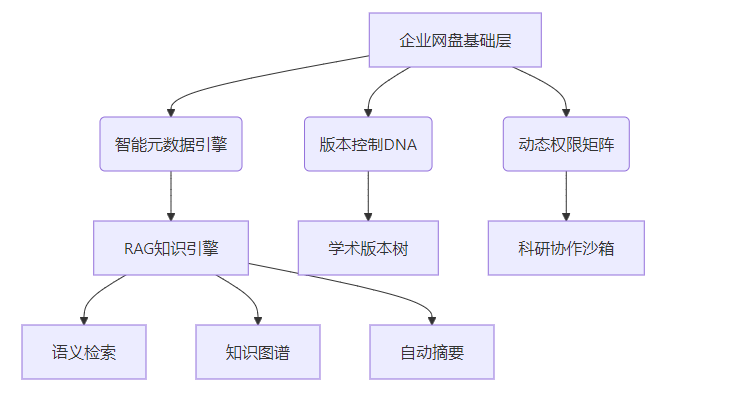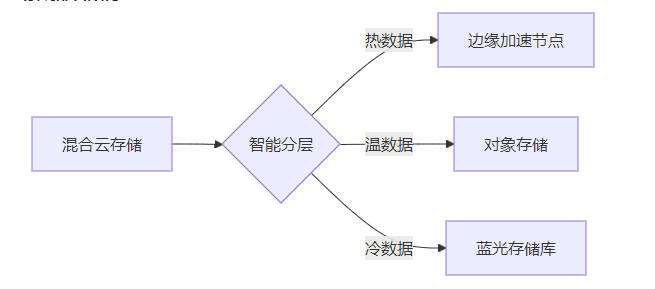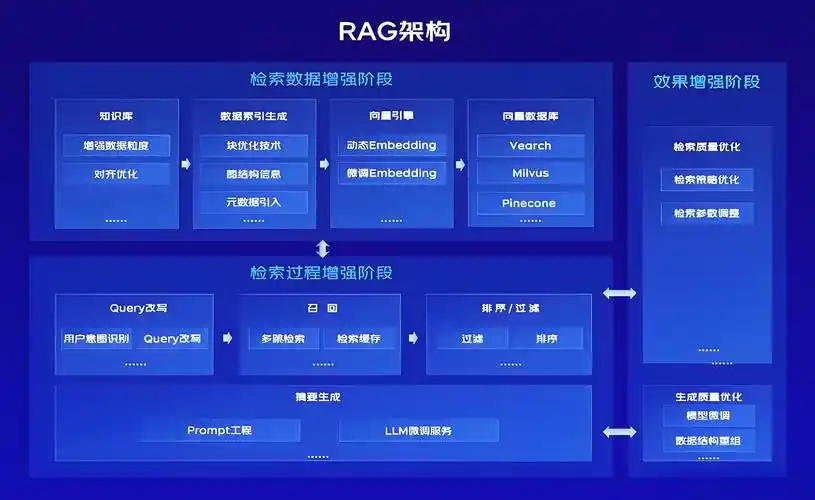
通过一粒云知索RAG(检索增强生成)平台实现文档扫描和知识库推荐功能,可以分为以下步骤和技术实现方案:
一、核心流程
- 文档上传与解析
• 用户上传目标文档(PDF/Word/TXT等格式)。
• 使用工具提取文档的原始文本,清理无关格式。 - 文本预处理与分块
• 将文档分割为语义段落(如按句子或段落分块),便于后续检索。
• 可选:对分块文本进行清洗(去停用词、标准化等)。 - 知识库索引构建
• 预处理知识库中的所有文档,生成嵌入向量(Embedding)。
• 使用向量数据库(如FAISS、Annoy)建立索引,支持高效相似度搜索。 - 查询文档嵌入生成
• 将用户上传的文档转换为嵌入向量,作为检索的查询向量。 - 相似度匹配与推荐
• 计算查询向量与知识库文档向量的相似度(如余弦相似度)。
• 按相似度排序,返回Top-N最相关的文档清单。
二、技术选型与工具
| 步骤 | 工具/库 | 说明 |
|---|---|---|
| 文档解析 | PyPDF2 / python-docx / textract | 提取PDF、Word等格式的文本内容 |
| 文本分块 | LangChain RecursiveCharacterTextSplitter | 智能分块,保留语义连贯性 |
| 嵌入模型 | Sentence Transformers | 使用预训练模型(如all-MiniLM-L6-v2)生成文本嵌入 |
| 向量数据库 | FAISS / ChromaDB | 高效存储和检索高维向量 |
| 相似度计算 | FAISS内置相似度搜索 | 基于余弦相似度或欧氏距离的快速最近邻搜索 |
三、代码示例(Python)
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
import numpy as np
# 1. 加载并解析目标文档
def load_and_parse_document(file_path):
loader = PyPDFLoader(file_path)
documents = loader.load()
return documents[0].page_content # 返回纯文本内容
# 2. 分块文本
def split_text(text):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每块500字符
chunk_overlap=50 # 重叠50字符保留上下文
)
return text_splitter.split_text(text)
# 3. 构建知识库索引
def build_knowledge_base_index(documents):
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vector_store = FAISS.from_documents(documents, embeddings)
return vector_store
# 4. 检索相似文档
def retrieve_similar_docs(query_text, vector_store, top_k=5):
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
query_embedding = embeddings.embed_query(query_text)
results = vector_store.similarity_search_with_score(query_embedding, k=top_k)
return results
# 主流程
if __name__ == "__main__":
# 假设知识库文档列表为knowledge_docs
knowledge_docs = ["doc1_content", "doc2_content", ...]
# 构建知识库索引
vector_store = build_knowledge_base_index(knowledge_docs)
# 用户上传文档
uploaded_doc_path = "user_doc.pdf"
uploaded_text = load_and_parse_document(uploaded_doc_path)
# 检索推荐
similar_docs = retrieve_similar_docs(uploaded_text, vector_store)
# 输出结果
print("Top 相关文档:")
for doc, score in similar_docs:
print(f"文档片段: {doc.page_content[:200]}... \n相似度: {score:.4f}")四、优化建议
- 分块策略优化
• 根据文档类型调整chunk_size,技术文档可减小块大小(如300字符),长文章可增大。
• 使用滑动窗口分块保留上下文。 - 索引更新机制
• 定期增量更新知识库索引(新增文档时重新构建部分索引)。 - 混合检索
• 结合关键词检索(BM25)和向量检索,提升召回率。 - 模型选择
• 根据需求选择嵌入模型:轻量级选all-MiniLM-L6-v2,高精度选all-mpnet-base-v2。 - 性能调优
• 使用GPU加速嵌入生成(如faiss-gpu)。
• 对大规模知识库分片存储。
五、扩展场景
- 多格式支持:集成
Apache Tika解析更多文档类型(HTML、PPT等)。 - 结果高亮:在返回文档片段中标注重合关键词。
- API化:封装为REST API,供前端或其他系统调用。