目录
前言:本文介绍如何在系统添加新的存储并扩容到一粒云
一粒云服务器系统登陆账号:root密码yliyun!@#$
第一章 CentOS系统添加磁盘存储
一.1. 查看系统磁盘状况
前提是先将磁盘或者外接存储连接到服务器上
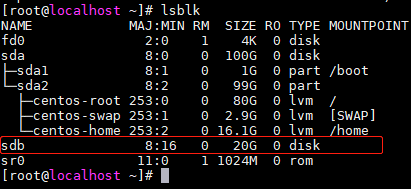
登陆服务器,在命令行终端输入命令,列出系统上所有可用磁盘设备信息
lsblk
从下图可以看出sdb为新增20G的空闲磁盘,并未分区
一.2. 给磁盘分区(手动磁盘分区,linux 小白谨慎操作哦)
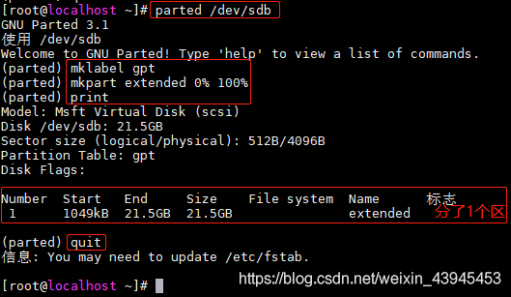
1)进入parted分区工具(sdb 是视实际情况的盘符编号)
parted /dev/sdb
2)设置分区类型为gpt
mklabel gpt
3)如果有提示yes/no,那么要yes确认
yes
4)扩展分区extended ,主分区primary ,并使用整个硬盘
mkpart extended 0% 100%
5)查看一下
6)退出工具
quit
一.3. 格式化磁盘分区
格式化为xfs分区(因为给sdb只分了1个区,所以分区名称为sdb1)
mkfs.xfs /dev/sdb1
如果提示已有其他文件系统创建在此分区加-f参数 mkfs.xfs -f /dev/sdb1
一.4. 挂载新磁盘到/opt目录下
mount /dev/sdb1 /opt
或者mount -t xfs /dev/sdb1 /opt
如果挂载新磁盘到/opt目录之前,有文件存放在/opt目录下那将看不到之前的文件了,需要卸载磁盘后,先将之前/opt目录下的文件移动到其他位置,再挂载。卸载磁盘命令为:
umount /dev/sdb1
一.5. 设置开机自动挂载
1)查看磁盘信息,确定已经成功挂载到/opt目录下
lsblk -f
从下图可以看出sdb1已经挂载到/opt目录下了
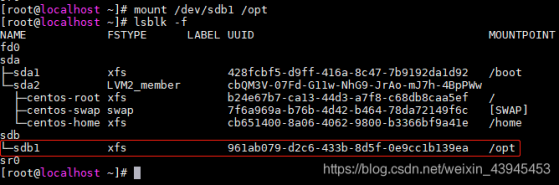
上图中每一列的含义:
NAME:磁盘名称和磁盘分区的名称
FSTYPE:文件系统类型
LABEL UUID:磁盘的UUID
MOUNTPOINT:磁盘的挂载点
2)编辑配置文件
vi /etc/fstab
在最后一行填写/dev/sdb1 /opt xfs defaults 0 0
编辑完毕后按Esc键,输入:wq回车,保存退出
如下图
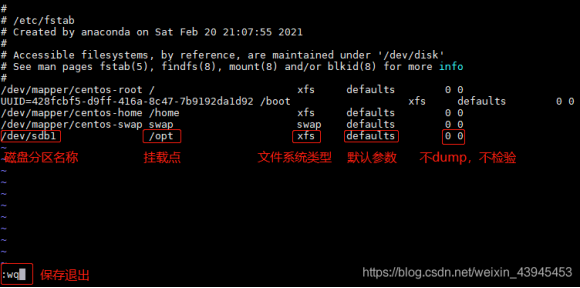
谨慎操作,上图中任意信息填错将会导致系统无法正常开机
一.6. 重启服务器,验证是否开机自动挂载磁盘
reboot
如果导致无法正常开机,基本都是第5步骤信息填写错误:
1、开机后按提示输入root密码;
2、mount -o remount,rw / #使根目录下的文件可主读写
3、vi /etc/fstab #修改错误的地方
第二章 一粒云存储配置
如果系统已经挂载好了新存储,仅需要添加到一粒云存储中
Mount 挂载新磁盘到文件系统(参考)
mount /dev/sdb /yliyun_data
二.1. 存储配置文件说明
一粒云存储配置文件有两个,当修改时两个都需要修改
/opt/yliyun/fdfs/etc/storage.conf
/opt/yliyun/fdfs/etc/mod_fastdfs.conf
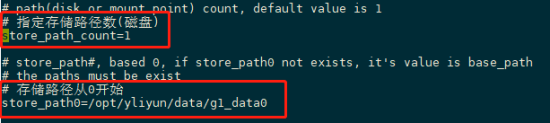
- 配置中store_path_count=1参数默认1,如果新增1条存储,那需要改为2,以此类推。
- 配置中store_path0=/opt/yliyun/data/g1_data0 为云盘默认的存储位置,可修改。
- 如果要更改默认存储路径,修改store_path0=/opt/yliyun/data/g1_data0为store_path0=‘新的路径’
- 如果要新增存储,在store_path0的下一行添加store_path1=’你的存储挂载路径’,以此类推。
默认新系统做法
(没有数据的情况下,直接修改地址为挂载路径,其它配置不变):
store_path0=/yliyun_data
二.2. 重启服务
/opt/yliyun/bin/fdfs stop
/opt/yliyun/bin/fdfs start
/opt/yliyun/bin/nginx restart
二.3. 测试
- 等待几秒后,查看云盘【系统概览】内的磁盘大小
- 上传、下载、预览多个文件是否成
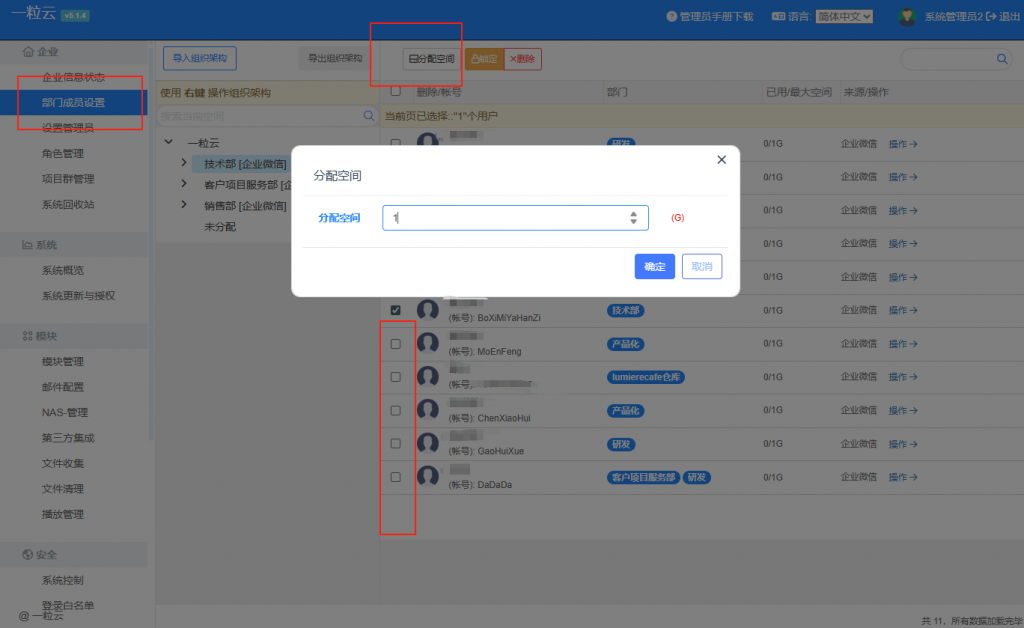
手动分配用户空间,请进入到管理后台按下图操作