联动品牌:WPS
主推方案:一粒云 智能文档云 + ISO文控
延展产品:企业网盘、智能文件汇聚平台、AI知识库、隔离网文件安全交换
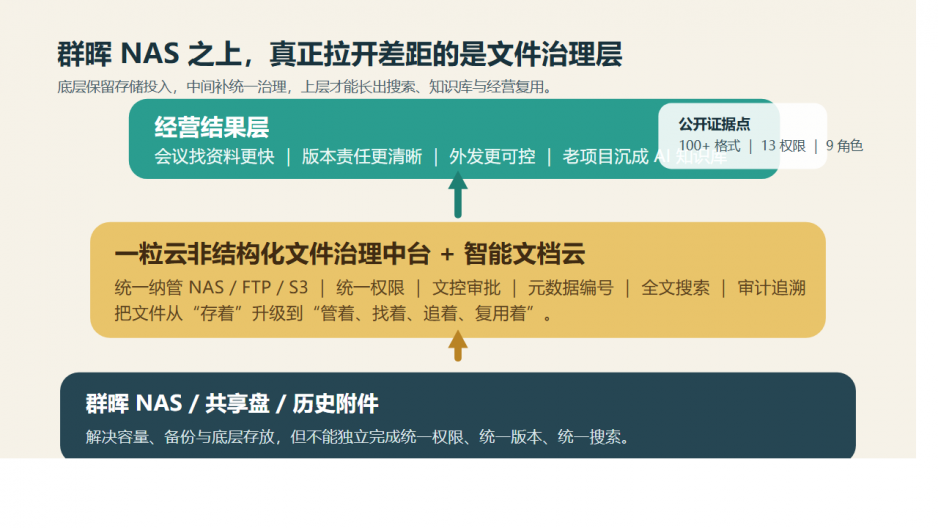
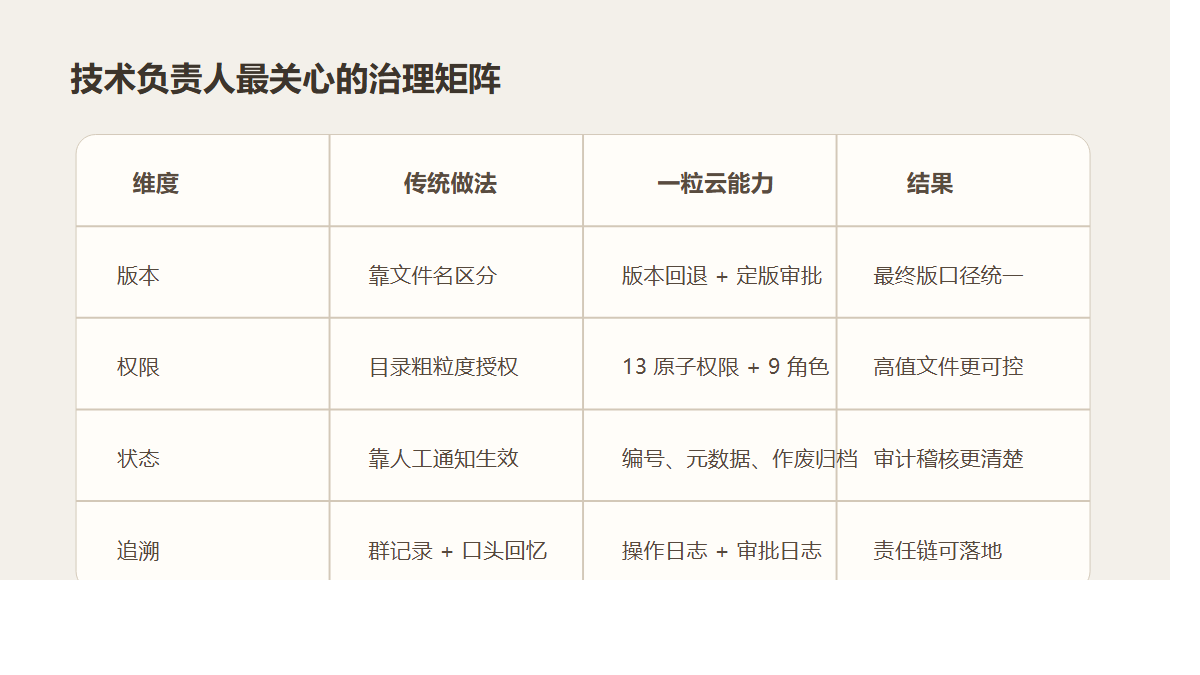
一粒云成立于 2015 年,70%+ 为研发人员,服务 2000+ 中大型企业客户,覆盖 20+ 区域渠道;平台支持 100+ 文件格式在线预览、13 种原子权限、9 个默认角色,并支持 WPS / OA / ERP / AD / 企业微信 / 钉钉 / NAS / FTP / S3 等集成能力。
很多技术负责人都有疲惫感。
制度在写,方案在改,表格在传,汇报在做。
可一到追责、审计、定版的时候,问题又回到老路上。
哪一份才是最终版?
谁替换过文件?
谁把旧版又发了出去?
哪一个目录是受控目录,哪一个只是临时协作目录?
WPS 很适合承担内容生产和协同。
但技术负责人真正要扛的,不只是“能不能写出来”,而是文件写完之后,能不能进入统一规则、统一编号、统一审计的体系。
很多单位卡住的,不是流程不够多,而是附件链没有底座,版本链没有规则。
所以这篇文章只讲一个结论:
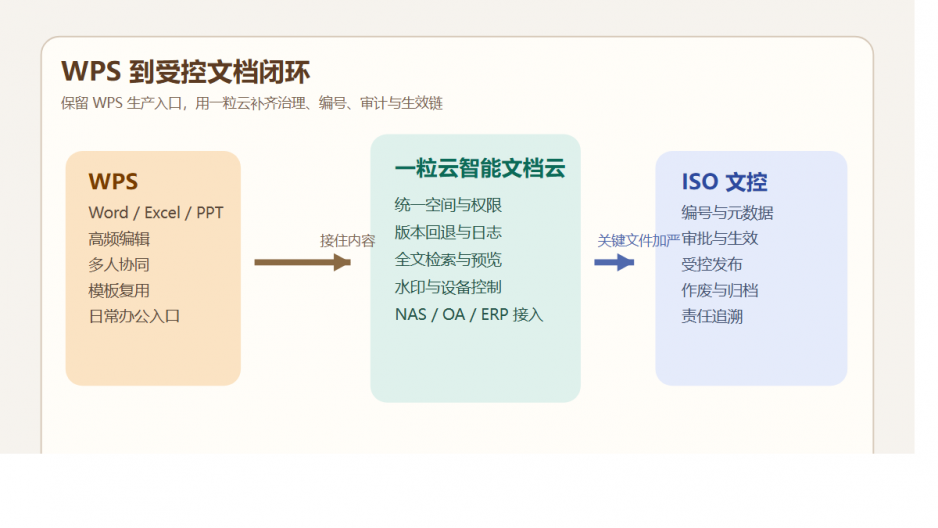
继续保留 WPS 作为生产入口,同时用 智能文档云 + ISO文控 把制度、图纸、合同、项目文档、质量文件管起来。
先问一个最扎心的问题:为什么 WPS 用得越顺,文件失控反而越容易暴露?
因为生产效率上来之后,文件量、流转量、版本数会一起上来。
以前文档少,靠人记忆还能勉强兜住。
现在大家都在 WPS 里高频产出,问题就会从“不会做文档”变成“文档做完以后怎么管”。
技术负责人最常遇到的 4 个断点,几乎每个单位都有。
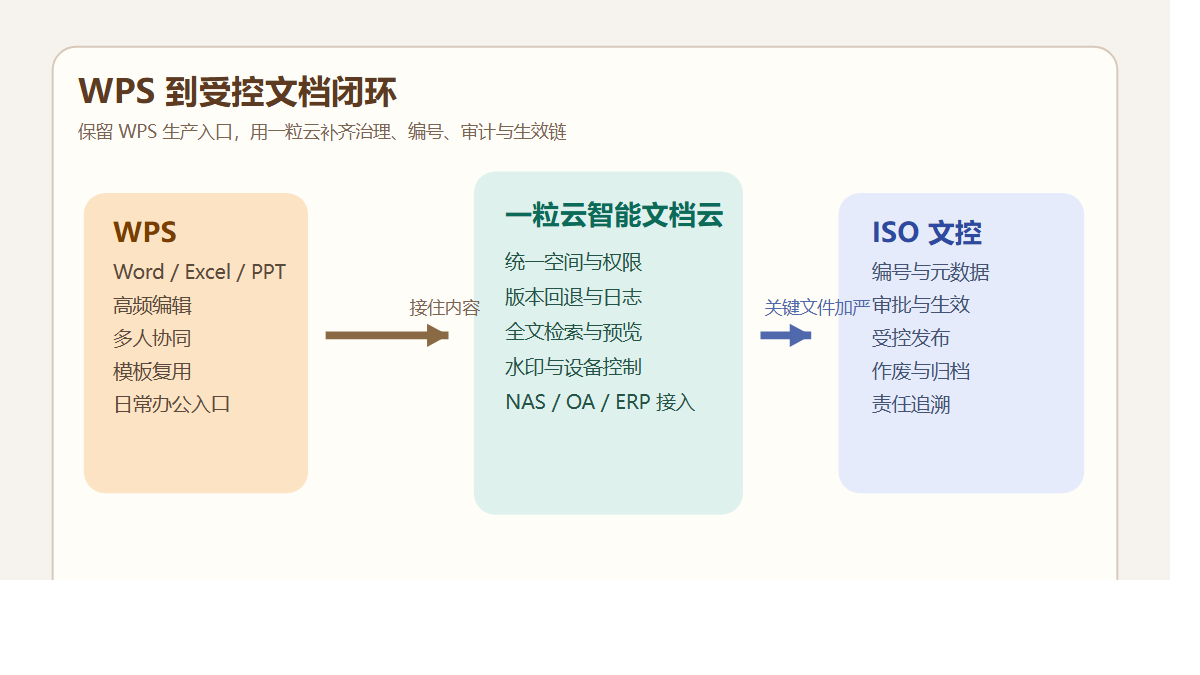
第一,编辑是在线的,定版不是在线的。
一份制度在 WPS 里可以多人改得很快,但最终谁来确认生效版、哪个版本可下载,如果没有文控规则,在线编辑越方便,最终版越容易混。
第二,入口是统一的,归口不是统一的。
有人存部门盘,有人存共享目录,有人发群文件,有人留本地桌面。技术负责人看到的不是内容生产效率,而是目录口径越来越散。
第三,文件在协同,责任不在协同。
谁上传、谁预览、谁下载、谁分享、谁替换版本,如果只能靠口头回忆或群记录补证据,IT 往往要临时救火。
第四,WPS 能解决写作问题,但解决不了高密级文件治理。
研发资料、标准文件、质量文件、定稿图纸,不该只停留在“可编辑”,更要进入“可审批、可编号、可追溯”的链条。
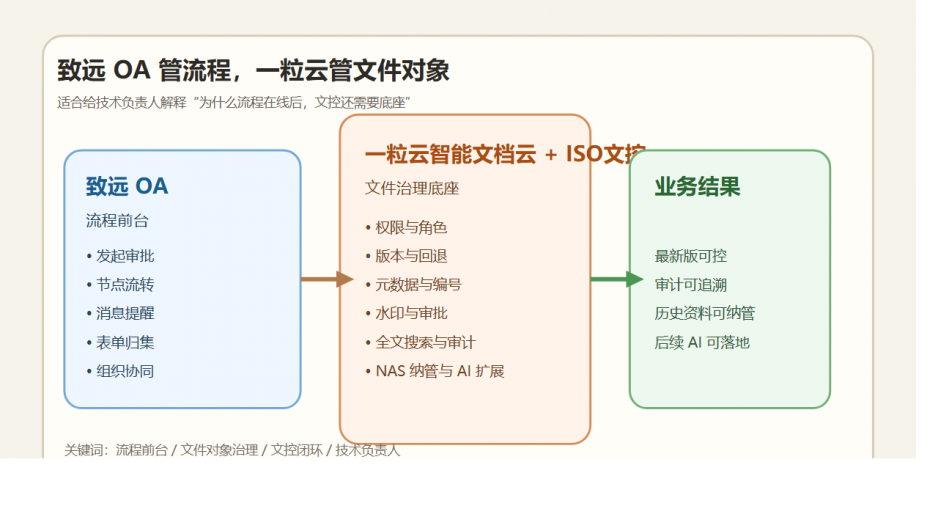
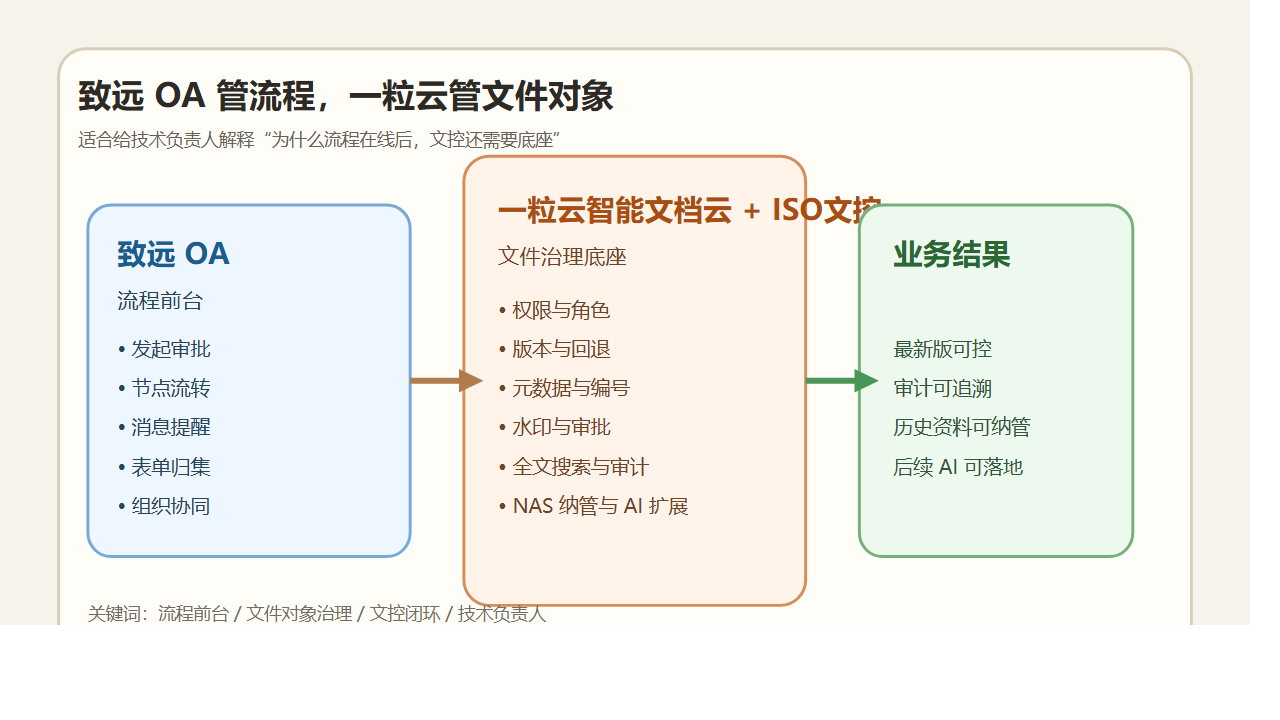
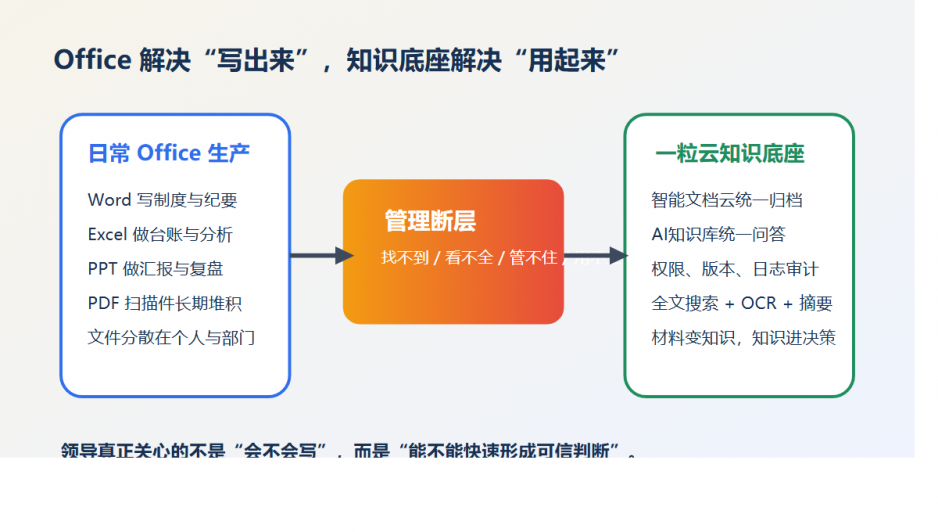
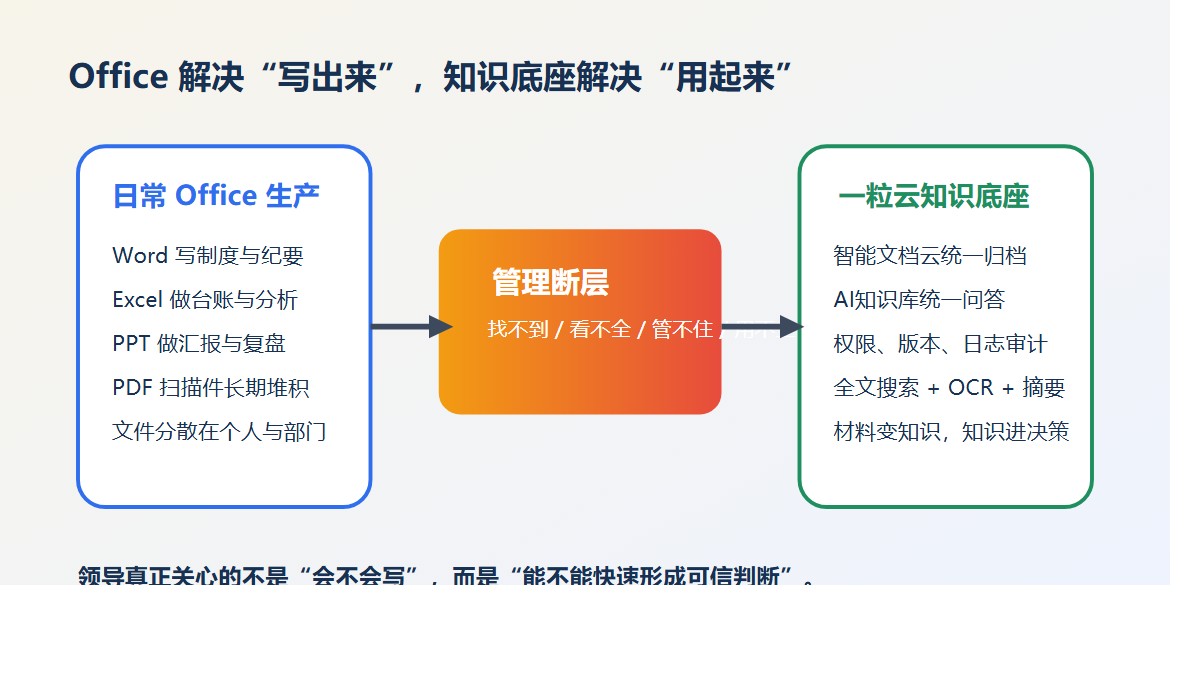
技术负责人真正该补哪一层?不是替代 WPS,而是把 WPS 后面的生命周期补齐
WPS 继续做员工最熟悉的内容生产入口。
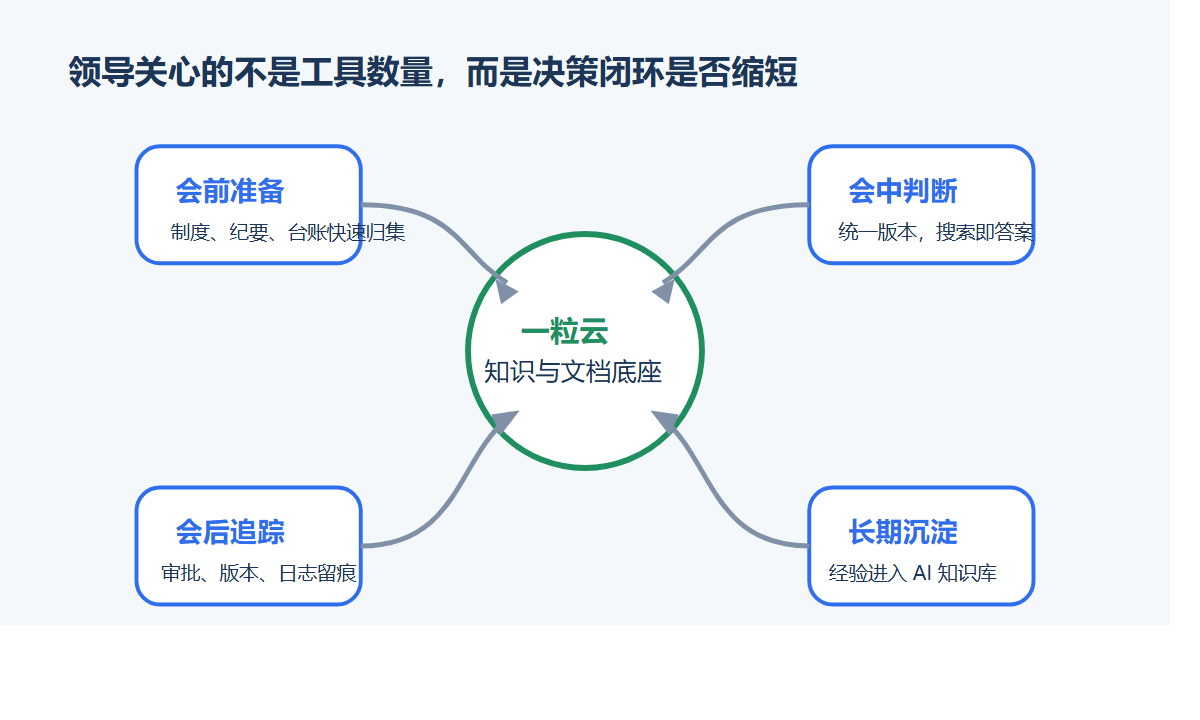
一粒云 智能文档云 负责把这些内容接入统一的文件空间、权限体系、版本体系、预览体系和检索体系。
ISO文控 再把关键文档加上一层更严格的审批、生效、编号、作废、元数据和审计规则。
这样做的好处,不是让员工多学一个系统,而是把“文档全生命周期”真正抓住。
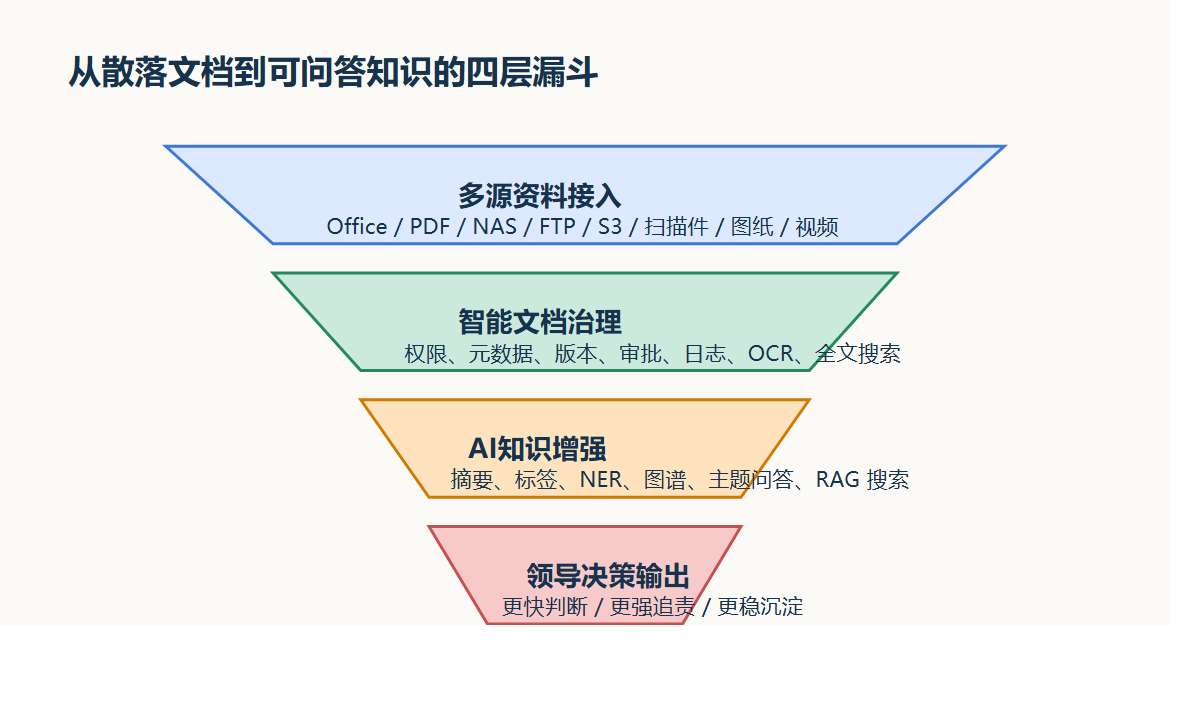
从现有资料看,一粒云已经明确支持 word、excel、ppt、wps 的在线编辑与导出,同时具备:
- 个人、部门、共享、项目群空间的统一规则
13种原子权限与9个默认角色- 版本管理、历史回退、回收站、多级权限
- 全文检索、标签检索、元数据检索、归类检索
- 100+ 文件格式在线预览
- 预览水印、下载水印、防复制、防打印、设备控制
- 按上传、下载、更新、分享、删除、预览等动作配置审批
- 文档编号、表单元数据、业务字段关联和日志追溯
一句话说清楚:WPS 负责“写”,一粒云负责“管”,ISO文控负责“控生效”。
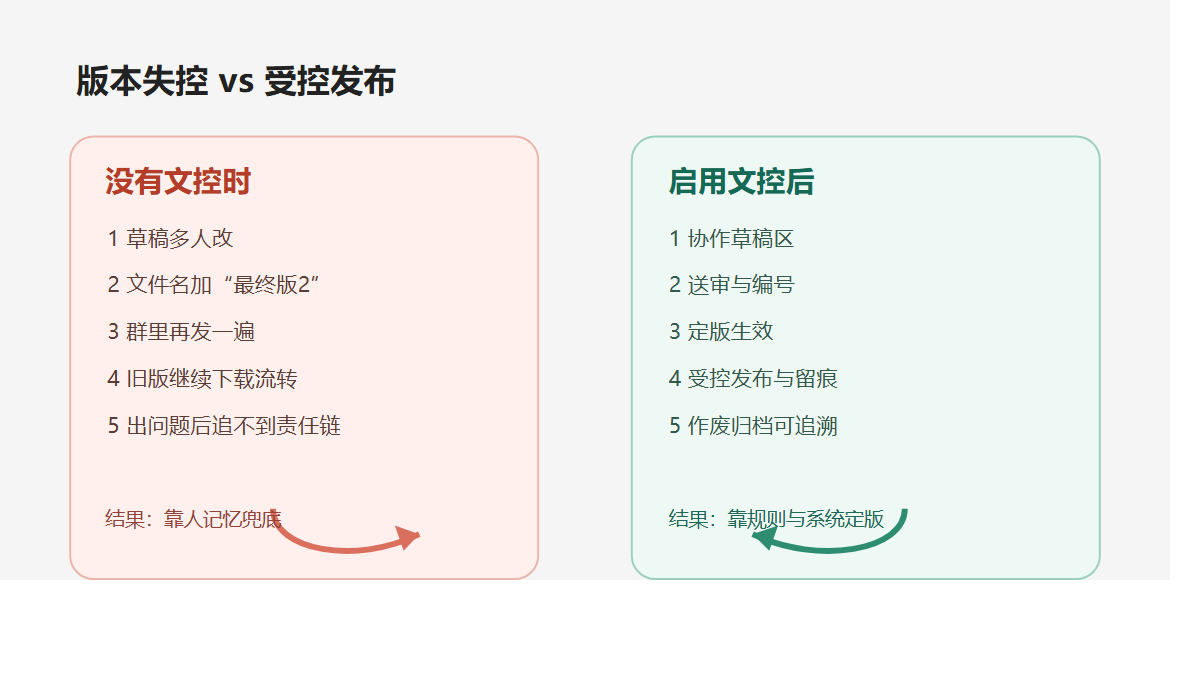
为什么很多单位流程很多,文件治理还是做不实?
因为流程系统解决的是“谁审批”,文档治理解决的是“审批之后这份文件到底处于什么状态”。
技术负责人往往最怕下面几件事:制度审批过了,但员工还在看旧版;图纸已经替换了,但生产线拿的还是历史版本;项目交付件发出去了,却没有统一台账;审计来了,能查到流程单,查不到完整附件链。
这就是很多单位最隐蔽的损耗。
表面上系统已经不少。
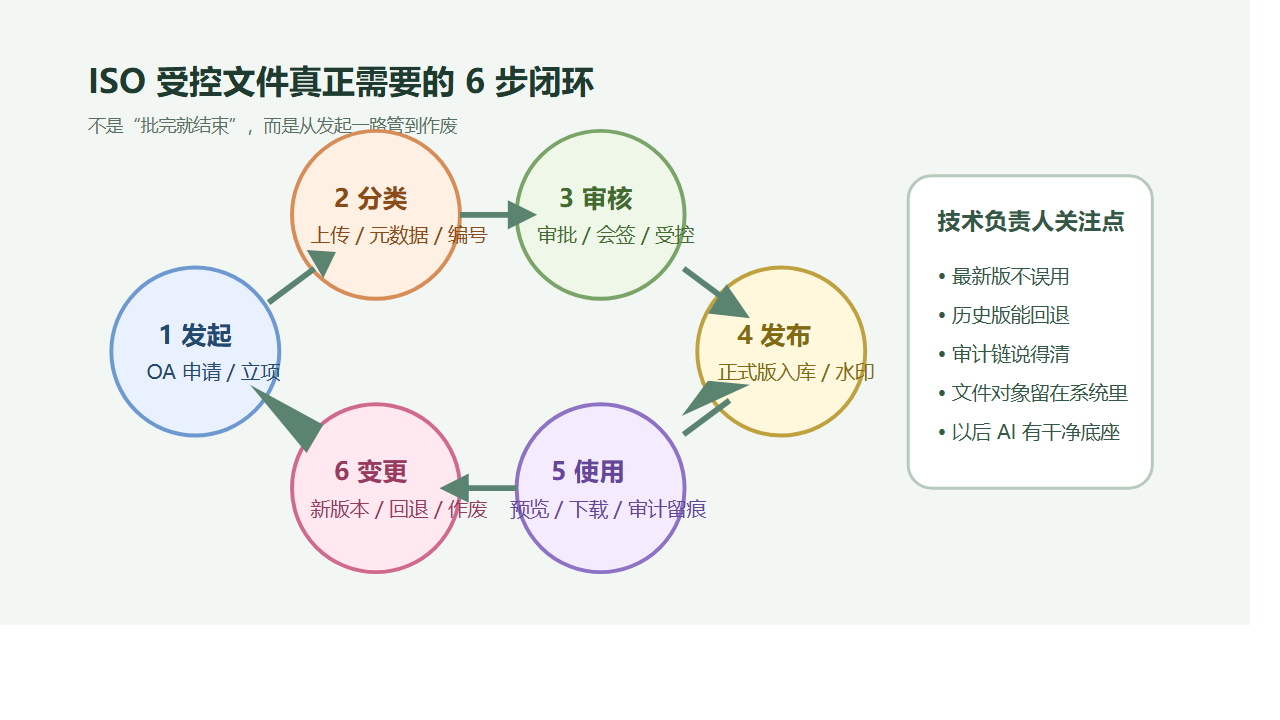
实际上真正缺的是一个文档状态机。
文档不是“存进去”就结束了。
它至少会经历:草稿、协作、送审、定版、生效、分发、作废、归档。
如果这条链没有被系统化,技术负责人就只能用目录命名、人工通知和经验默契去兜底。
这种方式在文件少的时候还能勉强运行,一旦部门多、人员多、项目多,就会迅速失控。
把场景讲透:哪些文件最适合先接入 智能文档云 + ISO文控?
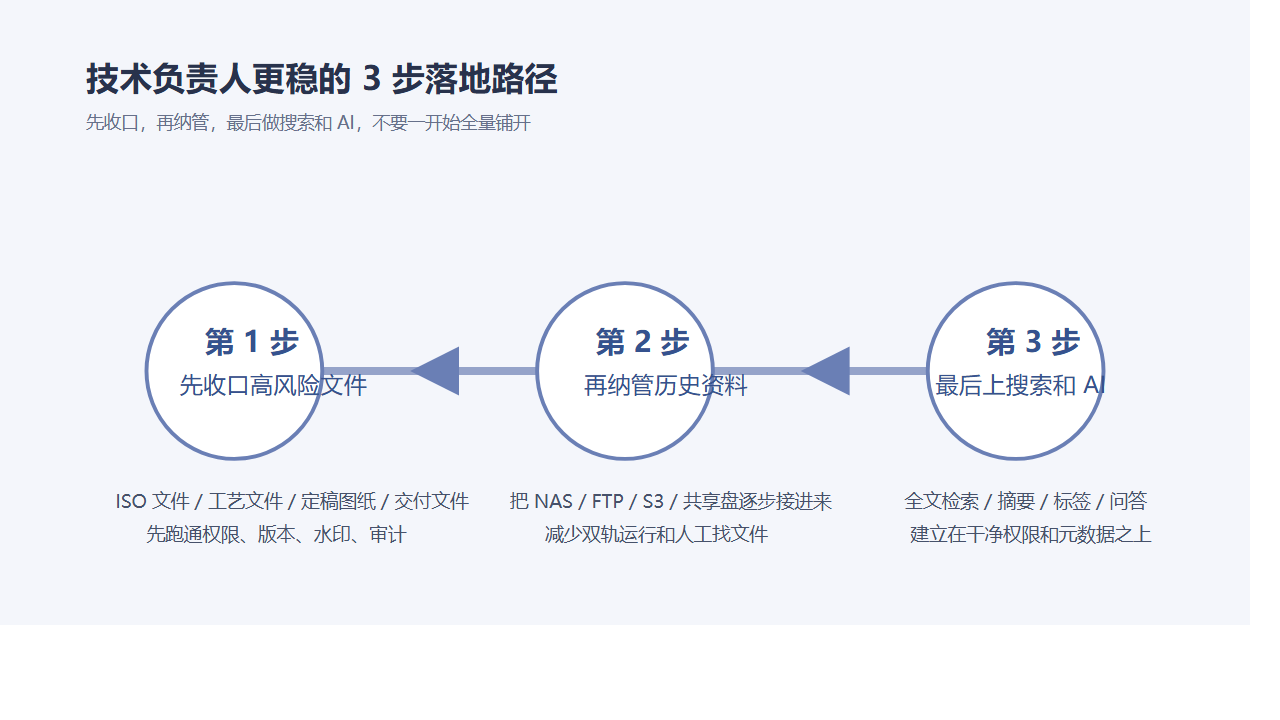
如果你是技术负责人,不需要一上来就全单位大迁移。
最容易出效果的,是 4 类高价值文件。
1. 制度文件和受控模板。
最怕旧版继续流通。上了文控后,可以给文件加编号、审批、生效口径和版本留痕。
2. 研发图纸和项目交付件。
最怕多人协作后版本混乱。文档云保留协作便利,文控把关键节点锁到受控流程里。
3. 质量体系文件和 SOP。
最怕“谁都能看,谁都能传,但没人知道哪版在执行”。元数据、编号和归类检索一旦建立,稽核效率会明显提升。
4. 合同、方案、外发材料。
这类文件最怕外发无痕和历史追责困难。预览水印、下载水印、访问记录、审批日志会比单纯群发附件稳得多。
如果单位里还存在多网环境,后续还可以把 隔离网文件安全交换 接进来,让高密级文件在跨网流转时继续保留审批、杀毒、敏感字检查和日志审计。
为什么这个组合对技术负责人更友好?因为它不是推翻习惯,而是分层建设
很多治理项目推不动,不是价值不够,而是改动太猛。
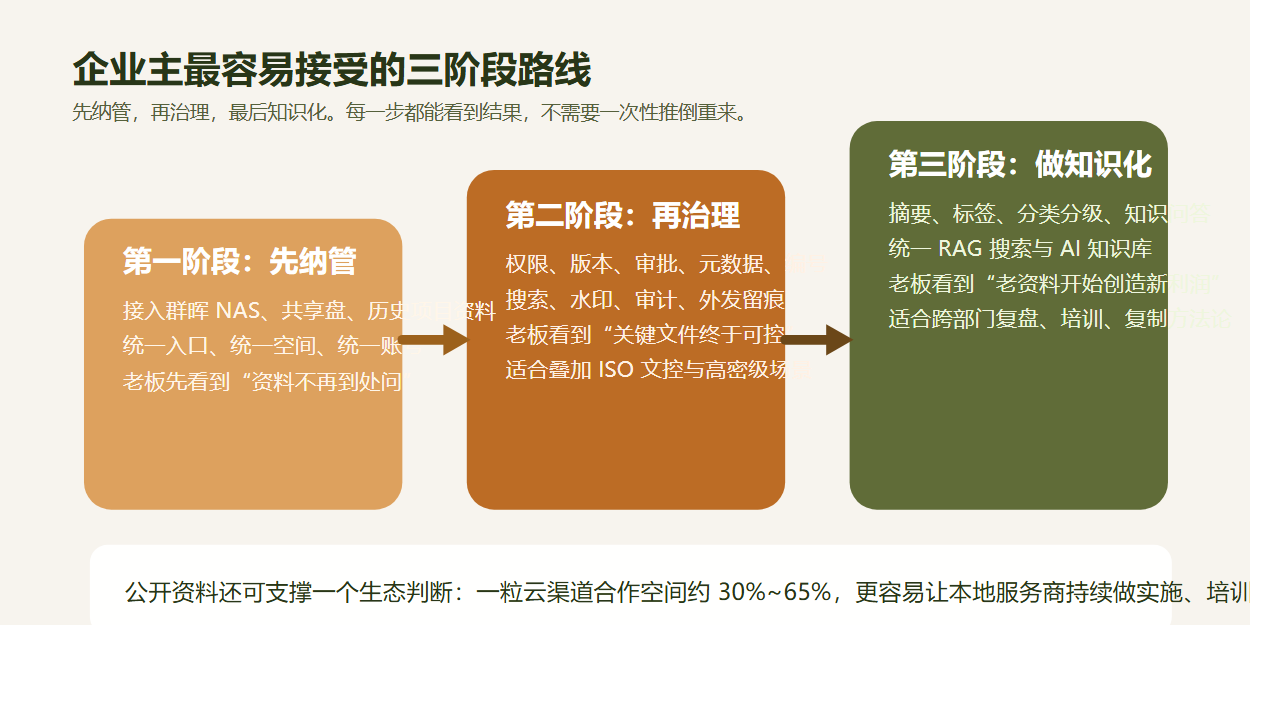
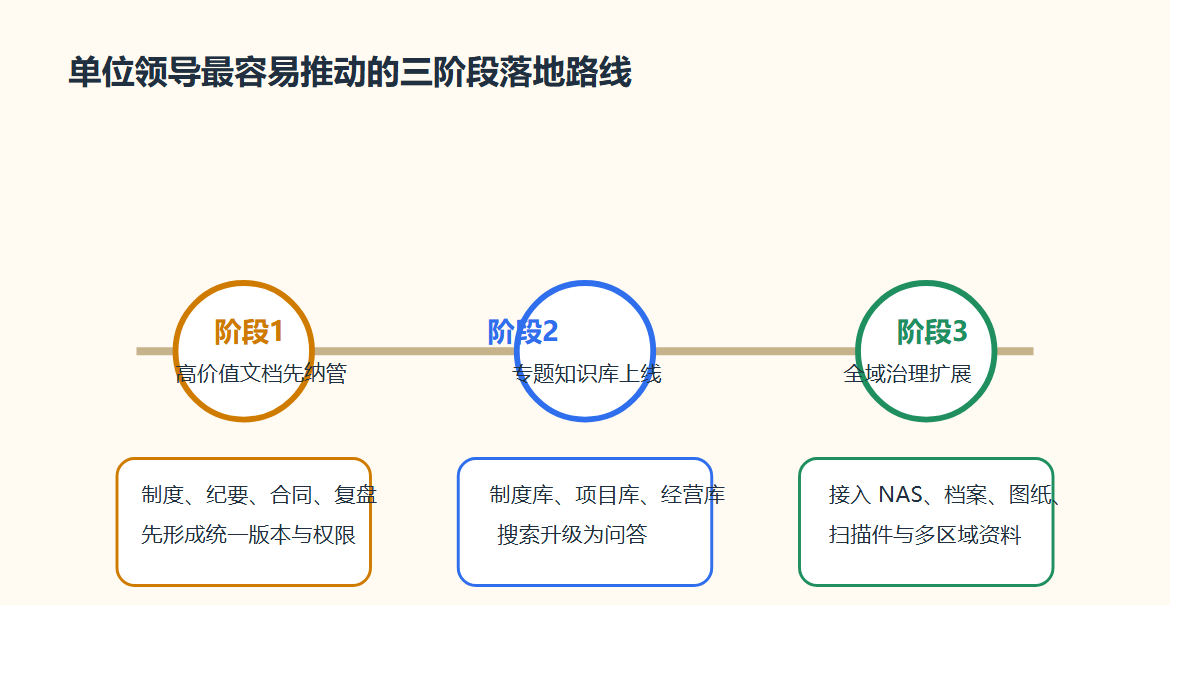
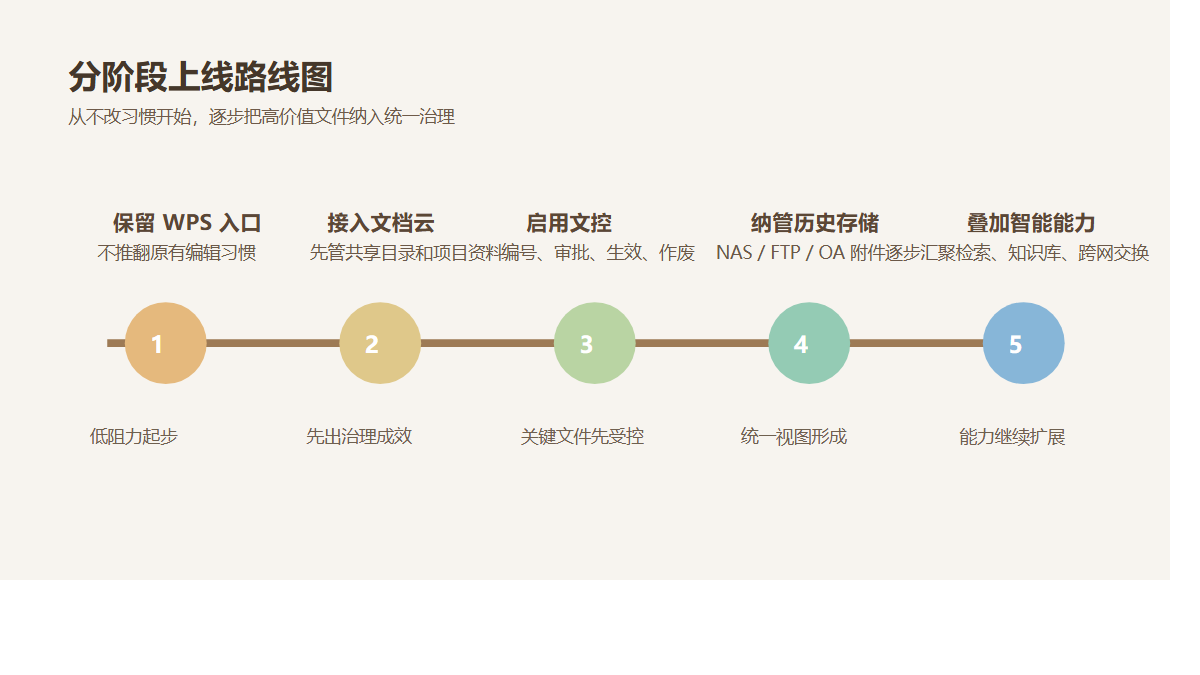
技术负责人真正需要的,是一条能低风险上线的路线:
第一阶段,保留 WPS 作为主要编辑入口。
第二阶段,把共享目录、项目文档、受控文件放进智能文档云。
第三阶段,对关键目录启用 ISO 文控,建立编号、元数据、审批和生效规则。
第四阶段,再把历史 NAS、FTP、业务系统附件逐步纳管。
第五阶段,等底座稳定后,再把检索、知识库问答、跨网交换等能力叠加上去。
这条路径的好处很直接:用户习惯不必整体推翻,技术架构能渐进改造,治理收益能按目录和场景逐步释放。
写给技术负责人的一个现实判断:别再把“能编辑”当成“能治理”
现在很多单位的问题,不是办公工具太弱,而是把办公效率误当成治理能力。
会编辑,不等于会定版。
会协同,不等于可追责。
有流程,不等于文件状态清晰。
有网盘,不等于文档资产可经营。
对技术负责人来说,真正重要的是把“高频生产”和“高价值治理”拆开来看。
生产层,继续让 WPS 发挥效率;治理层,用一粒云把权限、版本、编号、审批、日志和审计补齐。
渠道为什么愿意推这类方案?
因为它不是一次性卖盒子,而是能做成平台型项目。资料显示,不同模块通常给渠道预留了约 30% 到 65% 的利润操作空间,核心平台型产品常见普通渠道约 50% 供货、金牌约 45%、钻石约 35%。
结尾只留一个问题给你
如果你们单位今天继续用 WPS 高效产出内容,明天这些内容准备怎么被定版、受控、编号、追踪和复用?
如果这个问题现在还主要靠人记忆、群通知和文件名后缀来解决,那你要补的就不是更多流程,而是一层真正的文档底座。
关注一粒云,下一篇继续拆:
为什么很多单位“系统很多、文件更多”,但真正能进 AI 知识库的资料却没有几份?
如果你也在负责文档治理、质量体系或项目资料管理,欢迎在评论区留言:
你们现在最难控的是“版本”,还是“外发”,还是“审计追溯”?