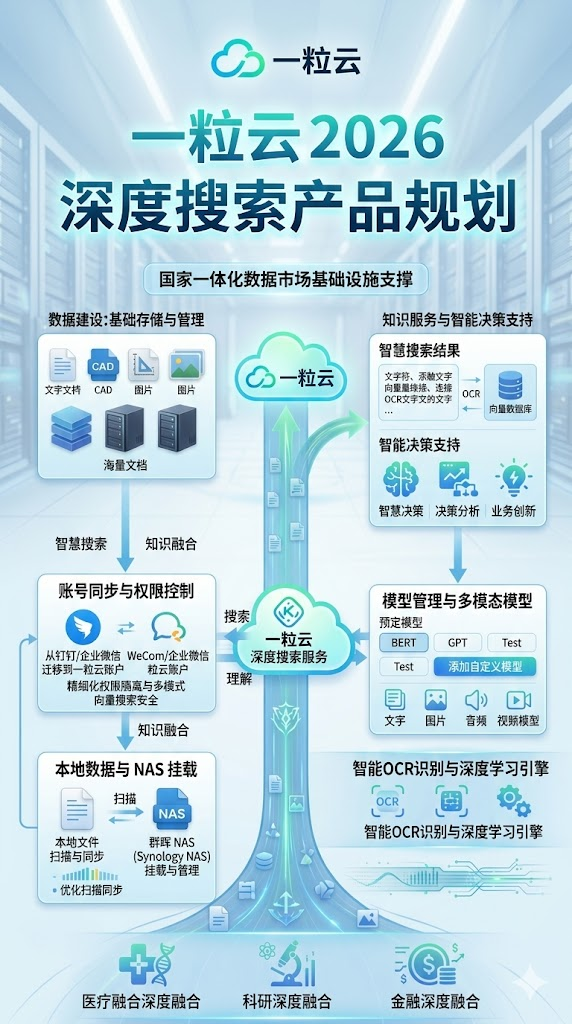
在数字经济浪潮席卷全球的当下,数据已成为驱动经济社会发展的核心引擎。”十五五”时期,作为我国数字中国建设的关键五年,数据要素基础制度建设、数据资源开发利用、数据安全治理等工作被提升到前所未有的战略高度。2026年全国两会期间,多位代表委员围绕数据工作提出重要建议,包括加强企业数据治理、建设可信数据空间、推动高质量数据集建设等。在此背景下,一粒云文档云底座凭借其统一文档管理、安全数据交换与智能知识挖掘的核心能力,正成为支撑”十五五”数据建设高质量发展的重要基础设施。
一、企业数据治理:筑牢数字赋能的”轨道”
全国人大代表陈国鹰在两会建议中明确提出,“十五五”时期要加强企业内部数据治理,以高质量数据筑牢数字赋能的”轨道”。企业数据治理是数字经济发展的基础性工程,涉及数据采集、存储、管理、应用全生命周期。
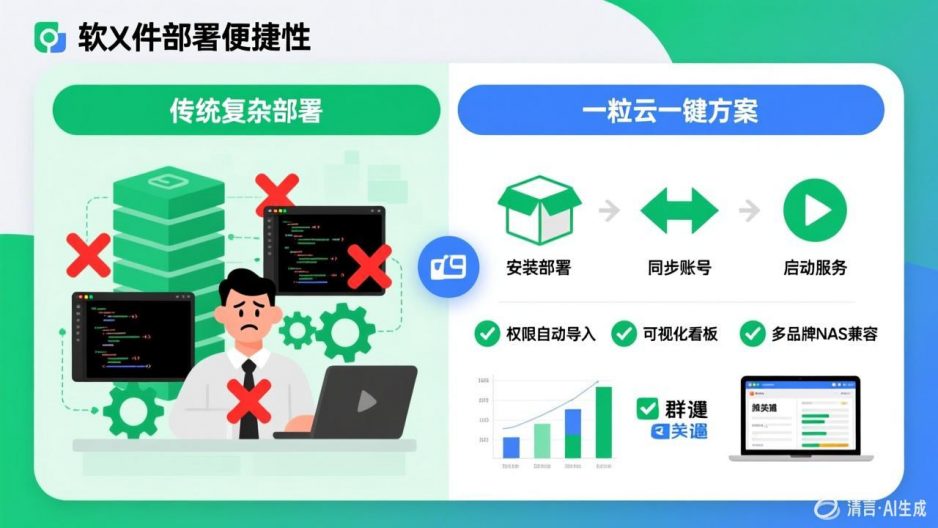
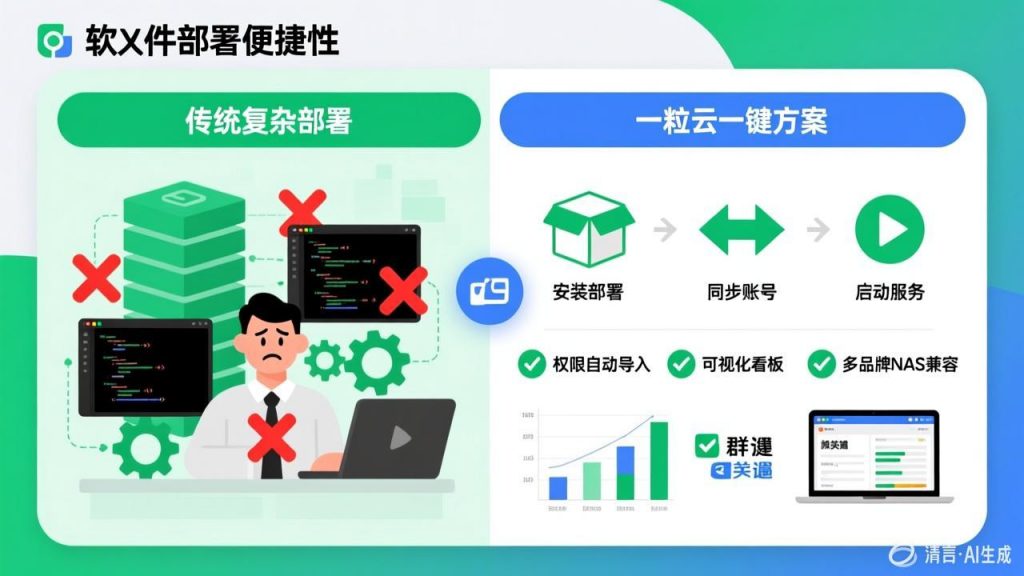
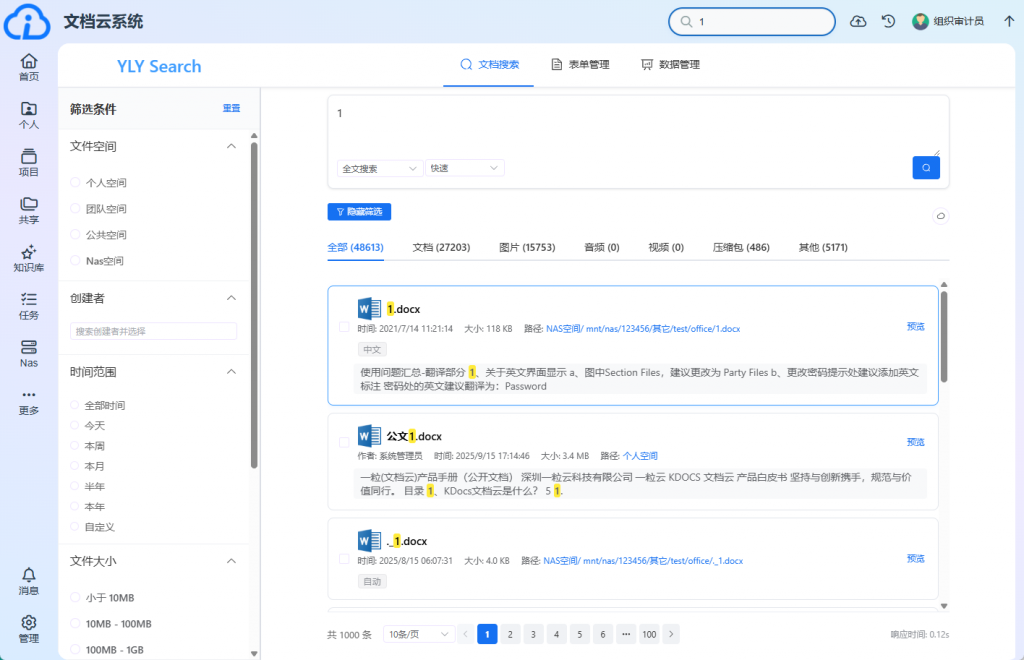
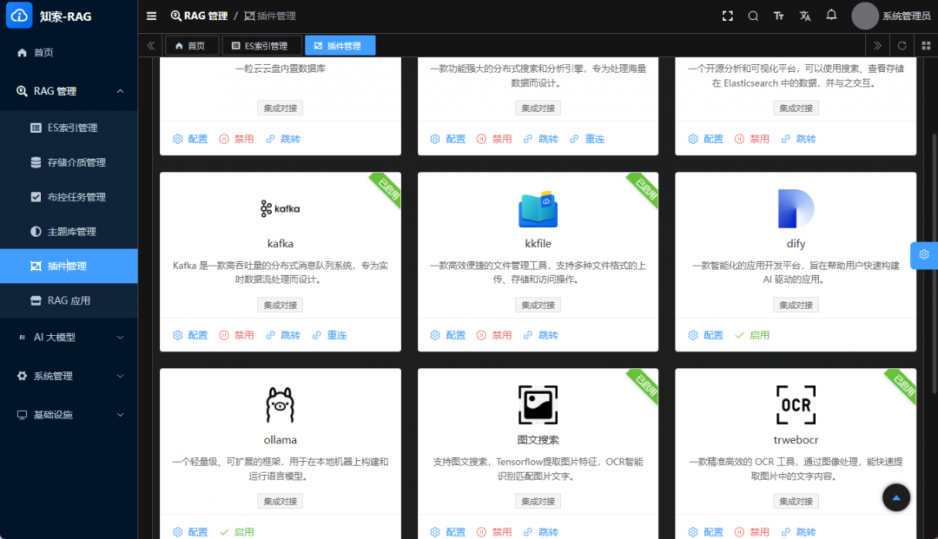
一粒云文档云底座中的KDocs系统,通过协同网盘、文控审批、多人协同编辑、知识库与多系统集成等功能,为企业构建了完整的文档数据治理体系。企业可在统一平台上实现文档的标准化管理、版本控制、流程审批与安全存储,确保数据资产的可追溯、可管控与高可用。系统支持多系统集成,能够与企业现有的OA、ERP等业务系统无缝对接,打通数据孤岛,实现数据的统一管理与共享复用。这种一体化的文档管理能力,为企业数据治理提供了坚实的平台支撑,助力企业从”经验决策”向”数据驱动”跨越。
二、可信数据空间:实现”数据不出域,价值可共享”
全国政协委员朱同玉提出建设”可信数据空间”的建议,推动医疗数据从”沉睡的资产”转变为”流动的引擎”。这一理念强调”数据不出域,知识可流通,价值可共享”,通过部署隐私计算与智算算力,构建统一的多模态通用数据模型,改变”数据搬家”的传统思路。
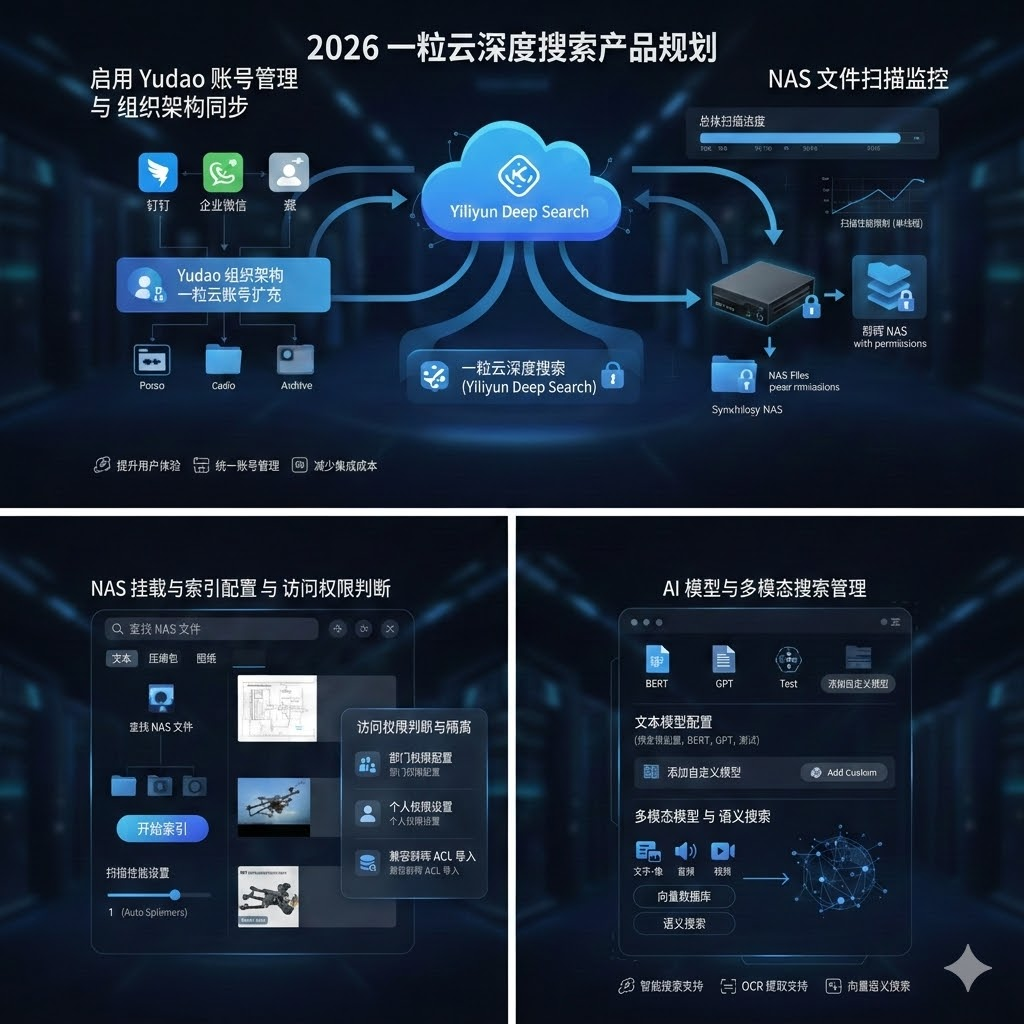
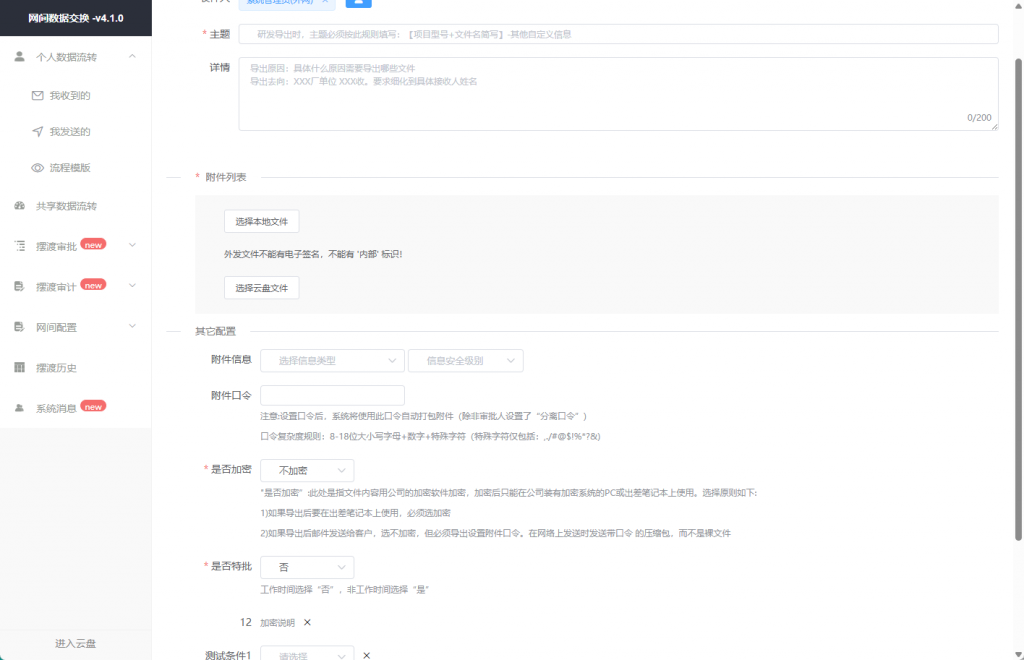
一粒云的KWS隔离网文件安全交换系统,正是构建可信数据空间的关键技术支撑。该系统集成了网盘功能、加解密、多网隔离、流程编排管理、数据内容检查审计以及AI辅助文件检查等功能,专为金融、科研、专网等高安全行业设计。在内外网文件交换过程中,系统能够确保原始数据始终留在本地,只流通经过脱敏处理的参数与结果,有效解决了数据流通中的安全与合规难题。
在医疗、金融等敏感行业,KWS系统支持授权人工智能企业的算法模型在本地运行,对数据进行本地化治理和训练,只带走参数和结果,原始数据始终留在机构内部。这种模式既保障了数据安全,又释放了数据价值,完美契合”十五五”期间对数据要素化配置与合规流通的要求。
三、高质量数据集建设:推动数据标准化与共享复用
全国政协委员蒋颖建议从三方面推动建设高质量数据集:构建统一标准体系、建立专项协调机制、强化应用导向。这些建议直指当前数据资源开发利用中的痛点问题——数据质量参差不齐、标准不统一、共享复用困难。
一粒云文档云底座通过统一的数据分类、元数据管理与质量评价体系,帮助企业实现存量数据的标准化改造。系统提供标准化的流程、工具模板与技术支持,降低了企业数据治理的负担。同时,平台支持成熟数据集纳入公共平台,实现共享复用,避免了重复建设与资源浪费。
在应用导向方面,系统要求项目立项明确使用场景,通过评审与监督确保建设成果匹配实际需求。这种以应用为导向的建设模式,确保了数据集的实用性与价值,为”十五五”期间数据资源的深度开发利用提供了有效路径。
四、数据安全与隐私保护:构建全流程安全防护体系
“十五五”规划明确提出,要坚持促进发展和规范管理相统筹,加强数据基础制度规则建设和人工智能治理,营造有益、安全、公平的发展环境。数据安全与隐私保护是数据建设的重要底线。
一粒云文档云底座通过多层次的安全机制,构建了全流程安全防护体系。系统采用文档加解密模块,防止文件终端泄密;数据备份系统提供基于文档、数据库、虚拟机的备份一体化管理,支持备份与还原的各种策略,确保数据可恢复;分布式存储平台为企业提供高可靠、高可用的存储服务,支持多种存储协议的完美融合。
更重要的是,KWS系统的多网隔离、数据内容检查审计与AI辅助文件检查功能,能够对数据流通进行全流程追溯与监控。在分级授权与全流程追溯机制方面,系统支持对科研用途的微观数据建立动态化、具体化的二次同意机制,对于经脱敏处理的匿名化数据,明确医疗机构作为应用管理的责任主体,并接受政府部门监管。这种精细化的权限管理与审计能力,为数据安全提供了坚实保障。
五、智能知识挖掘:从数据管理到智慧决策
陈国鹰代表在建议中还强调,要抓住人工智能快速迭代的”解锁”能力,深度耦合中国制造的”硬件”与”出海”优势,培育数字赋能新动能。这意味着数据建设不能止步于存储与管理,更要向智能化的知识服务转变。
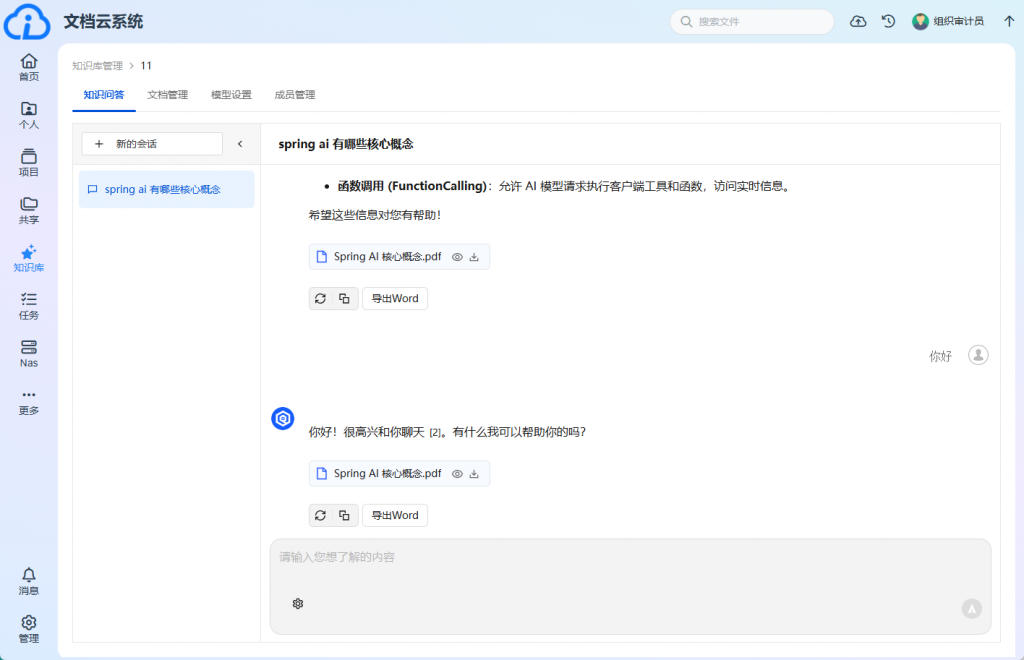
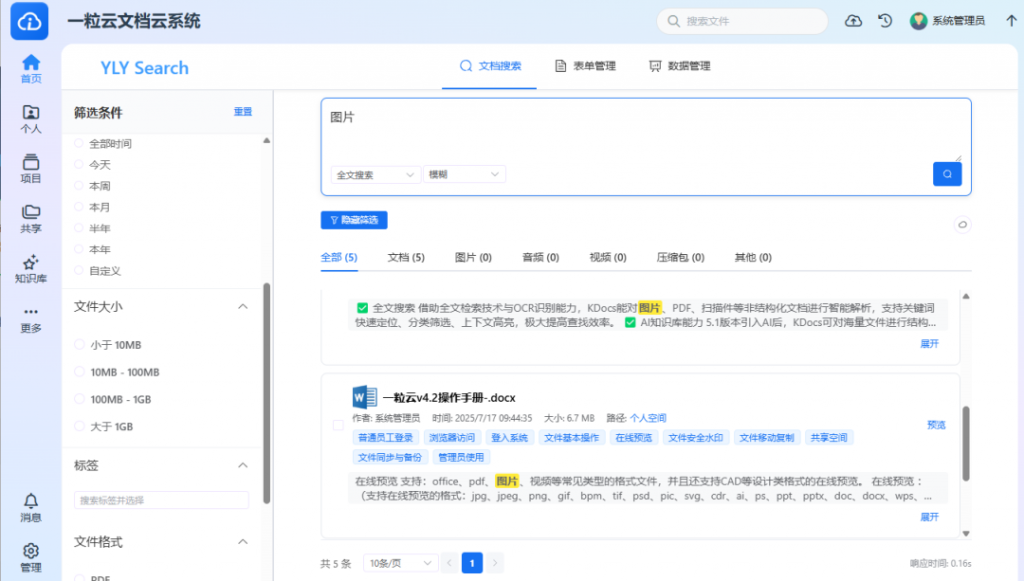
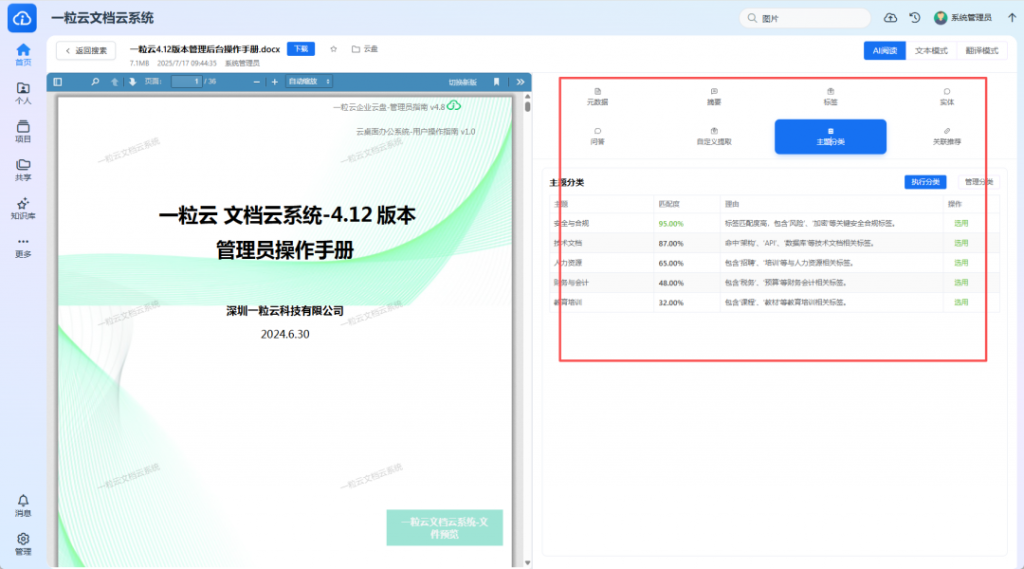
一粒云的知索-RAG知识引擎,通过AI技术与高效的权限管理,实现了从”信息检索”到”智慧决策”的跃迁。系统能够扫描现有数据,形成智慧搜索与知识引擎,帮助企业从海量文档中挖掘知识价值,支持决策分析与业务创新。
在医疗、科研、金融等行业,知索-RAG能够与行业数据深度融合,推动数据从简单的存储与管理向智能化的知识服务转变。例如,在医疗领域,系统能够帮助医院构建知识库,辅助医生进行诊断决策;在科研领域,系统能够帮助科研机构快速检索相关文献与数据,提升研发效率。这种智能知识挖掘能力,正是”十五五”期间推动数字赋能的重要抓手。

六、支撑全国一体化数据市场建设
“十五五”规划提出,要建设开放共享安全的全国一体化数据市场,深化数据资源开发利用。这要求构建跨地区、跨部门、跨行业的统一数据管理平台。
一粒云集团统一文档云建设方案,面向大型集团型企业,通过企业网盘、多用户协作编辑、分布式存储、集成隔离网文件交换、文档管理控制系统以及开放API等功能,为企业打造一个高度分布式、可扩展的文档云中台。该中台能够实现跨地区、跨国的统一管理,确保在全球范围内的业务运作中,文档的统一管理与无缝共享得以实现。通过这一平台,企业能够在严格的安全和合规要求下,实现全球协同,打造统一、高效的文档管理中枢。
这种跨地区、跨组织的统一文档管理能力,为全国一体化数据市场的建设提供了重要的基础设施支撑。

结语
“十五五”时期,数据建设已成为推动我国经济社会高质量发展的核心动力。从企业数据治理到可信数据空间建设,从高质量数据集开发到数据安全防护,从智能知识挖掘到全国一体化数据市场构建,每一项任务都需要坚实的技术平台支撑。
一粒云文档云底座以其统一文档管理、安全数据交换与智能知识挖掘的综合能力,为企业与行业提供了全方位的数据治理解决方案。它不仅能够帮助企业筑牢数据治理的”轨道”,实现”数据不出域,价值可共享”的可信数据空间,推动高质量数据集建设,构建全流程安全防护体系,还能通过智能知识挖掘释放数据价值,支撑全国一体化数据市场建设。
未来,随着”十五五”规划的深入实施,一粒云文档云底座将持续发挥其技术优势,助力我国数据要素市场建设与数字经济发展,为构建开放共享、安全可控的全国一体化数据市场贡献力量,推动我国数字经济高质量发展迈上新台阶。