一、总体结论(先给结果再展开)
针对广东xxx局约 3000 用户、内外网隔离环境下的“安全交换网盘”需求,结合一粒云 KWS(隔离网文件安全交换系统)+ 共享网盘文档云,建议方案要点如下:
- 部署模式:
- 在内外网之间部署 KWS 安全交换区,承担跨网摆渡、审批、审计、病毒/敏感词检查等;
- 在内网部署 共享网盘文档云(KDOC/KBOX 企业版),作为 3000 用户的统一文件共享与协同平台;
- 通过 KWS 的三区交换模型,实现“内外网逻辑隔离 + 安全可控的文件交换”。
- 用户规模与并发估算:
- 一粒云官方建议:并发数 ≈ 用户数的 1/10,即 3000 用户按 300 并发 设计。
- 报价单中“50 并发授权”为最小计费单位,实际可按 300 并发 × 2(冗余与扩展)≈ 600 并发 购买授权,支撑 3000 用户长期使用。
- 服务器数量规划(推荐配置):
- KWS 安全交换摆渡区:
- 摆渡模块服务器:2 台(高可用,每台约 200 并发处理能力);
- 可选:1 台 AI 审计服务器(如果本地大模型审核对性能要求高,可单独部署)。
- 共享网盘文档云:
- 文档云应用服务器:2 台(前端应用 + 负载均衡,形成高可用);
- 存储服务器/存储节点:根据容量规划,建议 至少 1 台专用存储服务器或分布式存储节点(起步 50–100TB,后续扩容)。
- 整体服务器数量:
- 最小化高可用部署:5 台服务器(2 台 KWS + 2 台文档云应用 + 1 台存储);
- 如预算允许,建议 6–7 台(KWS 应用 2 台 + AI 审计 1 台 + 文档云应用 2 台 + 存储 1–2 台)。
下面按“架构 → 服务器规划 → 报价单调整 → 实施建议”展开。
二、整体架构设计(结合 KWS)
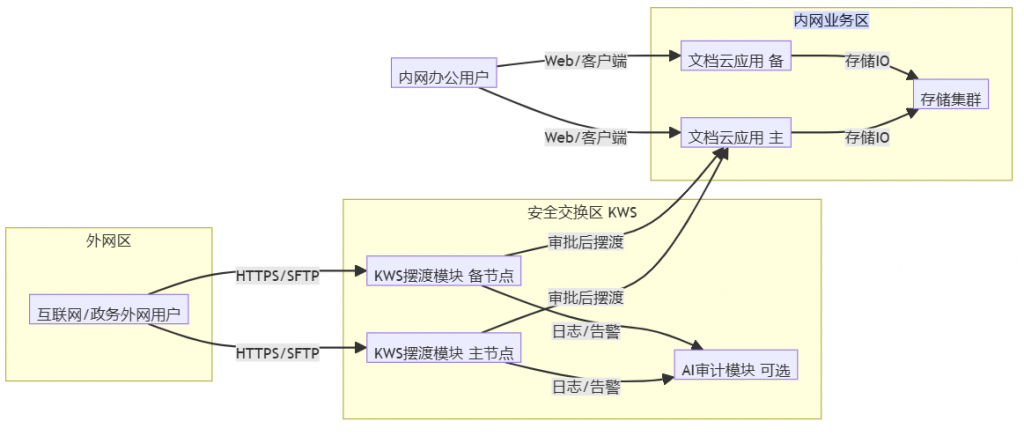
1. 网络分区与部署拓扑
结合一粒云官方介绍,KWS 支持三区交换模式、多网隔离、容器/虚拟化部署,适合作为内外网文件交换的安全边界。
推荐逻辑分区:
- 外网接入区:海事局互联网/政务外网接入,用于外网用户上传/下载待交换文件;
- 安全交换区(KWS):部署 KWS 摆渡模块、AI 审计(可选)、审批流引擎,承担:
- 跨网协议转换与数据摆渡;
- 文件出入网审批、审计;
- 病毒扫描(ClamAV)、敏感词/敏感内容检查;
- 对外提供 HTTPS/SFTP 等接口。
- 内网业务区:
- 部署 共享网盘文档云(KDOC/KBOX 企业版),为 3000 用户提供:
- 个人网盘、部门共享空间、项目文件夹;
- 在线预览、在线编辑、全文检索等;
- 内网用户通过浏览器/客户端访问文档云,所有跨网文件进出均经过 KWS 审批与审计。
典型拓扑示意:
2. 核心功能与合规要点
结合 KWS 官方能力:
- 跨网隔离与摆渡
- 支持多网隔离,通过三区交换模型(外网区、交换区、内网区)实现逻辑隔离,避免内外网直连;
- 可配合网闸/物理隔离环境,使用 KWS 一体机或软件模式接入不同网段。
- 审批与审计
- 出入网审批流程可自定义,支持按部门、安全级别配置审批规则;
- 全流程日志审计:谁、什么时间、在哪个网段、对什么文件做了什么操作。
- 内容安全检查
- 内置 ClamAV 病毒引擎,支持对跨网文件自动查杀;
- 敏感字库、敏感内容识别,支持自定义规则;
- 可选本地大模型 AI 审核,对文件、图片、压缩包进行语义识别,标注“脏话、机密、联系方式、病毒、敏感字库”等。
- 共享网盘能力
- 支持个人空间、部门共享空间、项目空间,细粒度权限控制(11 种原子权限组合);
- 在线预览常见文档、图片、视频等格式,支持在线编辑(集成 WPS/OnlyOffice 等);
- 支持全文检索、版本管理、外链分享、水印、访问统计等。
- 与现有系统集成
- 支持 AD 域、钉钉、企业微信、统一身份认证等集成;
– 提供 OpenAPI,可与海事局现有 OA、业务系统对接,实现单点登录、组织架构同步、文件归档等。
三、3000 用户规模下的并发与服务器规划
1. 用户数 → 并发数估算
一粒云官方建议:
“一般取账号数的十分之一作为参考。譬如 1000 人使用,我们就预计并发数为 100 人。”
因此:
- 总用户数:约 3000 人;
- 建议设计并发数:
- 按官方经验:300 并发;
- 考虑海事局业务集中(如集中收文、项目申报期),建议按 300–400 并发峰值 设计;
- 授权采购时,建议按 600 并发 购买,既满足当前峰值,又预留扩展空间。
2. KWS 安全交换区服务器规划
结合报价单中的硬件规格(双路至强金牌 6133、32G 内存、10G 网卡、8T×3 存储)以及网盘类应用的一般经验:
- 单台 KWS 摆渡服务器能力估算:
- CPU/内存配置较高,在网盘场景下,单机通常可支撑 200+ 并发 的文件上传/下载 + 审批 + 审计;
- 若开启 AI 审核(本地大模型),会额外消耗 CPU/内存/GPU 资源,建议 AI 模块单独部署。
- 推荐配置:
- 摆渡模块服务器:2 台,配置参考报价单中的 Synsea SE-4120:
- CPU:双路至强金牌 6133(40C/80T);
- 内存:建议提升到 64–128GB(报价单为 32G×2,可加到 64G×2);
- 存储:3×8T HDD 用于交换缓存与短期存储,如需保留更长时间摆渡日志/文件,可再增加硬盘;
- 网络:10G 光口/电口,连接内外网交换机,保证带宽。
- AI 审计服务器(可选):
- 若启用本地大模型 AI 审核,建议 1 台独立服务器,配置:
- CPU:双路至强 Gold 6133 或更高;
- 内存:128GB 以上;
- 存储:若干 SSD,用于模型和缓存;
- GPU:可选 1–2 块推理卡(根据模型规模与并发需求)。
通过 2 台 KWS 摆渡服务器 + 负载均衡,可实现:- 高可用:任一节点故障,业务不中断;
- 性能扩展:两台合计可支撑 400+ 并发交换操作,满足 3000 用户使用。
3. 共享网盘文档云服务器规划
参考一粒云对文档云 KDOC 的介绍:
- 应用层(文档云服务端)
- 推荐部署 2 台应用服务器,每台配置:
- CPU:双路至强 Gold/Platinum(可选 6133 同系列或稍低型号);
- 内存:64–128GB;
- 存储:系统盘 + 少量 SSD 作为缓存;
- 网络:10G 网卡连接存储与交换区。
- 通过前端负载均衡(Nginx/HAProxy)实现:
- 会话保持;
- 故障自动切换;
- 横向扩展:未来用户数/并发进一步增长,可增加应用节点。
- 存储层
- 按一粒云经验:
- 10TB 以下可用服务器本地盘或 NFS;
- 10–100TB 建议独立存储服务器;
- 100TB 以上建议分布式对象存储。
- 对海事局 3000 用户场景:
- 建议起步配置 50–100TB 存储空间,满足未来 3–5 年文档增长;
- 采用 分布式存储或 SAN/NAS,通过冗余架构保证可靠性;
- 可与 KWS 的交换存储分开,避免交换区与长期文档存储混用。
- 文档云并发能力
- 文档云主要处理文件访问、在线预览、搜索等,CPU/IO 密集但单请求开销较小;
– 2 台应用服务器 + 高性能存储,通常可轻松支撑 300–500 并发 文件访问与在线编辑。