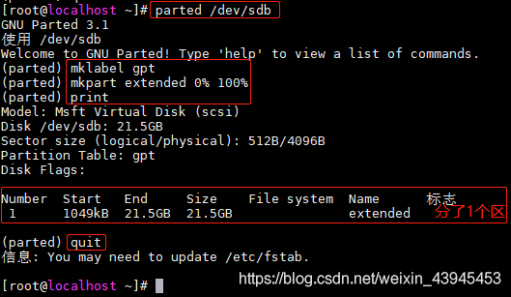
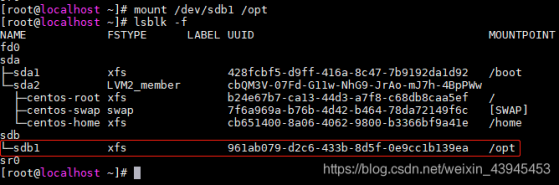
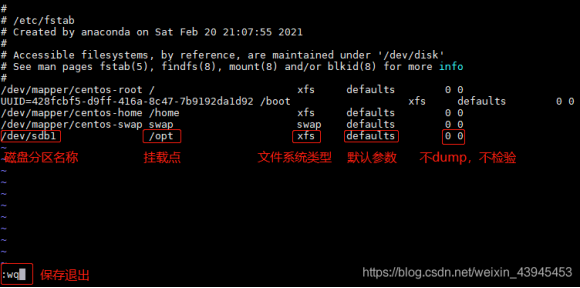
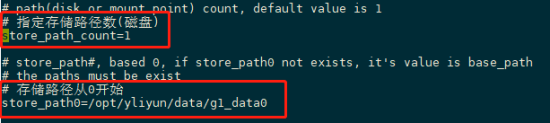
适用于一粒云及合作方的所有软件产品交付、内部测试包、客户升级包、补丁包等文件管理。
1. 文件夹结构总览
产品发布/
├─ 01_Release_正式版/
│ ├─ V1.0.0_20251103/
│ │ ├─ Build/
│ │ │ ├─ Backend/
│ │ │ ├─ Frontend/
│ │ │ └─ Installer/
│ │ ├─ Docs/
│ │ │ ├─ ReleaseNote_V1.0.0.md
│ │ │ ├─ InstallationGuide_V1.0.0.pdf
│ │ │ ├─ UpgradeManual_V1.0.0.pdf
│ │ ├─ Scripts/
│ │ │ ├─ DB_Update/
│ │ │ ├─ Migration/
│ │ │ └─ Patch/
│ │ ├─ Tools/
│ │ └─ License/
│ ├─ V1.1.0_20251210/
│ └─ ...
├─ 02_Release_RC测试包/
│ ├─ RC1_20251020/
│ ├─ RC2_20251028/
├─ 03_Patch_补丁包/
│ ├─ V1.0.0_P1_20251115/
│ └─ V1.0.0_P2_20251202/
├─ 04_Upgrade_升级包/
│ ├─ V1.0.0_to_V1.1.0_20251210/
│ └─ V1.1.0_to_V1.2.0_20260201/
├─ 05_Hotfix_紧急修复/
│ ├─ HF_20251108_SQLFix/
│ ├─ HF_20251110_APIAuth/
└─ 06_Backup_归档/
├─ 每次发布的完整打包备份
2. 文件与包命名规则
(1)正式发布包命名
[产品名称]_Release_V[主版本号].[次版本号].[修订号]_[日期]
示例:
YLYCloud_Release_V1.0.0_20251103.zip
SmartRAG_Release_V2.1.0_20251201.tar.gz
(2)测试与候选版本命名(RC / Beta)
[产品名称]_RC[序号]_V[版本号]_[日期]
[产品名称]_Beta_V[版本号]_[日期]
示例:
YLYCloud_RC2_V1.0.0_20251028.zip
AIInsight_Beta_V0.9.1_20251012.zip
(3)补丁包命名
[产品名称]_Patch_V[主版本号].[次版本号]_P[补丁号]_[日期]
示例:
YLYCloud_Patch_V1.0_P1_20251115.zip
(4)升级包命名
[产品名称]_Upgrade_V[旧版本]_to_V[新版本]_[日期]
示例:
YLYCloud_Upgrade_V1.0.0_to_V1.1.0_20251210.zip
(5)紧急修复包(Hotfix)
[产品名称]_HF_[日期]_[修复模块]
示例:
YLYCloud_HF_20251108_DBIndexFix.zip
3. 每个版本包必须包含的文件
| 文件名 | 内容说明 |
|---|---|
| ReleaseNote_VX.X.X.md | 发布说明,包括新增功能、修复列表、兼容性变化 |
| InstallationGuide_VX.X.X.pdf | 安装指南(分Windows/Linux) |
| UpgradeManual_VX.X.X.pdf | 升级步骤说明 |
| RollbackGuide_VX.X.X.pdf | 回退说明(可选) |
| VersionInfo.json | 系统自动读取的版本配置 |
| checksum.txt | 包文件的完整性校验信息(MD5/SHA256) |
| License.txt | 许可证说明 |
| build.log | 构建日志(供回溯) |
4. ReleaseNote 模板(Markdown 格式)
# Release Note - 一粒云文档云 V1.0.0
发布日期:2025-11-03
构建版本号:1.0.0
构建环境:Linux + Node 20 + .NET 8
---
## 🆕 新增功能
- 新增文件AI分类功能
- 支持Markdown智能分段与检索
- 增加在线PDF转Word功能
## 🔧 修复内容
- 修复文件预览空白的问题
- 优化索引服务稳定性
## ⚙️ 兼容性变化
- 前端最低浏览器要求:Chrome 100+
- 不再支持旧版Node 16环境
## 🧩 部署说明
1. 备份数据库与`/data`目录;
2. 执行`/Scripts/DB_Update/20251103.sql`;
3. 替换`/api`与`/ui`目录;
4. 重启服务。
## 📦 附录
- 安装包:YLYCloud_Release_V1.0.0_20251103.zip
- 校验码:`SHA256: 5acb2d12f...`
5. 升级包结构规范
YLYCloud_Upgrade_V1.0.0_to_V1.1.0_20251210/
├─ UpgradeManual_V1.1.0.pdf
├─ DB_Scripts/
│ ├─ 20251210_UpdateSchema.sql
│ ├─ 20251210_AddIndex.sql
├─ Backend/
│ ├─ bin/
│ └─ config/
├─ Frontend/
│ └─ dist/
├─ Tools/
│ ├─ upgrade.sh
│ └─ rollback.sh
├─ VersionInfo.json
└─ checksum.txt
注意事项:
- 升级包必须可回退;
- 变更数据库结构的脚本需带“安全回退”版本;
- 每次发布后将包上传到公司 一粒云文档云 / 产品发布库;
- 发布流程必须由开发、测试、实施三方签字确认。
6. 内部规范配套措施
- 所有正式发布包由“产品负责人 + QA + 实施经理”三方签字确认。
- 每次发布均需自动生成
VersionInfo.json与checksum.txt,支持自动校验。 - 一粒云文档云后台应配置“版本发布管理模块”,统一归档。
- 内部开发环境、客户版本库、测试服务器保持命名一致。
- 版本号管理遵循 语义化版本控制(SemVer 2.0):
- 主版本号(Major):有不兼容变更;
- 次版本号(Minor):兼容新增;
- 修订号(Patch):兼容修复。