摘要: 还在为找文件抓狂?还在担心用错版本?审计前手忙脚乱?别怕!这篇指南将手把手带你从0到1,搭建一个合规、高效、永不混乱的企业文控体系。
文件满天飞,版本满天飞,找文件靠“玄学”,审文件靠“眼力”。这不仅浪费了大量时间,更在关键时刻(如客户审核、ISO认证)埋下了巨大的风险隐患。
今天,我们就来终结这场混乱!我将用最直白的方式,手把手教你搭建一套专业的企业文控体系。记住这个核心公式:清晰的目录结构 + 严谨的流程 = 高效的文控体系。
第一步:设计“家”的蓝图——搭建文件夹目录体系
想象一下,如果你的家没有房间,所有东西都堆在客厅,那会是怎样的灾难?文件也是一样。我们需要为它们建一个结构清晰的“家”。
我们采用经典的“三级目录结构”,简单、高效,且完全符合ISO标准。
第一级:按“文件层级”划分
这是整个体系的“承重墙”,决定了文件的“身份”。通常分为四类:
- 01_手册类(纲领文件): 公司的“宪法”,如《质量手册》、《员工手册》。告诉大家我们的目标、原则和方向。
- 02_程序文件类(方法文件): “怎么做”的说明书,如《需求评审过程程序》、《采购管理程序》、《任务分配审核程序》。描述为了实现目标,需要跨部门协作的关键流程。
- 03_作业指导书类(操作文件): “具体干”的SOP,如《设备操作规范》、《代码编写规范》。给一线员工最具体、最细致的操作指南。
- 04_记录表单类(证据文件): “干完了”的凭证,如《会议纪要》、《检验报告》。证明我们按规矩办事了,是追溯和改进的依据。
💡 小技巧: 文件夹前加上
01_,02_这样的序号,可以强制排序,避免文件夹乱跑!
第二级:按“部门/过程”划分
在第一级的基础上,我们按“谁负责”或“什么事”来划分“房间”。
以一个软件公司为例(我们自己目录),它的结构长这样:
/公司文件体系/
├── 02_产品研发文件类/
│ ├── 研发部/ (按部门)
│ │ ├── 项目开发管理程序.docx
│ │ └── 代码评审程序.docx
│ ├── 测试部/
│ │ └── 缺陷管理程序.docx
│ └── 产品管理/ (按过程)
│ └── 需求变更管理程序.docx第三级:按“版本与状态”标识
这是防止“用错版”的最后一道防线!文件名必须包含关键信息。
推荐命名公式:文件名_V[版本号]_[YYYYMMDD]_[状态].docx
- 版本号: V1.0, V1.1, V2.0…
- 日期: 发布或修订日期
- 状态: 草稿、正式发布、作废
错误示范: 产品规格书最终版.docx (哪个最终?)
正确示范: 产品A规格书_V2.1_20231027_正式发布.pdf
第二步:制定“家规”——设计文件全生命周期流程
房子建好了,得有“家规”来维护。文件从“出生”到“消亡”,每个环节都要有章可循。这就是ISO强调的“全生命周期管理”。
这个流程就像一条流水线:编制 → 审核 → 批准 → 发布 → 使用 → 修订 → 作废。
![一个简单的流程图示意:编制 -> 审核 -> 批准 -> 发布 -> 使用 -> 修订 -> 作废,并循环回修订]
- 编制: 谁来写?“谁用谁编”。研发部写研发的指导书,生产部写生产的规程。确保内容接地气,不搞“两张皮”。
- 审核: 谁来看?“相关方会审”。技术文件让技术专家看,管理程序让管理层看。确保内容合规、可行。
- 批准: 谁来拍板?“授权人批准”。通常是部门负责人或管理者代表。批准后,文件才具备“合法身份”。
- 发布: 怎么发?“精准发放,记录在案”。通过《文件发放回收记录表》,确保每个需要的人都能拿到最新版,并且有据可查。
- 使用与维护: 怎么管?“定期评审,及时反馈”。每年至少“大扫除”一次,看看文件是否还适用。发现问题,立刻提交《文件修订申请单》。
- 修订与作废: 怎么更新?“闭环管理,防止误用”。新文件发布,必须同步回收所有旧版本。作废文件要盖章、隔离存放,电子版要移入“作废区”,彻底杜绝“死灰复燃”。
第三步:选择“工具”——让体系高效运转
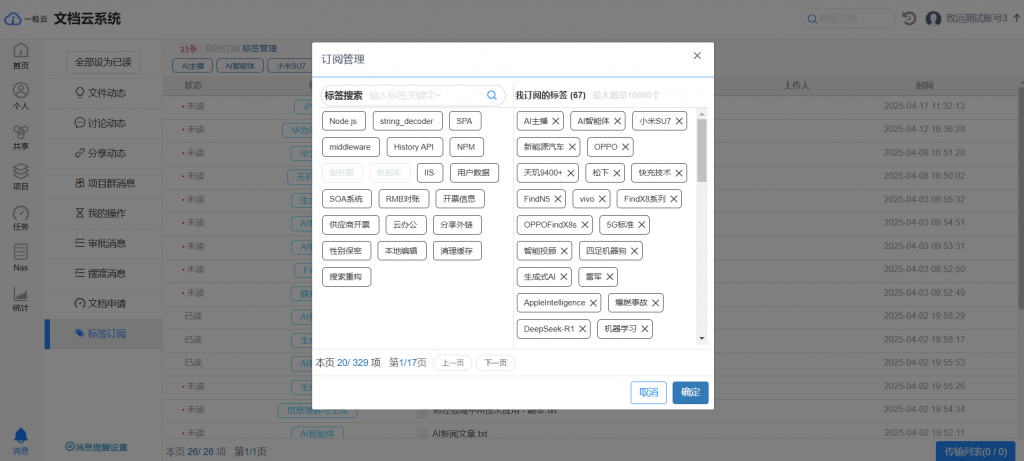
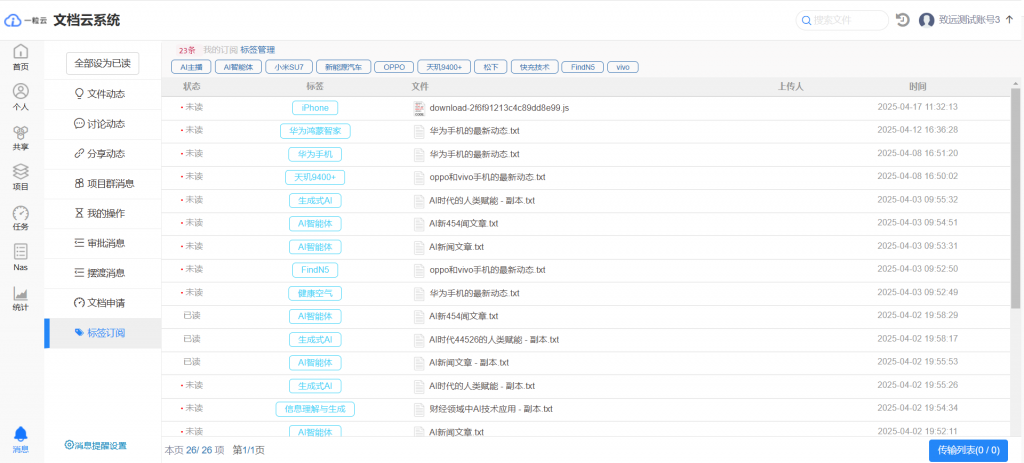
好的流程需要好的工具来承载。这里当然是推荐我们自己一粒云文档云一体化管理系统啦!两个版本给您选择:1,选择一粒云文档云 2,选择统一文档云系统。
| 对比维度 | 一粒云文档云盘 (中小) | 统一文档云系统 (重大) |
|---|---|---|
| 核心定位 | 协同办公工具:专注于团队文件同步、共享与协作,快速提升办公效率。 | 数据资产管理平台:专注于企业级文档集中管控、安全存储与知识沉淀,保障数据资产安全。 |
| 目标用户 | 中小企业、初创团队、项目小组、部门级应用。 | 中大型企业、集团公司、政府及事业单位、对数据安全有高要求的组织。 |
| 功能复杂度 | 核心功能精炼界面简洁,开箱即用,学习成本低。 | 功能全面且强大模块化设计,支持深度定制与二次开发。 |
| 权限管理 | 基于部门、角色的权限设置ACL,满足日常协作与外发管控需求。 | 多层级、细颗粒度权限,ISO文控,复杂流程审批,可控制到文件/文件夹的预览、下载、打印、复制、水印等操作。 |
| 系统集成 | 提供标准API接口,可实现基础对接。 | 深度集成能力,可无缝对接AD/LDAP域控、OA、ERP、CRM等企业现有系统。 |
| 安全与合规 | 基础的数据传输与存储加密、操作日志。 | 企业级安全防护,满足等保要求,支持数据防泄漏(DLP)、详细的审计追溯、文件加密、安全沙箱等。 |
| 服务与支持 | 标准化的在线客服、工单支持。 | 专属客户经理、7×24小时技术支持、定制化培训服务、现场实施保障。 |
| 适用场景 | – 日常办公文档同步 – 项目资料共享 – 团队协同编辑 – 替代公有网盘 | – 企业研发资料管理 – 集团法务合同管理 – 全公司统一知识库平台 – 替代不安全的传统FTP/NAS |
今天就开始行动吧!
- 第一步: 拉上你的同事,按照本文的“三级目录结构”,先设计出你们公司的文件夹蓝图。
- 第二步: 简化设计出你们的“文件生命周期流程图”,明确每个环节的负责人。
- 第三步: 选择一个适合你们当前阶段的工具,开始试点运行。
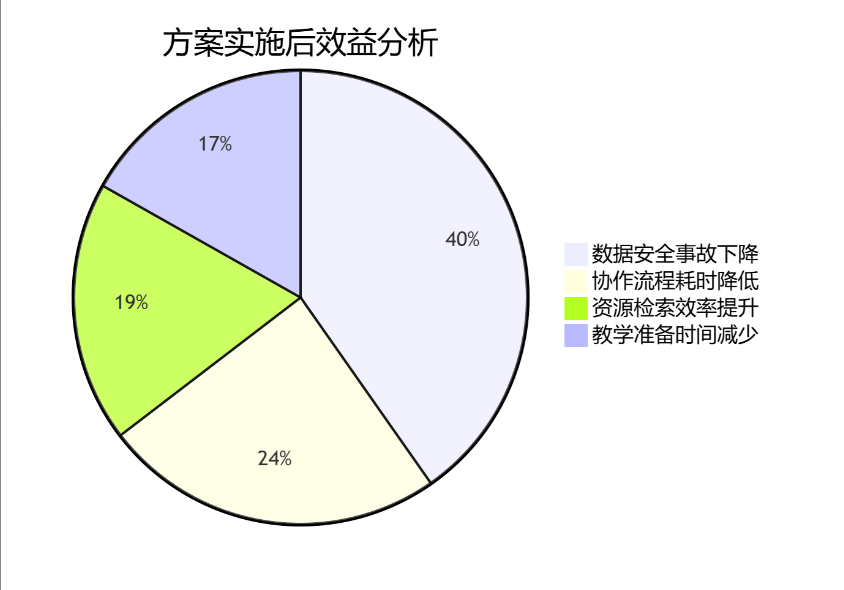
从今天起,让文件管理成为你公司的核心竞争力,而不是拖后腿的“黑洞”。
如果你还有更加严格ISO 9001标准体系化的=的文控管理需求,请阅读并下载下一篇的《ISO文控体系建设指南》,让您轻松切换成企业的资产大管家!