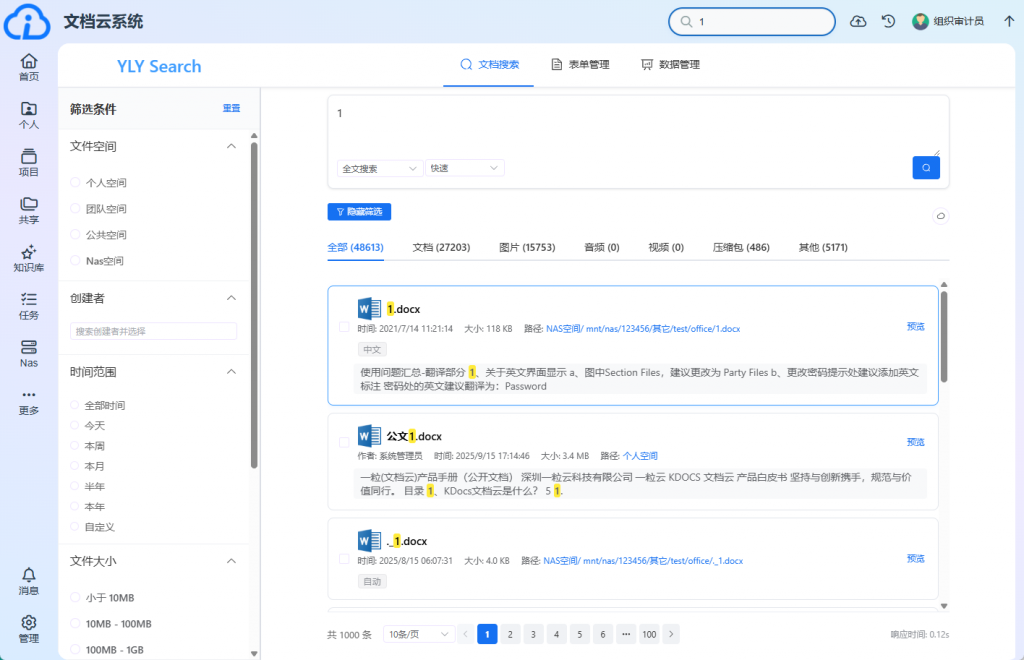
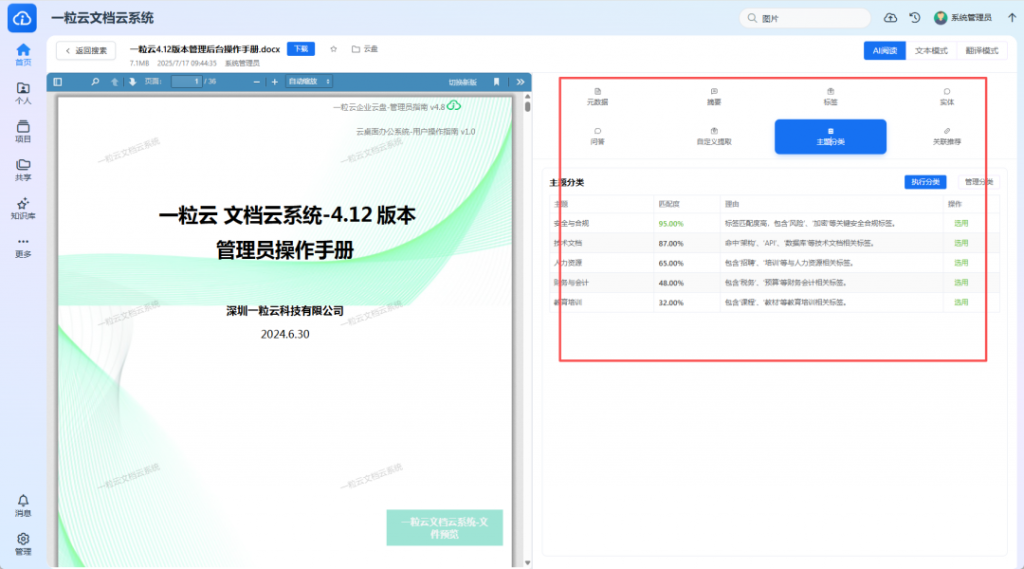
3. NAS文件扫描过程的可视化优化
- 功能描述:
我们对NAS文件的扫描过程进行了可视化优化,使得扫描任务的管理更加简便透明。 - 扫描任务可视化:
用户可以通过界面清晰地查看当前扫描任务的状态、进度及处理情况,实时掌握任务进展。 - 简化NAS挂载与索引:
我们大大简化了NAS挂载与索引的流程,用户无需复杂的配置,便可完成文件的挂载和索引任务。 - 性能限制支持:
解决了群晖低端产品的扫描性能瓶颈,默认仅开启一个线程,保证低性能设备的稳定运行,避免系统过载。 - 价值与优势:
- 提升用户操作体验:通过任务可视化,用户可以随时监控扫描进度,确保无遗漏。
- 简化配置:优化的挂载和索引流程,使得即使是技术人员较少的团队也能轻松配置和使用。
- 性能优化:为低端设备提供优化支持,避免因硬件限制造成的性能瓶颈。
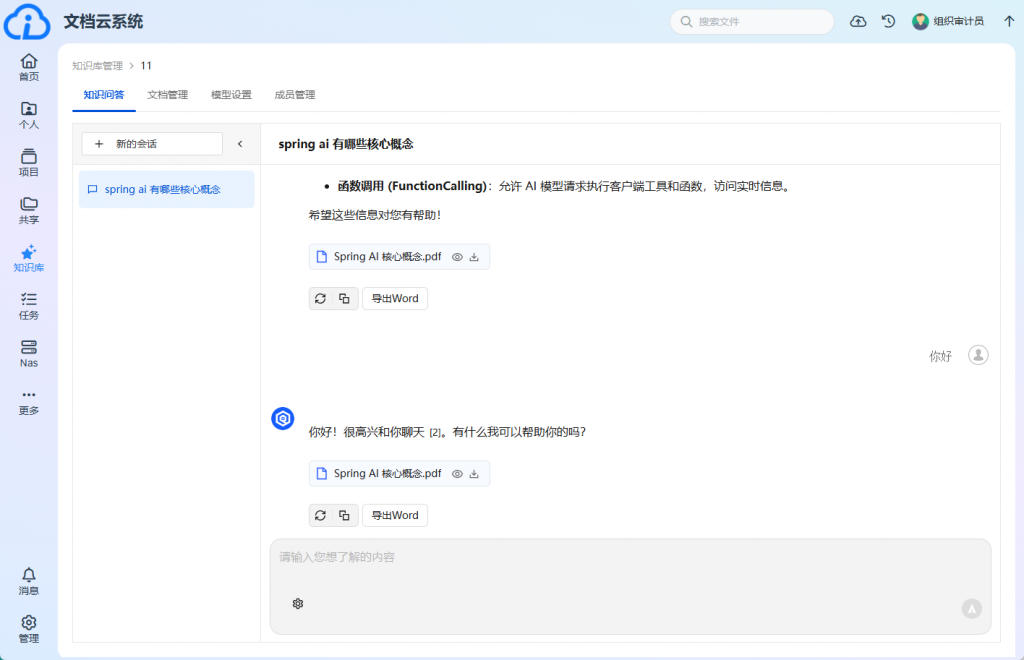
4. AI搜索支持(多模态支持)
- 功能描述:
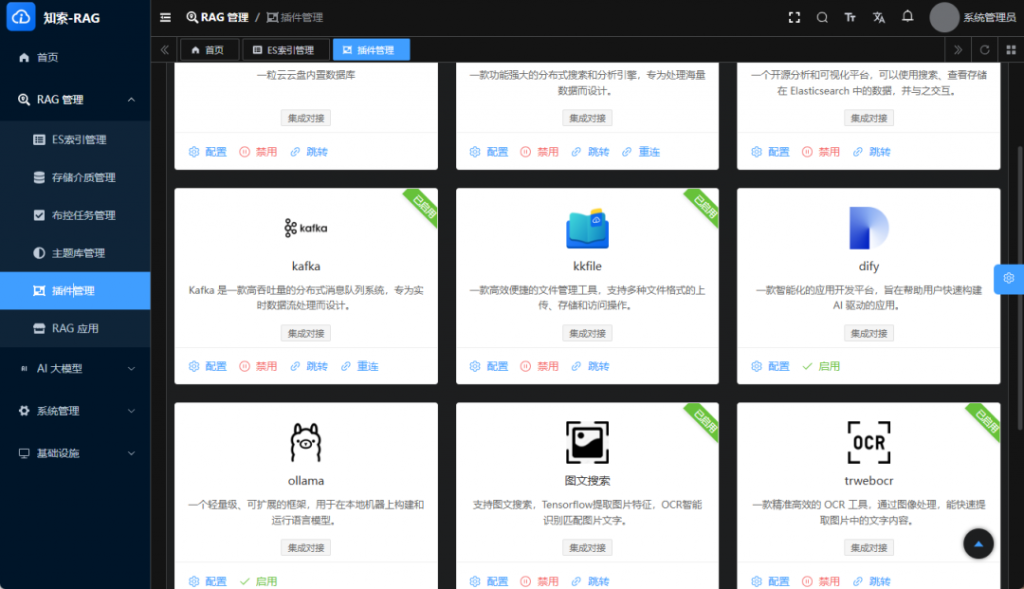
我们的AI搜索模块支持多模态数据的处理,包括文本、图片、音频、视频、办公文档、图纸、压缩包等,带来了全面的文件搜索体验。 - 文本模型与多模态模型接入与管理:
用户可以配置不同的文本模型以及图文、语音、视频等多模态模型,并进行集中管理。这使得用户可以针对不同类型的文件设置专门的处理方式,以更高效地进行搜索。 - OCR与图文搜索支持:
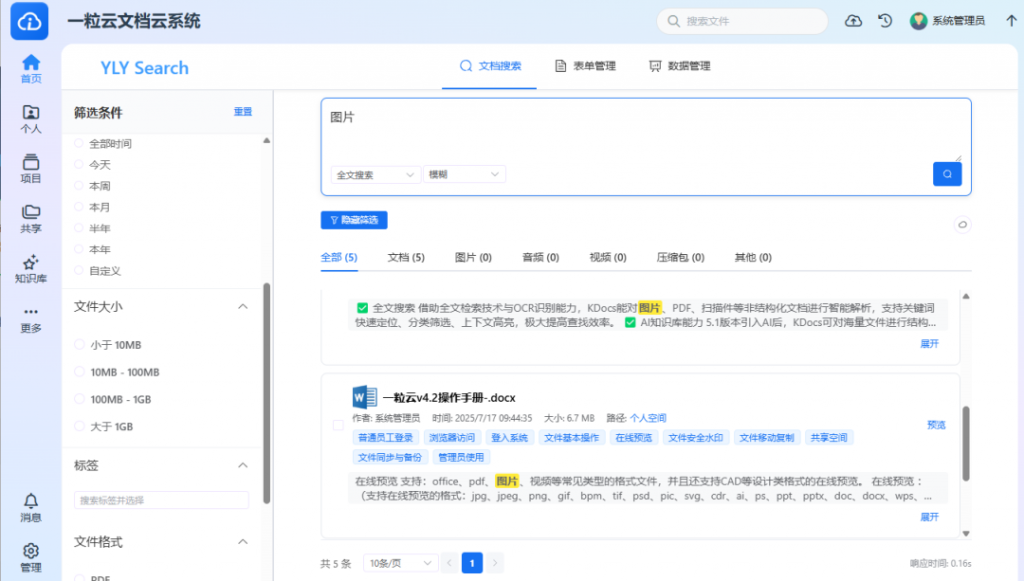
我们为图片和扫描文档提供OCR(光学字符识别)支持,实现对图片中的文字进行索引和搜索。图文搜索功能使得用户可以在图像和文本之间进行更加智能的搜索。 - 向量搜索支持:
提供对向量搜索的支持,尤其适用于图像和文档的语义搜索,让用户能够跨越关键词的限制,基于语义进行精准的搜索。 - 价值与优势:
- 支持多种文件类型:不仅限于文本文件,还支持图片、视频、音频等多种数据格式,极大提升了数据的搜索范围。
- 智能搜索:通过AI算法和多模态技术,用户可以根据语义进行文件搜索,提升查找效率。
- 灵活配置:用户可以根据业务需求,灵活配置不同的模型和搜索方式,满足各类场景的需求。
方案架构与配置便捷性
本解决方案设计考虑到了便捷性与可配置性。用户只需通过简单的步骤便可完成系统的配置与部署,整个过程无需深入的技术知识。解决方案的主要优势包括:
- 统一管理与配置:通过统一的控制台,用户可以轻松管理账户、权限、搜索任务和AI模型。无论是文件的挂载、索引,还是权限的设置和优化,都能通过图形化界面完成。
- 自动化配置与优化:系统自动进行优化配置,包括性能调节、线程管理等,用户无需手动干预即可确保最佳性能。
- 支持跨平台部署:我们的方案支持在多种平台上进行部署,包括Windows、Linux、群晖等,用户可根据自身需求自由选择。
- 灵活的模型与任务管理:用户可以轻松切换或调整文本与多模态模型的配置,并对扫描任务进行详细管理,确保满足不同的数据处理需求。
总结
一粒云的深度搜索解决方案为集成商和最终客户提供了一个集高效、安全、智能为一体的文件管理平台。通过AI技术与高效的权限管理,用户可以轻松管理和搜索NAS设备中的文件,不仅提升了数据安全性,还大幅度优化了搜索效率。我们致力于通过简单的配置与灵活的功能,帮助客户解决复杂的文件管理问题,实现数字化转型的目标。
这一解决方案不仅适用于中小型企业,也非常适合大型企业在信息化建设中的应用,是实现企业数据管理智能化、精细化的理想工具。