版本定位:针对企业「多系统割裂、协作低效」的核心痛点,聚焦系统集成、安全强化、效率闭环三大方向,将致远/蓝凌/以及之前集成过的泛微OA、金蝶云之家、企业微信消息等工具整合为统一办公中枢,助力组织降低协作成本。
一、全链路系统集成:从“跨平台切换”到“统一入口”
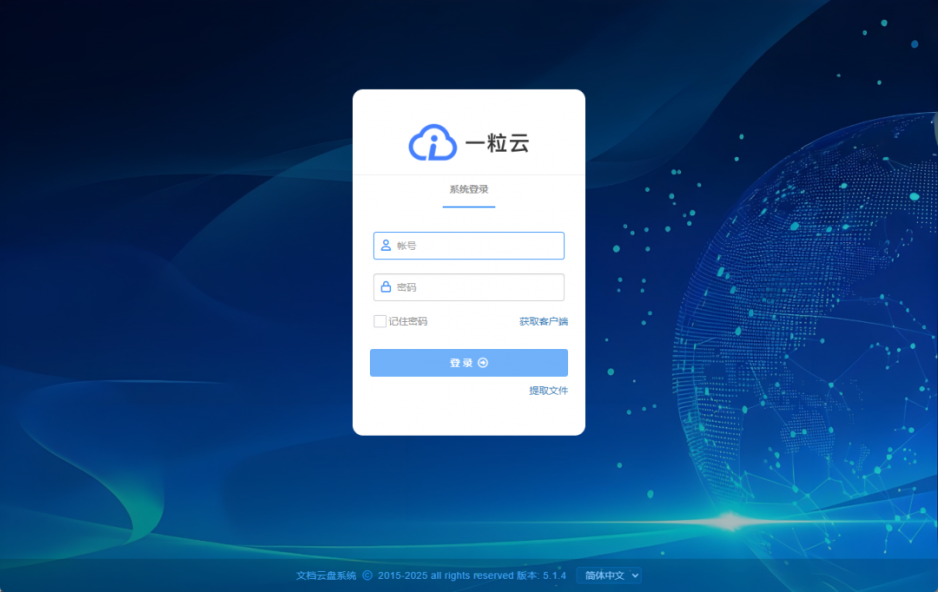
一粒云5.1.4本次更新实现与致远OA、蓝凌OA、金蝶云之家、企业微信消息、布谷智慧校园的深度对接,覆盖企业更多核心办公场景:
- 单点登录(SSO):用户无需重复输密码,点击云盘即可直达OA审批页,降低密码管理成本;
- 消息与文件互通:OA待办提醒、文件修改通知实时推送至云盘,云盘文件可直接嵌入OA页面预览,实现云盘文件在OA中的穿透,避免“下载-发送-再打开”的繁琐;
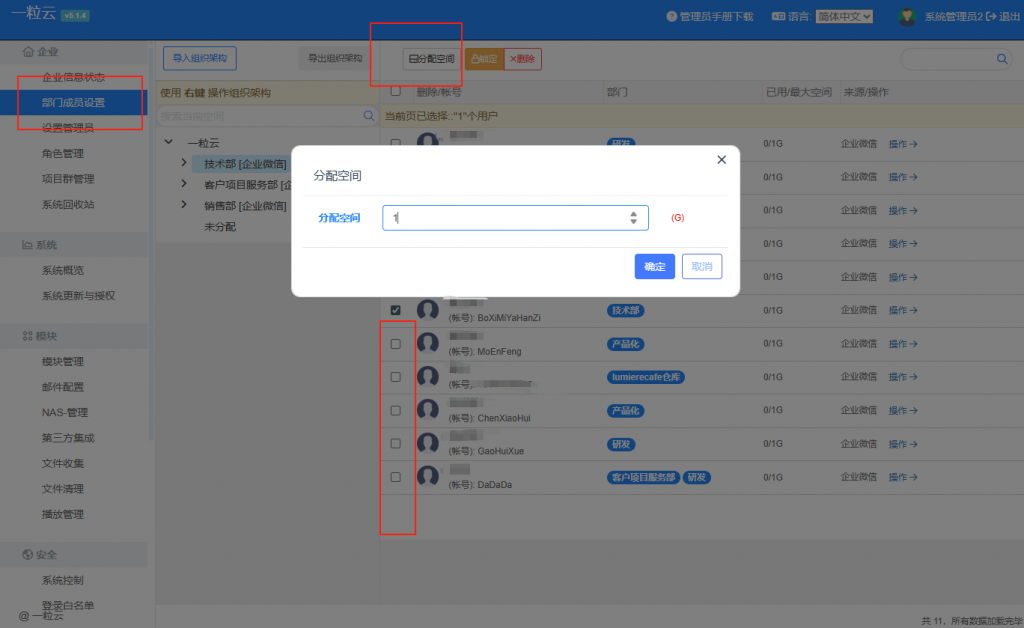
- 组织架构同步:蓝凌/金蝶/泛微/用友/竹云/致远/通达/钉钉/企微的组织架构自动同步至云盘,权限管理精准度提升,杜绝“越权访问”风险。
- 审批流程打通:云盘审批已经实现对接 蓝凌/金蝶 2个品牌的审批功能,在云盘发起,在OA上审批,审批结果返回到云盘的整合。
本次更新集成列表:
- 致远OA单点登录
- 致远OA消息推送互通
- 致远OA文件穿透到云盘
- 蓝凌OA单点登录
- 蓝凌OA组织架构集成对接
- 蓝凌OA审批流集成
- 金蝶云之家单点登录
- 金蝶云之家架构集成对接
- 金蝶云之家OA审批流集成
- 布谷智慧校园单点登录集成
- 布谷智慧校园组织架构集成对接
- 企业微信应用消息互通
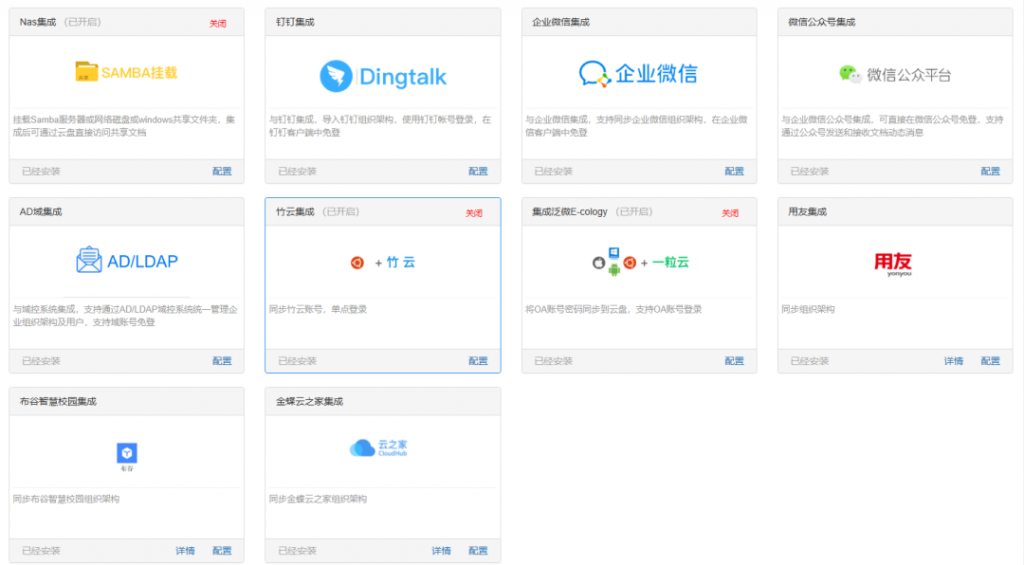
二、AI与安全兼容双加固:智能守护企业数据资产
针对企业最关心的「AI能力提升」「数据安全」与「多设备适配」问题,版本做了关键升级:
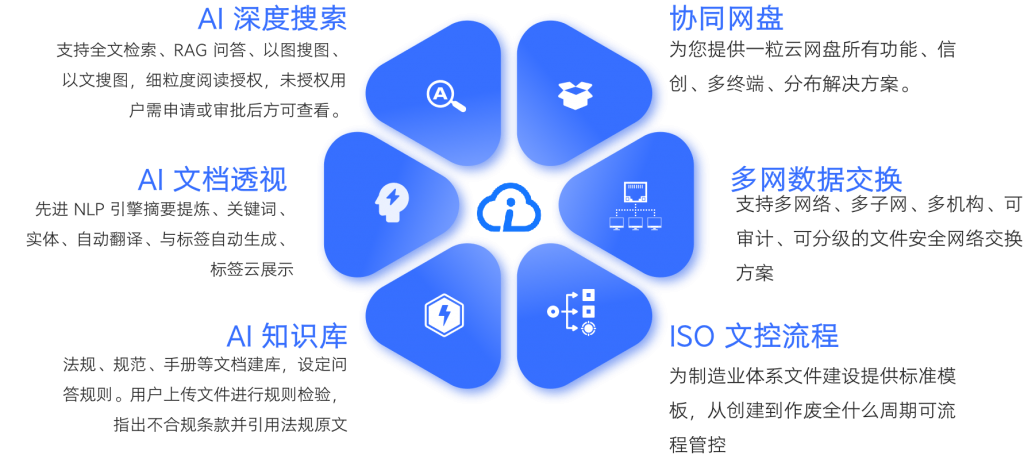
- 无缝集成新产品知索RAG,AI搜索更加高效与准确
- 新增AI辅助阅读,新增8大AI模块(集成知索rag,详情见rag系统介绍)
- 自定义动态水印:支持“用户ID+时间+部门”的组合水印,可针对文件、文件夹自定义设置,覆盖内部分享、外部传输场景,有效防止文件截屏泄密;
- 全平台兼容:完美适配鸿蒙Next、新版iOS及H5端,解决此前文件下载卡顿、预览变形的问题;
- bugfix:
- 修复全盘搜索的权限问题
- 修复将ipgurad集成后文件清除逻辑文件索引状态展示
- 修复文件名后缀允许和不允许修改状态bug
- 修复外链到期后消息推送到企业微信bug
- 修复AD域绑定部门被删除后无法同步等问题
- 修复了文件本地编辑锁住后依然能使用wps、onlyoffice 等web在线编辑的问题
- 修复部分NAS文件导入到云盘重命名与不能预览等问题
- 等等
三、效率工具闭环:优化文件生命周期管理
新增功能聚焦「文件管理最后一公里」:
- 文件有效期:可为文件快捷设置30天60天90天/永久的有效期,到期自动推送企业微信提醒;
- 内部分享直连:分享文件时自动生成带跳转链接的企业微信消息,同事点开即可访问,省去“发长串路径”的沟通成本。
- 本次更新清单:
- 新增文件有效期,到期消息可推送到企业微信
- 新增内部分享消息推送到企业微信,并附带跳转链接
- 新增第三方调用云盘接口采用统一的apikey认证
- 新增onlyoffice9版本的jwt认证
- 新增全文搜索页面打包下载增加下载进度和文件压缩进度展示
- 等等
一粒云5.1.4不是功能堆砌,而是以“用户协作场景”为核心的系统重构。通过打通工具、强化安全、优化效率,帮助企业从“多系统作战”转向“统一平台运营”,真正实现降本增效。
欢迎广大客户、渠道商安装和体验,我们为客户准备了一键安装包和小规模永久使用账号可以快速体验或长期使用。