* Running on all addresses (0.0.0.0) * Running on http://127.0.0.1:9380 * Running on http://x.x.x.x:9380 INFO:werkzeug:Press CTRL+C to quit如果您跳过此确认步骤并直接登录 RAGFlow,您的浏览器可能会提示错误,因为此时您的 RAGFlow 可能没有完全初始化。network abnormal
在您的 Web 浏览器中,输入服务器的 IP 地址并登录 RAGFlow。使用默认设置时,您只需输入 (sans port number) 作为使用默认配置时可以省略默认 HTTP 服务端口。http://IP_OF_YOUR_MACHINE80
在 service_conf.yaml 中,选择所需的 LLM 工厂,并使用相应的 API 密钥更新字段。user_default_llmAPI_KEY有关更多信息,请参阅 llm_api_key_setup。
from langchain_openai import ChatOpenAI, OpenAIEmbeddings import os os.environ["OPENAI_API_KEY"] = "*****" openai_api_key = os.environ["OPENAI_API_KEY"] openai_llm_model = llm = ChatOpenAI( model="gpt-4o-mini", temperature=0, max_tokens=None, timeout=None, max_retries=2, ) messages = [ ( "system", "You are a helpful assistant that translates English to French. Translate the user sentence.", ), ("human", "I love programming."), ]
ai_msg=openai_llm_model.invoke(messages)
开始部署我们的 Embedding 模型:
from langchain_huggingface.embeddings import HuggingFaceEmbeddings openai_embeddings_model = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5") text = "This is a test document." query_result = openai_embeddings_model.embed_query(text) query_result[:3] doc_result = openai_embeddings_model.embed_documents([text])
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader(f"./CV_Emily_Davis.pdf") pages = loader.load_and_split()
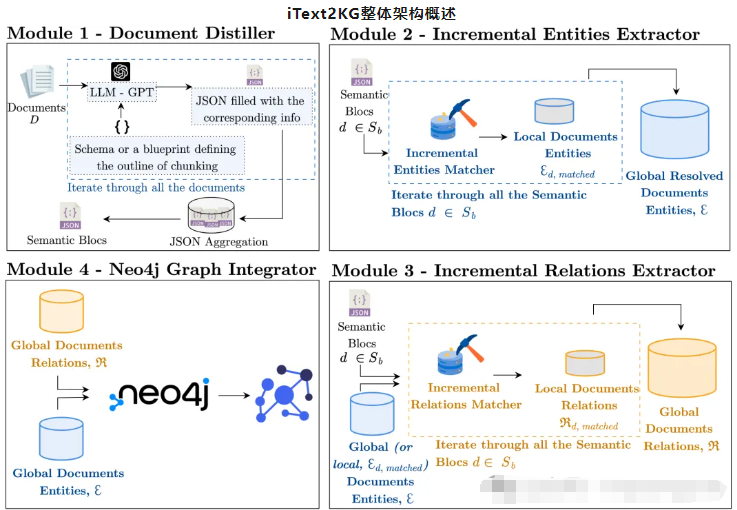
初始化 DocumentDistiller 引入 llm :
from itext2kg.documents_distiller import DocumentsDisiller, CV document_distiller = DocumentsDisiller(llm_model = openai_llm_model)
信息提炼:
IE_query = ''' # DIRECTIVES : - Act like an experienced information extractor. - You have a chunk of a CV. - If you do not find the right information, keep its place empty. ''' # 使用定义好的查询和输出数据结构提炼文档。 distilled_cv = document_distiller.distill(documents=[page.page_content.replace("{", '[').replace("}", "]") for page in pages], IE_query=IE_query, output_data_structure=CV)
将提炼后的文档格式化为语义部分。
semantic_blocks_cv = [f"{key} - {value}".replace("{", "[").replace("}", "]") for key, value in distilled_cv.items() if value !=[] and value != "" and value != None]
我们可以自定义输出数据结构,我们这里定义了4种,工作经历模型,岗位,技能,证书。
from pydantic import BaseModel, Field from typing import List, Optional
class JobResponsibility(BaseModel): description: str = Field(..., description="A specific responsibility in the job role")
class JobQualification(BaseModel): skill: str = Field(..., description="A required or preferred skill for the job")
class JobCertification(BaseModel): certification: str = Field(..., description="Required or preferred certifications for the job")
class JobOffer(BaseModel): job_offer_title: str = Field(..., description="The job title") company: str = Field(..., description="The name of the company offering the job") location: str = Field(..., description="The job location (can specify if remote/hybrid)") job_type: str = Field(..., description="Type of job (e.g., full-time, part-time, contract)") responsibilities: List[JobResponsibility] = Field(..., description="List of key responsibilities") qualifications: List[JobQualification] = Field(..., description="List of required or preferred qualifications") certifications: Optional[List[JobCertification]] = Field(None, description="Required or preferred certifications") benefits: Optional[List[str]] = Field(None, description="List of job benefits") experience_required: str = Field(..., description="Required years of experience") salary_range: Optional[str] = Field(None, description="Salary range for the position") apply_url: Optional[str] = Field(None, description="URL to apply for the job")
定义一个招聘工作需求的描述:
job_offer = """ About the Job Offer THE FICTITIOUS COMPANY
FICTITIOUS COMPANY is a high-end French fashion brand known for its graphic and poetic style, driven by the values of authenticity and transparency upheld by its creator Simon Porte Jacquemus.
Your Role
Craft visual stories that captivate, inform, and inspire. Transform concepts and ideas into visual representations. As a member of the studio, in collaboration with the designers and under the direction of the Creative Designer, you should be able to take written or spoken ideas and convert them into designs that resonate. You need to have a deep understanding of the brand image and DNA, being able to find the style and layout suited to each project.
Your Missions
Translate creative direction into high-quality silhouettes using Photoshop Work on a wide range of projects to visualize and develop graphic designs that meet each brief Work independently as well as in collaboration with the studio team to meet deadlines, potentially handling five or more projects simultaneously Develop color schemes and renderings in Photoshop, categorized by themes, subjects, etc. Your Profile
Bachelor’s degree (Bac+3/5) in Graphic Design or Art 3 years of experience in similar roles within a luxury brand's studio Proficiency in Adobe Suite, including Illustrator, InDesign, Photoshop Excellent communication and presentation skills Strong organizational and time management skills to meet deadlines in a fast-paced environment Good understanding of the design process Freelance cont
继续使用上面方法做信息提炼:
IE_query = ''' # DIRECTIVES : - Act like an experienced information extractor. - You have a chunk of a job offer description. - If you do not find the right information, keep its place empty. ''' distilled_Job_Offer = document_distiller.distill(documents=[job_offer], IE_query=IE_query, output_data_structure=JobOffer) print(distilled_Job_Offer) semantic_blocks_job_offer = [f"{key} - {value}".replace("{", "[").replace("}", "]") for key, value in distilled_Job_Offer.items() if value !=[] and value != "" and value != None]